Clear Sky Science · fr
Permettre des dépôts d'acides nucléiques à l'échelle mondiale grâce à une sélection biochimique polyvalente et évolutive à partir d'archives à température ambiante
Pourquoi le stockage de matériel génétique est important
Imaginez pouvoir suivre de nouveaux virus, étudier des maladies rares et préserver l'empreinte génétique d'écosystèmes entiers sans avoir besoin d'alignements de congélateurs énergivores. Aujourd'hui, la plupart des ADN et surtout des ARN fragiles doivent être conservés à des températures très basses, ce qui est coûteux et peu pratique pour de nombreuses cliniques et laboratoires dans le monde. Cet article présente une nouvelle manière de stocker et de rechercher de vastes collections d'échantillons génétiques à température ambiante, tout en permettant de retrouver rapidement les échantillons nécessaires pour les analyses.
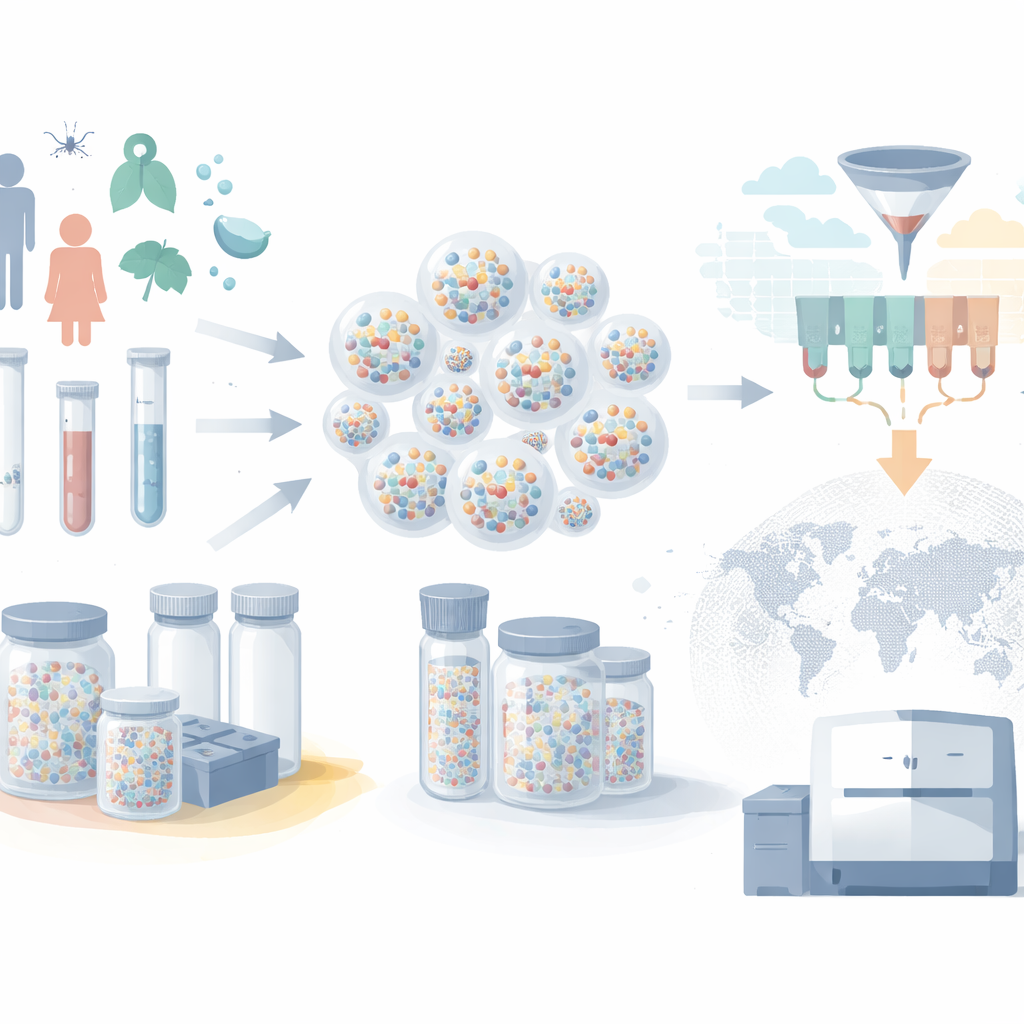
Des fermes de congélateurs à de minuscules capsules
Les biobanques modernes conservent des millions d'échantillons de sang, de salive et de tissus, mais en général chaque échantillon vit dans son propre tube étiqueté à l'intérieur d'un grand congélateur. À mesure que les collections s'agrandissent, cette approche « un tube par échantillon » devient coûteuse et lente. Les congélateurs exigent une alimentation électrique continue, des systèmes robotiques déplacent les échantillons un par un, et l'ARN peut se dégrader si quelque chose tourne mal. Les auteurs utilisent à la place des coques microscopiques en silice — des microcapsules — pour protéger le matériel génétique. L'ADN et l'ARN sont piégés à l'intérieur de ces particules durables, qui restent stables à température ambiante. Plusieurs acides nucléiques différents peuvent être stockés ensemble dans la même capsule, et un très grand nombre de capsules peut être regroupé dans un seul petit tube, réduisant drastiquement l'espace de stockage et les besoins énergétiques.
Transformer des tubes en base de données consultable
Stocker des échantillons n'est que la moitié du problème ; les chercheurs doivent aussi pouvoir extraire le bon sous-ensemble lorsque de nouvelles questions se posent. L'innovation clé de ce travail est un schéma astucieux d'étiquetage qui traite chaque capsule comme un petit enregistrement de base de données. De courts morceaux d'ADN attachés à l'extérieur de chaque capsule servent de « tags » décrivant l'échantillon : par exemple, l'âge du patient, la ville d'origine, le mois et l'année de collecte, le statut vaccinal et si la personne était symptomatique. Plutôt que d'attribuer un tag unique à chaque valeur possible, le système réutilise un ensemble compact de tags et les combine de différentes façons, un peu comme les chiffres qui composent les nombres ou comme des catégories encodées par des combinaisons. Cette conception « consciente du type » permet à de simples opérations physiques sur les tags d'imiter les requêtes de portée et de filtrage puissantes réalisées par les bases de données numériques.
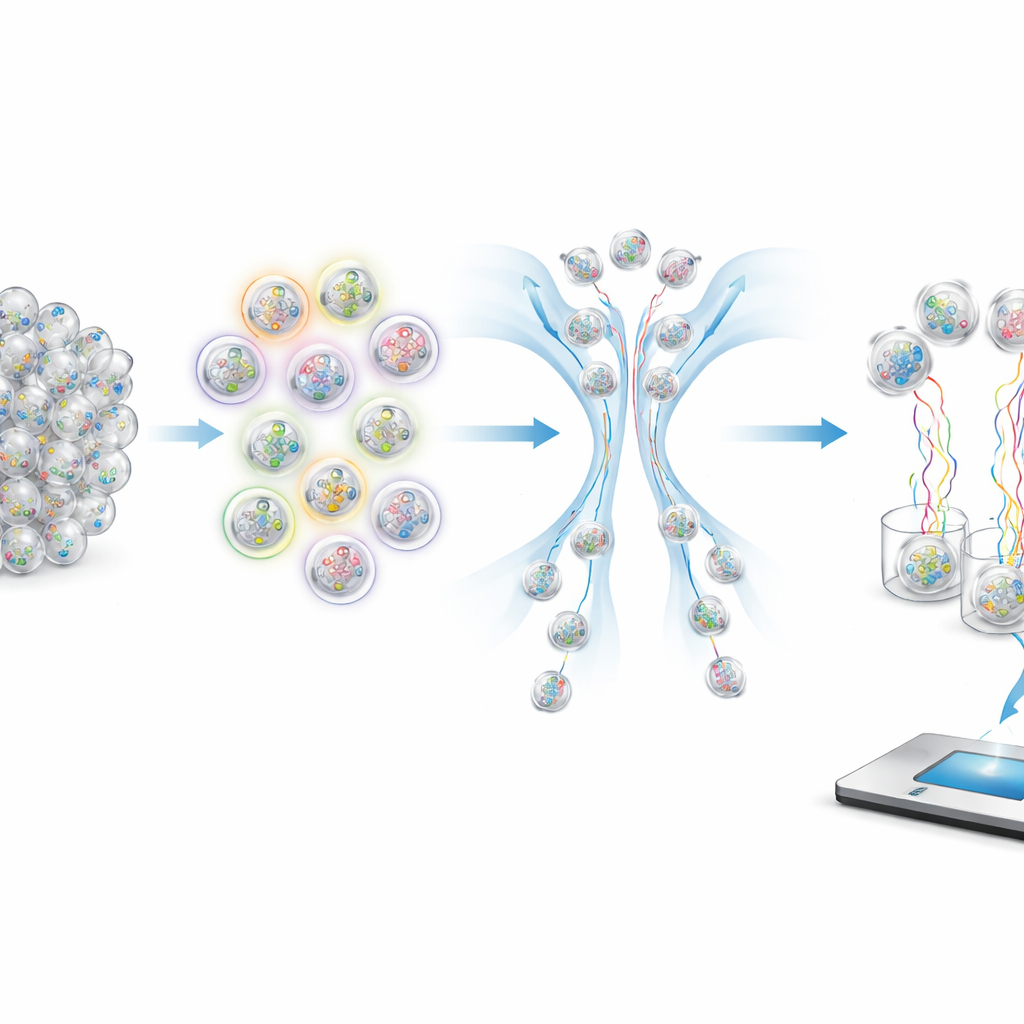
Comment interroger des molécules
Pour récupérer des échantillons spécifiques dans un tube encombré, les auteurs utilisent des sondes fluorescentes qui ne se fixent qu'aux capsules portant des tags correspondants. Ces sondes portent des colorants lisibles par un trieur à flux, qui envoie les capsules fortement lumineuses dans une voie et les capsules peu lumineuses dans une autre. En choisissant quels tags illuminer et comment combiner les couleurs, le système peut implémenter des opérations logiques telles que ET, OU et NON. Par exemple, sélectionner « non symptomatique » signifie rejeter toute capsule qui s'illumine lorsqu'on teste le tag symptomatique. Les plages numériques comme des tranches d'âge ou des intervalles de dates sont gérées en ignorant certains des « chiffres » moins importants de l'âge ou de la date encodés, de sorte qu'une seule requête peut extraire toutes les capsules dont les tags se situent dans une fenêtre choisie.
Tester le système avec une simulation d'épidémie
Pour démontrer que leur approche fonctionne en pratique, les chercheurs ont construit une petite base de données de test réaliste composée de 96 échantillons synthétiques de SARS-CoV-2, modélisés comme s'ils avaient été prélevés sur des passagers aériens arrivant à Boston. Chaque capsule portait des fragments d'ARN viral ainsi qu'un identifiant interne unique et des tags externes encodant des informations fictives sur le patient et le vol. Ils ont ensuite effectué une série de requêtes reflétant l'épidémiologie réelle : trouver tous les passagers asymptomatiques, sélectionner des tranches d'âge spécifiques pour chercher des schémas de variants, et exécuter une requête combinée complexe qui a extrait des passagers d'une ville particulière, pendant certains mois de 2020, qui étaient soit symptomatiques soit non vaccinés. Le séquençage des capsules récupérées a confirmé que les bons échantillons avaient été enrichis avec une très grande précision, même lorsque le groupe désiré ne représentait qu'une fraction de l'ensemble du pool.
Preuve que de vrais échantillons de patients peuvent être préservés
Au-delà des cas de test synthétiques, l'équipe a encapsulé de véritables échantillons de patients infectés par des sous-lignées différentes d'Omicron. Après stockage et récupération, ils ont séquencé les génomes viraux et les ont comparés aux mêmes échantillons qui n'avaient jamais été encapsulés. Malgré des quantités très faibles d'ARN viral, la méthode a néanmoins permis de retrouver les variants corrects, montrant que la protection par silice ne masque pas les différences génétiques subtiles. Parce que les capsules non ciblées peuvent être conservées après chaque recherche, le pool peut être réutilisé à plusieurs reprises, et de simples identifiants internes en ADN permettent des contrôles d'intégrité continus de l'archive, à la manière des vérifications d'intégrité dans le stockage numérique.
Ce que cela signifie pour l'avenir
En termes simples, cette étude montre que les échantillons génétiques peuvent être enfermés dans de minuscules capsules durables, empilés dans un petit volume à température ambiante, puis séparés ultérieurement grâce à des recherches flexibles de type base de données. La méthode réduit drastiquement la dépendance aux congélateurs tout en autorisant des requêtes riches qui peuvent combiner tranches d'âge, lieux, dates et états de santé en une seule opération. À plus grande échelle, de telles archives à température ambiante pourraient soutenir la surveillance mondiale des agents pathogènes, la médecine de précision et même le suivi écologique à long terme dans des régions où l'infrastructure de la chaîne du froid fait défaut. Ce travail ouvre la voie à un futur où l'information biologique mondiale peut être stockée de manière compacte et accessible aussi facilement que des fichiers dans le cloud.
Citation: Berleant, J.D., Banal, J.L., Rao, D.K. et al. Enabling global-scale nucleic acid repositories through versatile, scalable biochemical selection from room-temperature archives. Nat Commun 17, 2807 (2026). https://doi.org/10.1038/s41467-026-69402-3
Mots-clés: stockage d'acides nucléiques, base de données moléculaire, codage ADN, surveillance des agents pathogènes, biobanque à température ambiante