Clear Sky Science · fr
InterFeat : un pipeline pour repérer des caractéristiques scientifiques intéressantes
Pourquoi les motifs cachés dans les données médicales comptent
La médecine moderne collecte d’énormes quantités d’informations sur notre santé, des analyses sanguines et des images aux enquêtes sur le mode de vie et aux données génétiques. Enfouis dans ces données se trouvent peut‑être des indices précoces sur qui développera certaines maladies et pourquoi, mais repérer les motifs véritablement importants est difficile et dépend souvent de l’intuition humaine. Cet article présente InterFeat, un pipeline informatique conçu pour aider les scientifiques à trier automatiquement d’immenses jeux de données de santé et à mettre en avant une courte liste de facteurs de risque réellement intéressants qui peuvent suggérer de nouveaux éclairages médicaux.
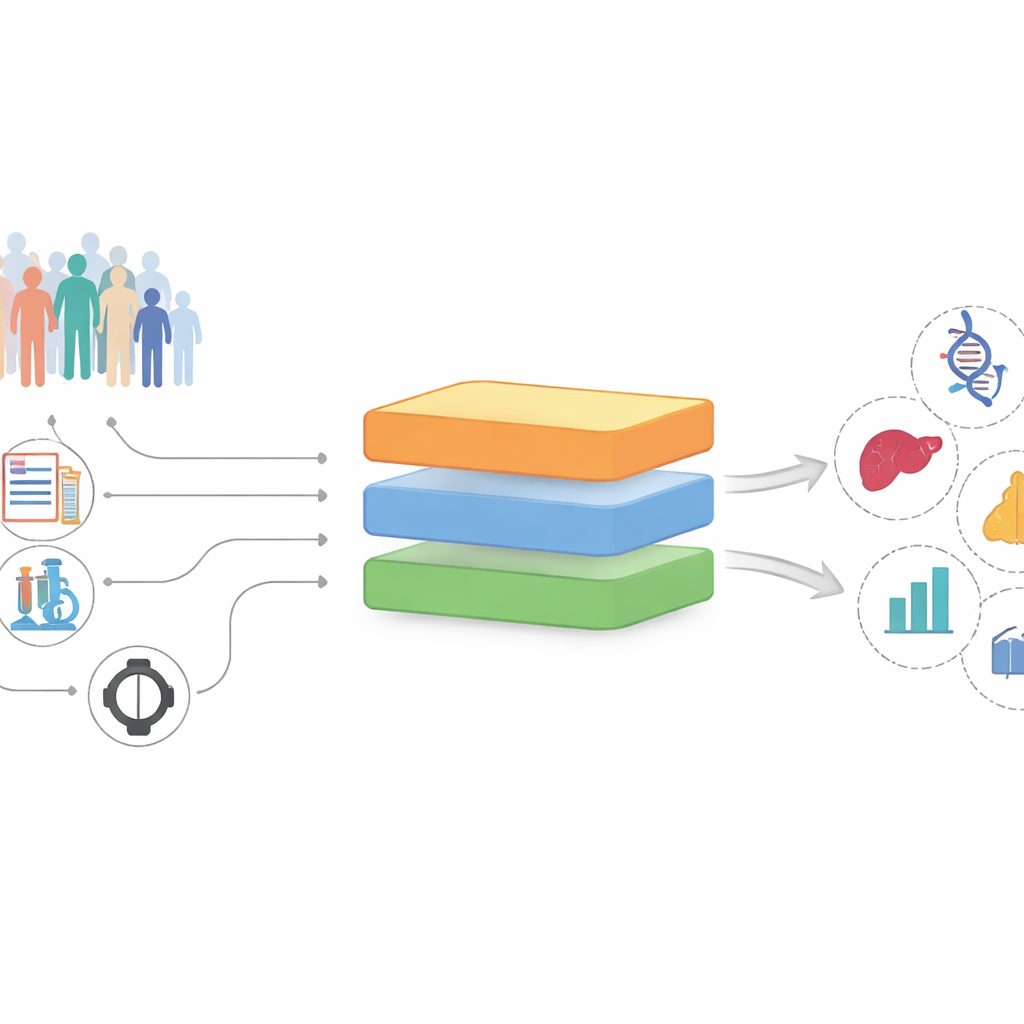
Des dossiers désordonnés aux indices prometteurs
Les auteurs ont construit et testé InterFeat en utilisant l’UK Biobank, une étude à long terme qui suit plus de 370 000 adultes avec des milliers de mesures enregistrées par personne. Chaque mesure — un marqueur sanguin, un médicament, un diagnostic antérieur, une habitude de vie — est traitée comme une possible « caractéristique » susceptible d’être liée à une maladie future, comme un infarctus, une dépression, des calculs biliaires ou un cancer. Plutôt que de simplement demander quelles caractéristiques prédisent bien une maladie, InterFeat pose une question plus exigeante : quelles caractéristiques sont à la fois prédictives et susceptibles d’apporter de nouvelles connaissances, au lieu de reformuler ce que les médecins savent déjà ?
Qu’est‑ce qui rend une découverte vraiment intéressante
Pour formaliser cette idée, les auteurs décomposent « l’intérêt » en trois ingrédients. Le premier est la nouveauté : un lien caractéristique–maladie ne doit pas déjà être bien établi dans la littérature médicale ou les bases de référence standard. Le second est l’utilité : la caractéristique doit réellement aider à prédire qui développera la maladie, et non se contenter d’une corrélation faible due au hasard. Le troisième est la plausibilité : il doit exister une explication raisonnable, fondée sur la biologie ou la médecine actuelles, expliquant pourquoi cette caractéristique pourrait influencer le risque. Cette vision en trois volets est importante parce que de nombreux liens statistiques frappants s’avèrent être des coups de chance ou le reflet de facteurs de confusion cachés plutôt que des indices d’une nouvelle biologie.

Comment fonctionne le pipeline InterFeat
InterFeat traite des milliers de caractéristiques en plusieurs étapes. Il applique d’abord des contrôles statistiques et d’apprentissage automatique pour ne conserver que les caractéristiques qui aident véritablement à prévoir une maladie, en utilisant des mesures comme l’information mutuelle et des scores d’importance basés sur des modèles. Ensuite, il vérifie si la paire caractéristique–maladie est déjà connue : il relie la caractéristique et la maladie à un large graphe de connaissances biomédicales construit à partir de millions d’articles de recherche, et recherche également dans la base PubMed pour voir à quelle fréquence ils apparaissent ensemble. Les caractéristiques déjà fortement liées à la maladie sont retirées comme « non surprenantes », laissant un réservoir de candidats peu explorés.
Intégrer des modèles de langage comme assistants connaisseurs de la littérature
Les candidats restants sont ensuite transmis à un grand modèle de langage, traité comme une sorte de lecteur surpuissant de la littérature biomédicale. Pour chaque paire candidate, le système récupère automatiquement des résumés scientifiques et des textes de référence pertinents, et le modèle de langage les utilise pour juger de la nouveauté et de la plausibilité biologique de la connexion. Il rédige aussi une courte explication des mécanismes possibles, comme des voies inflammatoires partagées ou les effets de certains médicaments. Ces scores sont combinés en une note globale d’« intérêt », et les chercheurs reçoivent une liste hiérarchisée et lisible d’hypothèses à examiner plus avant.
Tester le système sur des maladies réelles
L’équipe a évalué InterFeat sur huit maladies majeures, incluant des affections rares comme l’occlusion de la veine rétinienne et des maladies courantes comme la dépression. À partir d’environ 3 700 caractéristiques par maladie, le pipeline réduisait typiquement le champ à moins de 80 candidats — moins de 2 % de la liste initiale. Lorsqu’ils ont simulé l’exécution de la méthode en 2011 puis examiné l’évolution du graphe de connaissances médicales, jusqu’à 21 % des caractéristiques signalées par InterFeat n’étaient documentées dans la littérature que des années plus tard, suggérant que le pipeline peut faire émerger des associations réelles en avance de phase. Dans un test séparé, quatre médecins seniors ont examiné 137 caractéristiques sélectionnées par l’ordinateur pour quatre maladies. Ils en ont jugé 28 % intéressantes, et parmi les candidats les mieux classés par InterFeat, 40–53 % ont été considérés comme intéressants, bien mieux que des méthodes simples se contentant de trier par importance statistique.
Ce que cela signifie pour la découverte médicale future
InterFeat ne prétend pas prouver la relation de cause à effet, ni remplacer le jugement d’experts. Il agit plutôt comme un filtre intelligent qui transforme des milliers de signaux possibles en une liste restreinte, enrichie en idées nouvelles, utiles pour la prédiction et biologiquement sensées. Parmi les exemples figurent des liens entre l’utilisation prolongée d’antibiotiques durant l’enfance et les infarctus à l’âge adulte, ou des scores de risque génétique pour d’autres affections montrant des connexions inattendues avec le cancer de l’œsophage et les calculs biliaires. En combinant tests statistiques, grands graphes de connaissances, recherche bibliographique et modèles de langage dans un pipeline configurable, InterFeat offre aux chercheurs en médecine — et potentiellement dans d’autres domaines riches en données — une manière évolutive de concentrer leur attention sur les pistes les plus prometteuses cachées dans des ensembles de données complexes.
Citation: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Mots-clés: exploitation de données biomédicales, facteurs de risque de maladie, graphiques de connaissances, apprentissage automatique en médecine, génération d’hypothèses