Clear Sky Science · it
Abilitare archivi di acidi nucleici su scala globale tramite una selezione biochimica versatile e scalabile da archivi a temperatura ambiente
Perché è importante conservare materiale genetico
Immaginate di poter tracciare nuovi virus, studiare malattie rare e preservare l’impronta genetica di interi ecosistemi senza avere bisogno di file di congelatori energivori. Oggi la maggior parte del DNA e, in particolare, l’RNA fragile deve essere mantenuta a temperature estremamente basse, cosa costosa e impraticabile per molte cliniche e laboratori nel mondo. Questo articolo presenta un nuovo metodo per conservare e cercare vaste raccolte di campioni genetici a temperatura ambiente, pur essendo in grado di trovare rapidamente solo i campioni che gli scienziati devono analizzare.
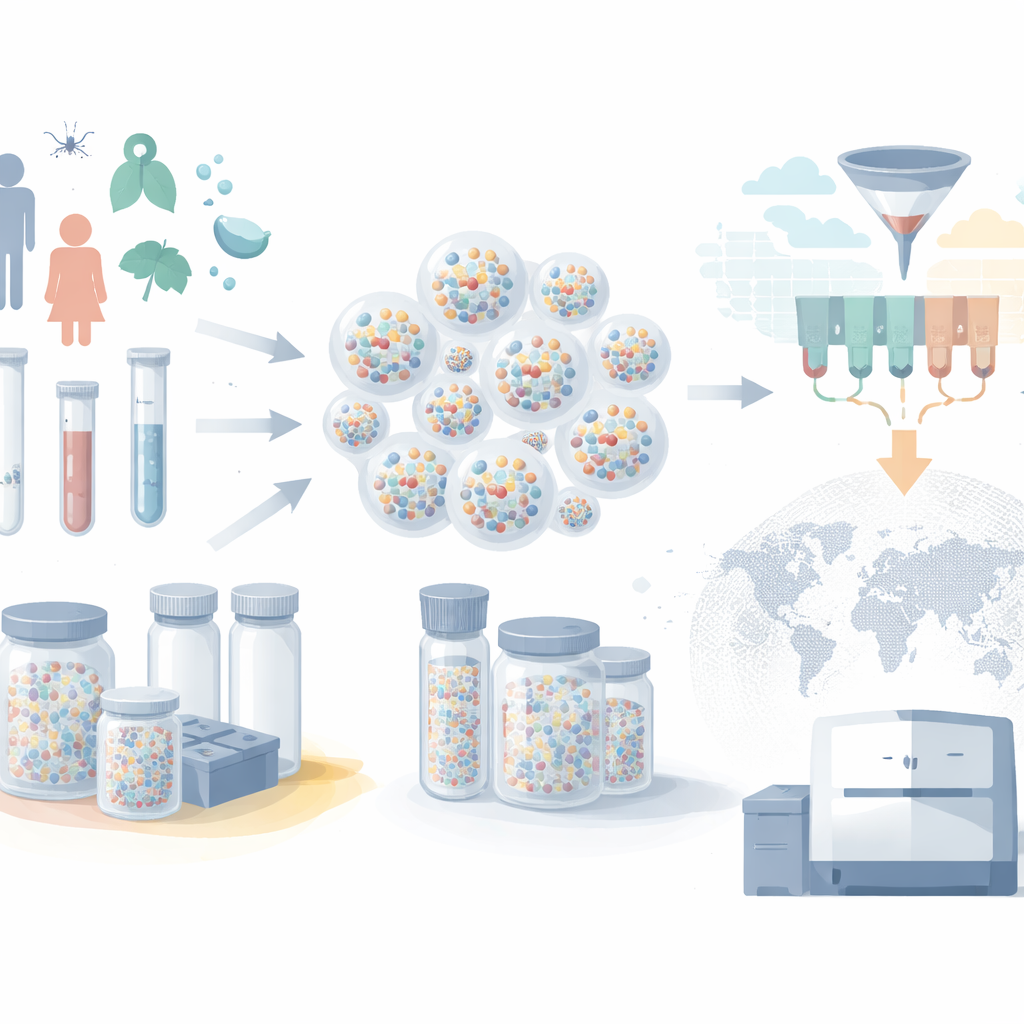
Dalle fattorie di congelatori a minuscole capsule
I biobanche moderne contengono milioni di campioni di sangue, saliva e tessuto, ma tipicamente ogni campione vive nel proprio tubo etichettato all’interno di un grande congelatore. Con l’aumentare delle collezioni, questo approccio “un tubo per campione” diventa costoso e lento. I congelatori richiedono elettricità costante, i sistemi robotici muovono i campioni uno alla volta e l’RNA può degradarsi se qualcosa va storto. Gli autori usano invece gusci microscopici di silice—microcapsule—per proteggere il materiale genetico. DNA e RNA vengono intrappolati all’interno di queste particelle durevoli, che rimangono stabili a temperatura ambiente. Molti acidi nucleici diversi possono essere immagazzinati insieme nella stessa capsula, e un numero enorme di capsule può essere raggruppato in un unico piccolo tubo, riducendo drasticamente spazio di stoccaggio e consumi energetici.
Trasformare i tubi in un database interrogabile
Conservare i campioni è solo metà del problema; i ricercatori devono anche essere in grado di selezionare il sottoinsieme giusto quando sorgono nuove domande. L’innovazione chiave in questo lavoro è uno schema di codifica a barre intelligente che tratta ogni capsula come un piccolo record di database. Brevi sequenze di DNA attaccate all’esterno di ogni capsula fungono da “etichette” che descrivono il campione: per esempio età del paziente, città di provenienza, mese e anno di raccolta, stato di vaccinazione e se la persona era sintomatica. Invece di assegnare un’etichetta unica a ogni possibile valore, il sistema riutilizza un set compatto di etichette e le combina in modi diversi, molto simile a come i numeri sono scritti con le cifre o a come le categorie possono essere codificate usando combinazioni. Questo design “consapevole del tipo” permette a semplici operazioni fisiche sulle etichette di emulare le potenti query di intervallo e filtro che eseguono i database digitali.
Come porre domande alle molecole
Per recuperare campioni specifici da un tubo affollato, gli autori usano sonde fluorescenti che si attaccano solo alle capsule portatrici delle etichette corrispondenti. Queste sonde contengono coloranti che emettono luce e possono essere letti da uno smistatore a flusso, che manda le capsule brillanti lungo una traiettoria e quelle più deboli lungo un’altra. Scegliendo quali etichette illuminare e come combinare i colori, il sistema può implementare operazioni logiche come AND, OR e NOT. Per esempio, selezionare “non sintomatico” significa rifiutare qualsiasi capsula che emetta fluorescenza quando viene testata per l’etichetta sintomatica. Intervalli numerici come fasce d’età o intervalli di date sono gestiti ignorando alcune delle “cifre” meno importanti nell’età o nella data codificata, così una singola query può estrarre tutte le capsule le cui etichette rientrano in una finestra scelta.
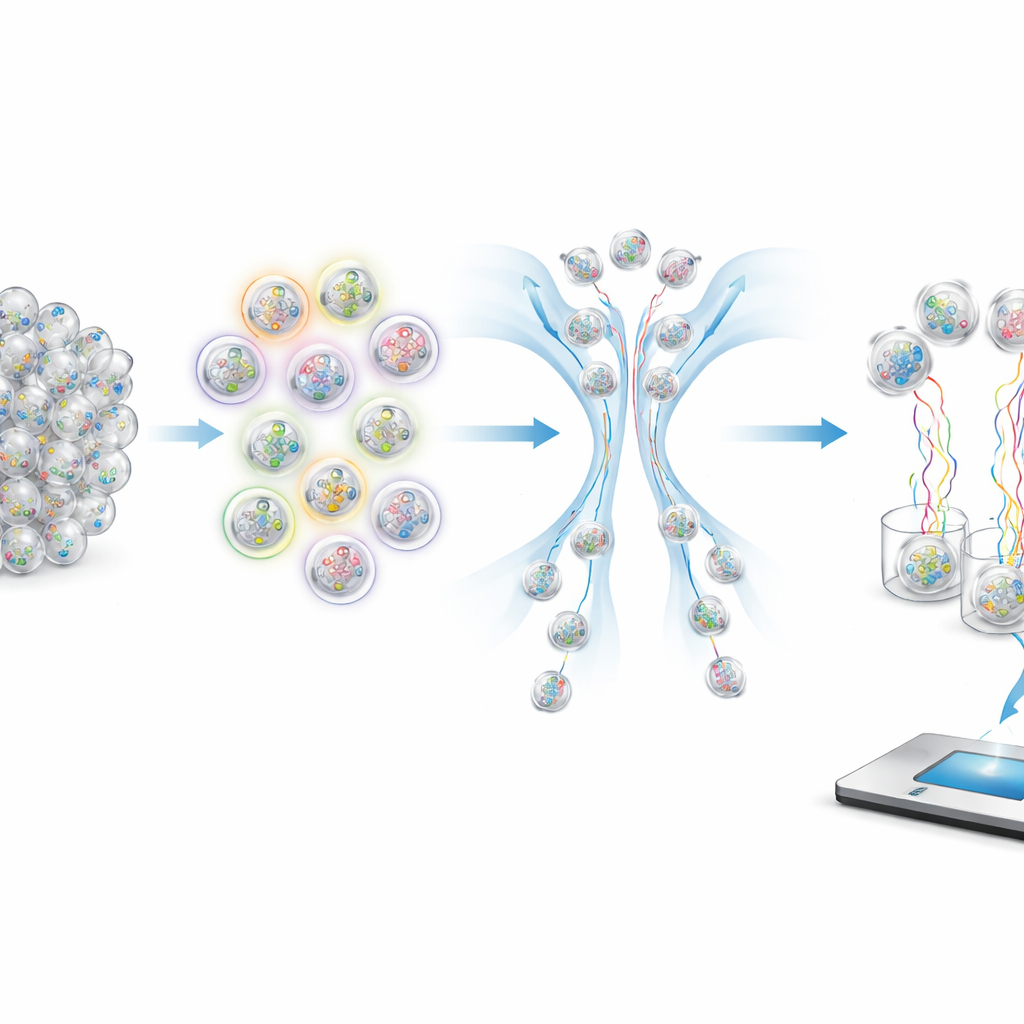
Testare il sistema con un’epidemia simulata
Per dimostrare che l’approccio funziona nella pratica, i ricercatori hanno costruito un piccolo ma realistico database di test con 96 campioni sintetici di SARS-CoV-2, modellati come se fossero stati raccolti da passeggeri aerei in arrivo a Boston. Ogni capsula conteneva frammenti di RNA virale più un identificatore interno unico ed etichette esterne che codificavano informazioni inventate su pazienti e voli. Hanno quindi eseguito una serie di query che rispecchiano scenari epidemiologici reali: trovare tutti i passeggeri asintomatici, selezionare specifiche fasce d’età per cercare pattern di varianti, e lanciare una query combinata complessa che ha estratto passeggeri provenienti da una particolare città, in certi mesi del 2020, che erano o sintomatici o non vaccinati. Il sequenziamento delle capsule recuperate ha confermato che i campioni corretti erano stati arricchiti con altissima accuratezza, anche quando il gruppo desiderato rappresentava solo una frazione dell’intero pool.
Prova che i campioni reali dei pazienti possono essere preservati
Oltre ai casi di test sintetici, il team ha incapsulato campioni veri derivati da pazienti con SARS-CoV-2 portatori di diverse sotto-linee di Omicron. Dopo conservazione e recupero, hanno sequenziato i genomi virali e li hanno confrontati con gli stessi campioni che non erano mai stati incapsulati. Nonostante si lavorasse con quantità molto basse di RNA virale, il metodo ha ancora recuperato le varianti corrette, dimostrando che la protezione in silice non cancella differenze genetiche sottili. Poiché le capsule non target possono essere salvate dopo ogni ricerca, il pool può essere riutilizzato ripetutamente, e semplici identificatori interni di DNA permettono controlli di integrità sull’archivio, analoghi ai controlli di integrità nello storage digitale.
Cosa significa per il futuro
In termini pratici, questo studio mostra che i campioni genetici possono essere confezionati in capsule minuscole e durevoli, ammucchiate in uno spazio ridotto a temperatura ambiente e successivamente separate usando ricerche flessibili simili a quelle di un database. Il metodo riduce drasticamente la dipendenza dai congelatori pur permettendo query ricche che possono combinare fasce d’età, località, date e stati di salute in un’unica operazione. Con un’ulteriore scalabilità, tali archivi a temperatura ambiente potrebbero supportare la sorveglianza globale dei patogeni, la medicina di precisione e persino il monitoraggio ecologico a lungo termine in luoghi dove l’infrastruttura a catena del freddo è scarsa. Il lavoro indica un futuro in cui le informazioni biologiche del mondo possono essere immagazzinate in modo compatto e accessibili con la stessa facilità dei file nel cloud.
Citazione: Berleant, J.D., Banal, J.L., Rao, D.K. et al. Enabling global-scale nucleic acid repositories through versatile, scalable biochemical selection from room-temperature archives. Nat Commun 17, 2807 (2026). https://doi.org/10.1038/s41467-026-69402-3
Parole chiave: conservazione degli acidi nucleici, database molecolare, codifica a barre del DNA, sorveglianza dei patogeni, biobanca a temperatura ambiente