Clear Sky Science · pl
InterFeat: pipeline do wykrywania interesujących cech naukowych
Dlaczego ukryte wzorce w danych medycznych mają znaczenie
Współczesna medycyna gromadzi ogromne ilości informacji o naszym zdrowiu — od badań krwi i tomografii po ankiety dotyczące stylu życia i odczyty genetyczne. W tych danych mogą być ukryte wczesne wskazówki dotyczące tego, kto rozwinie określone choroby i dlaczego, ale wyłapanie naprawdę istotnych wzorców jest trudne i zwykle zależy od ludzkiej intuicji. W pracy tej przedstawiono InterFeat, pipeline komputerowy zaprojektowany, by pomagać naukowcom w automatycznym przeszukiwaniu rozległych zbiorów danych zdrowotnych i wyodrębnianiu krótkiej listy naprawdę interesujących czynników ryzyka, które mogą wskazywać na nowe odkrycia medyczne.
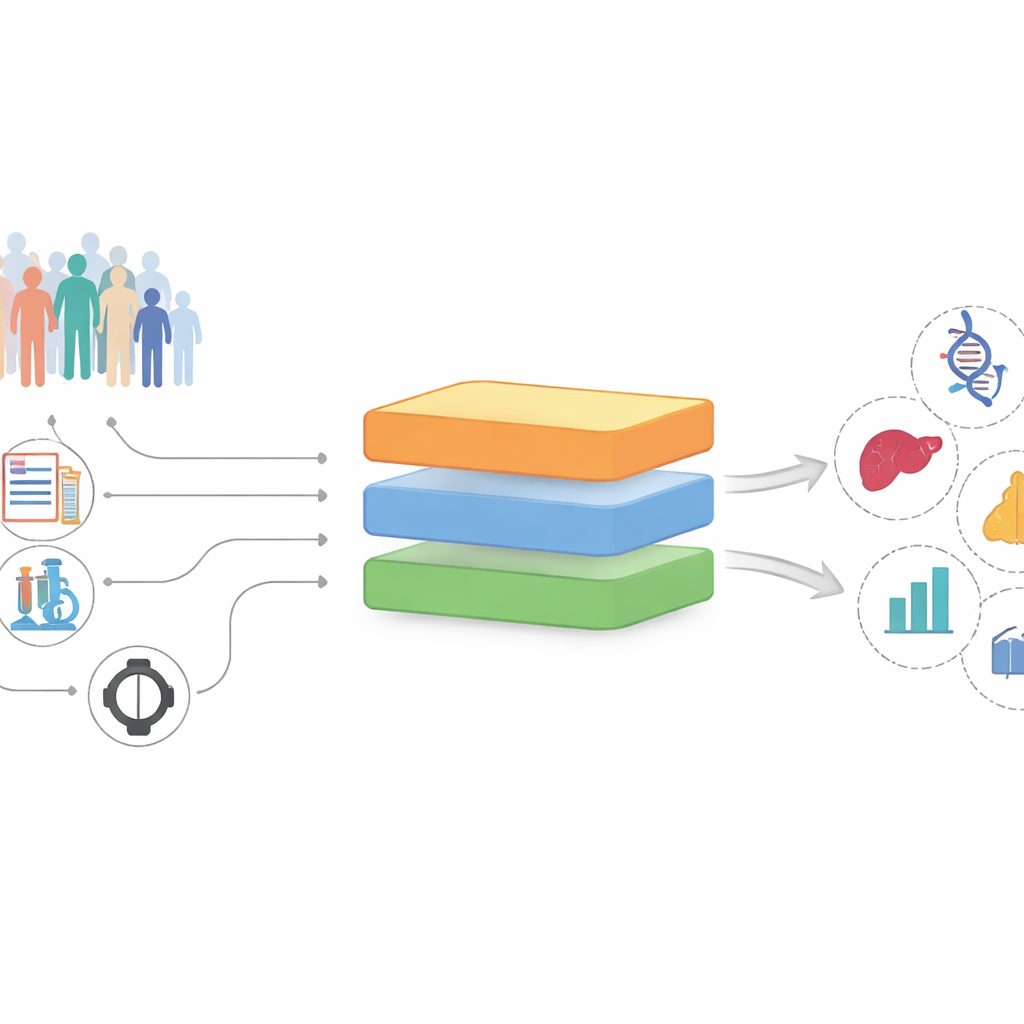
Od nieporządnych zapisów do obiecujących wskazówek
Badacze zbudowali i przetestowali InterFeat na danych UK Biobank, badaniu długoterminowym obejmującym ponad 370 000 dorosłych z tysiącami zmierzonych wielkości na osobę. Każdy pomiar — marker we krwi, lek, wcześniejsza diagnoza, nawyk związany ze stylem życia — traktowany jest jako możliwa „cecha”, która może mieć związek z przyszłą chorobą, taką jak zawał serca, depresja, kamienie żółciowe czy nowotwór. Zamiast pytać jedynie, które cechy dobrze przewidują chorobę, InterFeat stawia trudniejsze pytanie: które cechy są jednocześnie predykcyjne i potencjalnie ujawniają nowe informacje, zamiast powtarzać to, co lekarze już wiedzą?
Co sprawia, że odkrycie jest naprawdę interesujące
Aby sformalizować tę ideę, autorzy dzielą „interesującowość” na trzy składniki. Pierwszy to nowość: związek cecha–choroba nie powinien być już dobrze udokumentowany w literaturze medycznej ani w standardowych bazach referencyjnych. Drugi to użyteczność: cecha powinna rzeczywiście pomagać przewidzieć, kto zachoruje, a nie tylko słabo korelować przypadkowo. Trzeci to wiarygodność: powinna istnieć sensowna wyjaśnialna podstawa, osadzona w obecnej wiedzy biologicznej lub medycznej, dlaczego ta cecha mogłaby wpływać na ryzyko. Ten trójczłonowy pogląd jest istotny, ponieważ wiele efektownych statystycznych powiązań okazuje się być przypadkiem lub odbiciem ukrytych czynników zakłócających, a nie wskazówką nowej biologii.

Jak działa pipeline InterFeat
InterFeat przetwarza tysiące cech w kilku etapach. Najpierw stosuje kontrole statystyczne i z użyciem uczenia maszynowego, aby zachować tylko te cechy, które naprawdę pomagają prognozować chorobę, używając miar takich jak informacja wzajemna i oceny ważności w modelach. Następnie sprawdza, czy para cecha–choroba jest już znana: łączy cechę i chorobę z dużym biomedycznym grafem wiedzy zbudowanym z milionów artykułów naukowych i przeszukuje bazę PubMed, aby zobaczyć, jak często pojawiają się razem. Cechy mocno powiązane z chorobą są usuwane jako „niezaskakujące”, pozostawiając pulę słabiej zbadanych kandydatów.
Wprowadzanie modeli językowych jako literaturowych asystentów
Pozostałe kandydatury są następnie przekazywane dużemu modelowi językowemu, traktowanemu jak zaawansowany czytelnik literatury biomedycznej. Dla każdej pary system automatycznie pobiera odpowiednie streszczenia artykułów i teksty referencyjne, a model językowy używa ich, by ocenić, jak nowatorskie i biologicznie wiarygodne jest dane powiązanie. Pisze też krótkie wyjaśnienie możliwych mechanizmów, takich jak wspólne szlaki zapalne czy efekty niektórych leków. Te oceny łączone są w ogólną ocenę „interesującości”, a badacze otrzymują uszeregowaną, czytelną dla człowieka listę hipotez do dalszego zbadania.
Testowanie systemu na rzeczywistych chorobach
Zespół ocenił InterFeat w kontekście ośmiu głównych chorób, w tym schorzeń rzadkich, jak zakrzepienie żyły siatkówki, oraz powszechnych, jak depresja. Z początkowo około 3700 cech na chorobę pipeline zazwyczaj zawężał listę do mniej niż 80 kandydatów — poniżej 2% pierwotnej listy. Kiedy zasymulowali uruchomienie metody w 2011 roku i następnie prześledzili ewolucję grafu wiedzy medycznej, do 21% cech wskazanych przez InterFeat zostało udokumentowanych w literaturze dopiero kilka lat później, co sugeruje, że pipeline potrafi wydobyć prawdziwe powiązania z wyprzedzeniem. W osobnym teście czterech starszych lekarzy przejrzało 137 komputerowo wybranych cech dla czterech chorób. Ocenili 28% jako interesujące, a wśród najwyżej ocenionych kandydatów z InterFeat 40–53% uznano za interesujące — znacznie lepiej niż proste podejścia polegające jedynie na sortowaniu według ważności statystycznej.
Co to oznacza dla przyszłych odkryć medycznych
InterFeat nie twierdzi, że dowodzi związku przyczynowo-skutkowego, ani nie zastępuje oceny ekspertów. Zamiast tego działa jako inteligentny filtr, który zamienia tysiące możliwych sygnałów w zarządzalną krótką listę wzbogaconą o pomysły nowe, użyteczne do predykcji i biologicznie sensowne. Przykłady obejmują powiązania między długotrwałym stosowaniem antybiotyków w dzieciństwie a zawałami serca w wieku dorosłym, czy też poligeniczne skale ryzyka dla innych schorzeń wykazujące niespodziewane powiązania z rakiem przełyku i kamicą żółciową. Łącząc testy statystyczne, duże grafy wiedzy, przeszukiwanie literatury i modele językowe w jednym konfigurowalnym pipeline, InterFeat oferuje badaczom medycyny — a potencjalnie także innym dziedzinom obfitującym w dane — skalowalny sposób skupienia uwagi na najbardziej obiecujących śladach ukrytych w złożonych zestawach danych.
Cytowanie: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Słowa kluczowe: wydobywanie danych biomedycznych, czynniki ryzyka chorób, grafy wiedzy, uczenie maszynowe w medycynie, generowanie hipotez