Clear Sky Science · es
InterFeat: una canalización para encontrar rasgos científicos interesantes
Por qué importan los patrones ocultos en los datos médicos
La medicina moderna recoge enormes cantidades de información sobre nuestra salud, desde análisis de sangre y exploraciones hasta encuestas de estilo de vida y lecturas genéticas. Enterados en estos datos puede haber pistas tempranas sobre qué personas desarrollarán ciertas enfermedades y por qué, pero detectar los patrones realmente importantes es difícil y suele depender de la intuición humana. Este artículo presenta InterFeat, una canalización informática diseñada para ayudar a los científicos a cribar automáticamente vastos conjuntos de datos de salud y destacar una lista corta de factores de riesgo genuinamente interesantes que pueden apuntar a nuevas ideas médicas.
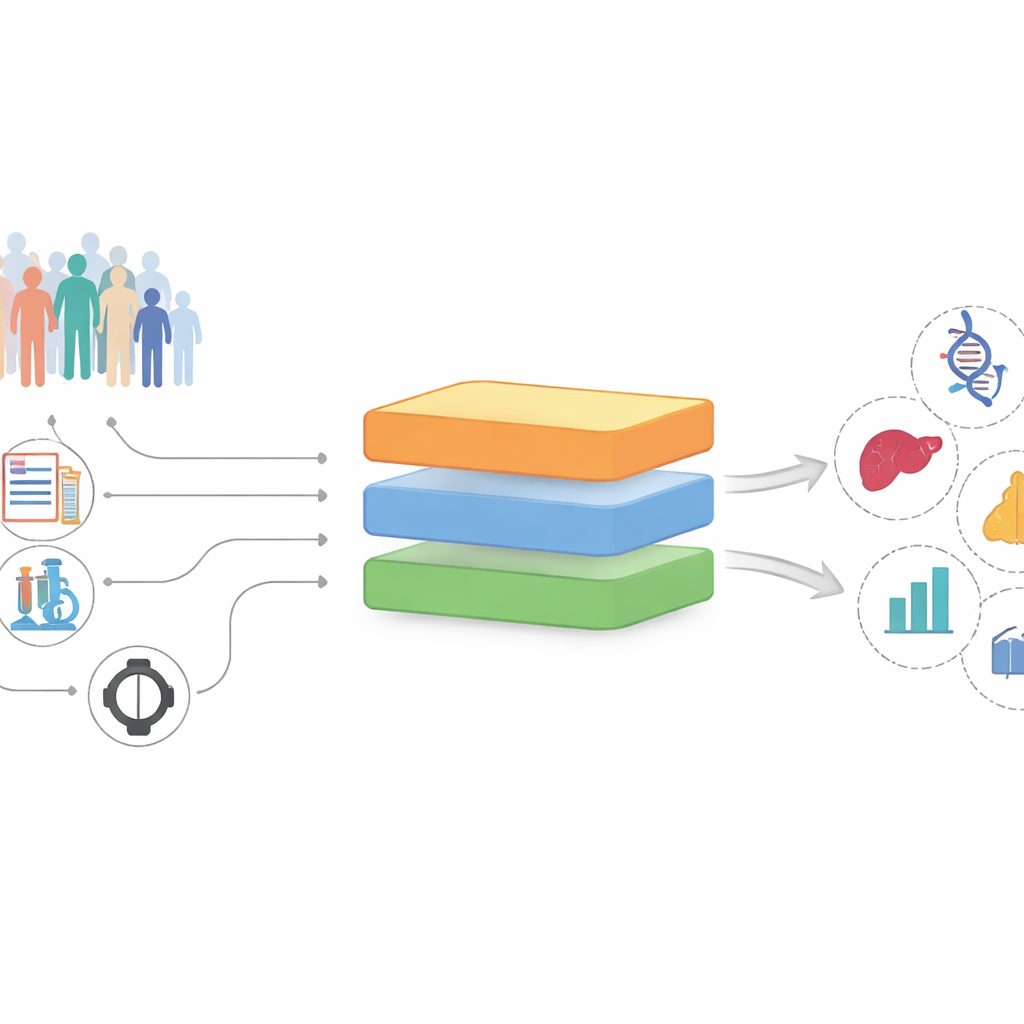
De registros desordenados a pistas prometedoras
Los investigadores construyeron y probaron InterFeat con la UK Biobank, un estudio a largo plazo que sigue a más de 370.000 adultos con miles de mediciones registradas por persona. Cada medición —un marcador sanguíneo, un medicamento, un diagnóstico previo, un hábito de vida— se trata como una posible “característica” que podría relacionarse con una enfermedad futura, como infarto de miocardio, depresión, cálculos biliares o cáncer. En lugar de limitarse a preguntar qué características predicen bien una enfermedad, InterFeat plantea una pregunta más exigente: ¿qué características son a la vez predictivas y potencialmente reveladoras de nuevo conocimiento, en lugar de reiterar lo que los médicos ya saben?
Qué hace que un hallazgo sea realmente interesante
Para formalizar esta idea, los autores descomponen la “interesancia” en tres ingredientes. Primero, novedad: un vínculo característica–enfermedad no debería estar ya bien establecido en la literatura médica o en bases de referencia estándar. Segundo, utilidad: la característica debe ayudar realmente a predecir quién desarrollará la enfermedad, no solo correlacionar débilmente por casualidad. Tercero, plausibilidad: debe existir una explicación sensata, basada en la biología o la medicina actuales, de por qué esa característica podría influir en el riesgo. Esta visión tripartita es importante porque muchos vínculos estadísticos llamativos resultan ser casualidades o reflejos de factores de confusión ocultos en lugar de indicios de nueva biología.

Cómo funciona la canalización InterFeat
InterFeat procesa miles de características en varias etapas. Primero aplica controles estadísticos y de aprendizaje automático para conservar solo las características que realmente ayudan a prever una enfermedad, usando medidas como la información mutua y puntuaciones de importancia basadas en modelos. A continuación, comprueba si el par característica–enfermedad ya es conocido: conecta la característica y la enfermedad con un gran grafo de conocimiento biomédico construido a partir de millones de artículos de investigación, y también busca en la base de datos PubMed para ver con qué frecuencia aparecen juntos. Las características que ya están fuertemente ligadas a la enfermedad se eliminan como “poco sorprendentes”, dejando una bolsa de candidatas poco exploradas.
Incorporando modelos de lenguaje como asistentes expertos en la literatura
Las candidatas restantes se pasan a un modelo de lenguaje a gran escala, tratado como una especie de lector superpotenciado de la literatura biomédica. Para cada par candidato, el sistema recupera automáticamente resúmenes y textos de referencia relevantes, y el modelo de lenguaje los usa para juzgar cuán novedosa y cuán biológicamente plausible parece la conexión. También redacta una breve explicación de posibles mecanismos, como vías inflamatorias compartidas o los efectos de ciertos medicamentos. Estas puntuaciones se combinan en una valoración global de “interesancia”, y los investigadores reciben una lista ordenada y legible por humanos de hipótesis para examinar con más detalle.
Probando el sistema en enfermedades reales
El equipo evaluó InterFeat en ocho enfermedades importantes, incluidas condiciones raras como la oclusión de la vena retiniana y otras comunes como la depresión. Partiendo de aproximadamente 3.700 características por enfermedad, la canalización normalmente redujo el campo a menos de 80 candidatas —menos del 2% de la lista original. Cuando simularon ejecutar el método en 2011 y luego observaron cómo evolucionó el grafo de conocimiento médico, hasta el 21% de las características señaladas por InterFeat solo fueron documentadas en la literatura años después, lo que sugiere que la canalización puede sacar a la luz asociaciones reales con antelación. En una prueba separada, cuatro médicos sénior revisaron 137 características seleccionadas por el ordenador para cuatro enfermedades. Valoraron el 28% como interesantes, y entre las candidatas mejor clasificadas por InterFeat, el 40–53% fueron consideradas interesantes, muy por encima de baselines simples que solo ordenaban por importancia estadística.
Qué significa esto para el descubrimiento médico futuro
InterFeat no afirma demostrar causalidad, ni sustituye el juicio de los expertos. En cambio, actúa como un filtro inteligente que transforma miles de señales posibles en una lista manejable enriquecida con ideas que son nuevas, útiles para la predicción y biológicamente sensatas. Ejemplos incluyen vínculos entre el uso prolongado de antibióticos en la infancia y los infartos en la edad adulta, o puntuaciones de riesgo genético para otras condiciones que muestran conexiones inesperadas con el cáncer de esófago y los cálculos biliares. Al combinar pruebas estadísticas, grandes grafos de conocimiento, búsqueda bibliográfica y modelos de lenguaje en una sola canalización configurable, InterFeat ofrece a los investigadores en medicina —y potencialmente a otros campos ricos en datos— una forma escalable de centrar su atención en las pistas más prometedoras que se esconden en conjuntos de datos complejos.
Cita: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Palabras clave: minería de datos biomédicos, factores de riesgo de enfermedades, grafos de conocimiento, aprendizaje automático en medicina, generación de hipótesis