Clear Sky Science · nl
InterFeat: een pijplijn voor het vinden van interessante wetenschappelijke kenmerken
Waarom verborgen patronen in medische gegevens ertoe doen
De moderne geneeskunde verzamelt enorme hoeveelheden informatie over onze gezondheid, van bloedonderzoeken en scans tot leefstijlvragenlijsten en genetische profielen. Verstopt in deze data kunnen vroege aanwijzingen zitten over wie welke ziekten zal ontwikkelen en waarom, maar het ontdekken van de werkelijk belangrijke patronen is moeilijk en berust vaak op menselijke intuïtie. Dit artikel introduceert InterFeat, een computergestuurde pijplijn ontwikkeld om wetenschappers te helpen automatisch door grote gezondheidsdatasets te zoeken en een korte lijst van echt interessante risicofactoren te markeren die kunnen wijzen op nieuwe medische inzichten.
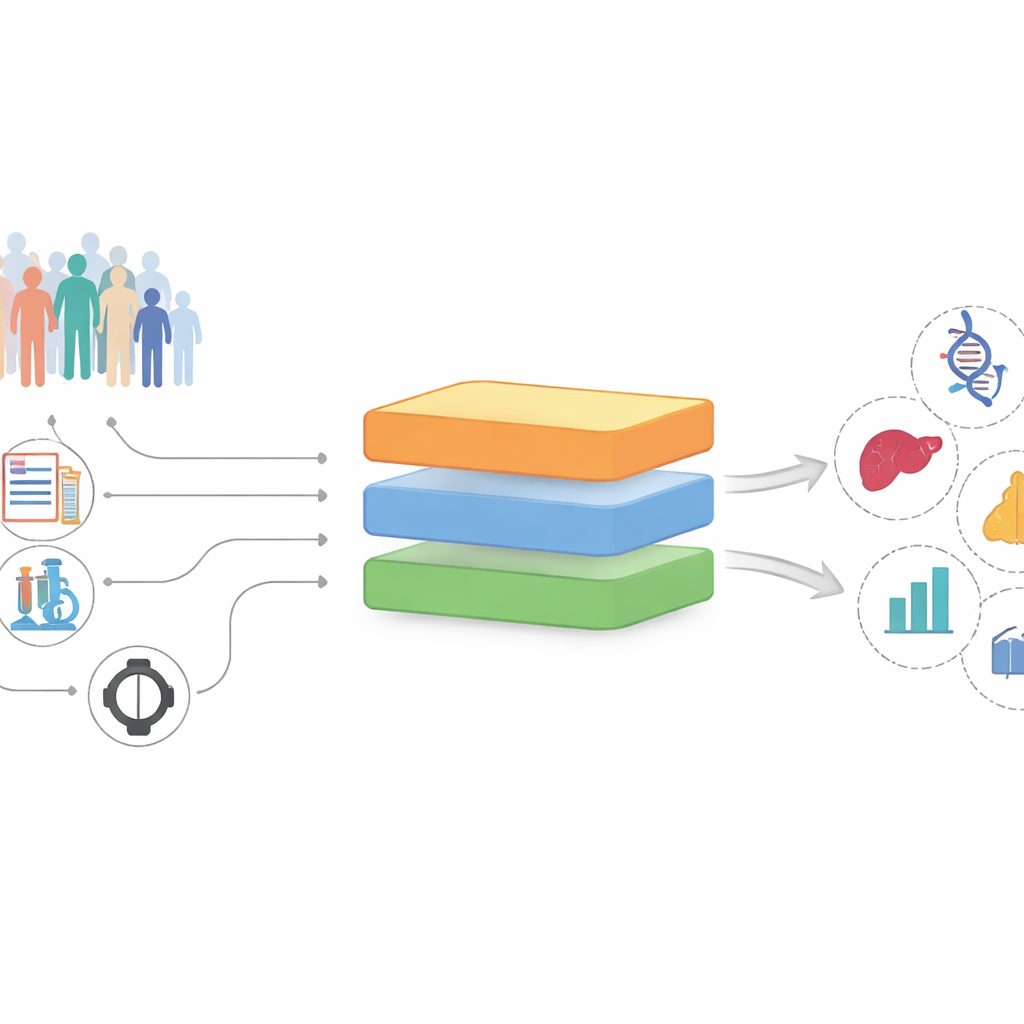
Van rommelige dossiers naar veelbelovende aanwijzingen
De onderzoekers bouwden en testten InterFeat met behulp van de UK Biobank, een langlopend onderzoek waarin meer dan 370.000 volwassenen worden gevolgd met per persoon duizenden vastgelegde metingen. Elke meting – een bloedwaarde, een medicijn, een eerdere diagnose, een leefgewoonte – wordt gezien als een mogelijke “feature” die gerelateerd kan zijn aan een toekomstige ziekte, zoals een hartaanval, depressie, galstenen of kanker. In plaats van alleen te vragen welke kenmerken een ziekte goed voorspellen, stelt InterFeat een meer veeleisende vraag: welke kenmerken zijn zowel voorspellend als mogelijk onthullend voor nieuwe kennis, in plaats van simpelweg te herhalen wat artsen al weten?
Wat een vondst echt interessant maakt
Om dit idee te formaliseren, splitsen de auteurs “interessantheid” in drie ingrediënten. Ten eerste nieuwheid: een kenmerk–ziekteverbinding mag nog niet goed zijn vastgelegd in medische literatuur of standaardreferenties. Ten tweede bruikbaarheid: het kenmerk moet daadwerkelijk helpen voorspellen wie de ziekte zal krijgen, en niet slechts toevallig zwak correleren. Ten derde plausibiliteit: er moet een redelijke verklaring zijn, geworteld in de huidige biologie of geneeskunde, waarom dit kenmerk het risico zou kunnen beïnvloeden. Dit driedelige perspectief is belangrijk omdat veel opvallende statistische verbanden uiteindelijk toeval blijken te zijn of het gevolg van verborgen confounders, en niet aanwijzingen voor nieuwe biologie.

Hoe de InterFeat-pijplijn werkt
InterFeat verwerkt duizenden kenmerken in meerdere stappen. Eerst past het statistische en machine-learning controles toe om alleen die kenmerken over te houden die echt bijdragen aan de voorspelling van een ziekte, met behulp van maatstaven zoals wederzijdse informatie en modelgebaseerde belangrijkheidsscores. Vervolgens controleert het of het kenmerk–ziektepaar al bekend is: het koppelt kenmerk en ziekte aan een grote biomedische kennisgraaf opgebouwd uit miljoenen onderzoeksartikelen, en doorzoekt ook de PubMed-database om te zien hoe vaak ze samen verschijnen. Kenmerken die al sterk aan de ziekte gekoppeld zijn, worden verwijderd als “niet verrassend”, waardoor een groep onderbelichte kandidaten overblijft.
Grote taalmodellen als literatuur-bewuste assistenten
De overgebleven kandidaten worden vervolgens doorgegeven aan een groot taalmodel, benaderd als een soort superlezer van de biomedische literatuur. Voor elk kandidaatpaar haalt het systeem automatisch relevante wetenschappelijke samenvattingen en referentieteksten op, en het taalmodel gebruikt deze om te beoordelen hoe nieuw en hoe biologisch plausibel de verbinding lijkt. Het schrijft ook een korte verklaring van mogelijke mechanismen, zoals gedeelde ontstekingsroutes of effecten van bepaalde medicijnen. Deze scores worden gecombineerd tot een algemene “interessantheids”-beoordeling, en onderzoekers ontvangen een gerangschikte, voor mensen leesbare lijst met hypothesen om verder te onderzoeken.
Het systeem testen op echte ziekten
Het team evalueerde InterFeat op acht belangrijke ziekten, waaronder zeldzame aandoeningen zoals afsluiting van de netvliesslagader en veelvoorkomende zoals depressie. Beginnend bij ongeveer 3.700 kenmerken per ziekte, verkleinde de pijplijn het veld doorgaans tot minder dan 80 kandidaten – minder dan 2% van de oorspronkelijke lijst. Toen ze simuleerden dat de methode in 2011 was gedraaid en vervolgens keken hoe de medische kennisgraaf zich ontwikkelde, bleek tot 21% van de door InterFeat aangeduide kenmerken pas jaren later in de literatuur te zijn gedocumenteerd, wat suggereert dat de pijplijn echte associaties vroegtijdig kan opsporen. In een aparte test beoordeelden vier ervaren artsen 137 door de computer geselecteerde kenmerken voor vier ziekten. Zij vonden 28% interessant, en onder de hoogst gerangschikte kandidaten van InterFeat werden 40–53% als interessant beoordeeld, aanzienlijk beter dan eenvoudige basislijnen die alleen op statistische belangrijkheid sorteerden.
Wat dit betekent voor toekomstige medische ontdekkingen
InterFeat beweert niet oorzaak en gevolg te bewijzen, noch vervangt het deskundig oordeel. In plaats daarvan fungeert het als een intelligente filter die duizenden mogelijke signalen omzet in een hanteerbare shortlist die verrijkt is met ideeën die nieuw zijn, nuttig voor voorspelling en biologisch verstandig. Voorbeelden zijn verbanden tussen langdurig antibioticagebruik in de kinderjaren en hartaanvallen op volwassen leeftijd, of genetische risicoscores voor andere aandoeningen die onverwachte verbanden met slokdarmkanker en galstenen laten zien. Door statistische tests, grote kennisgrafen, literatuurzoektochten en taalmodellen te combineren in één configureerbare pijplijn, biedt InterFeat onderzoekers in de geneeskunde – en mogelijk ook in andere data-rijke vakgebieden – een schaalbare manier om hun aandacht te richten op de veelbelovendste aanwijzingen die verborgen liggen in complexe datasets.
Bronvermelding: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Trefwoorden: biomedische data-analyse, ziekterisicofactoren, kennisgrafen, machine learning in de geneeskunde, hypothesegeneratie