Clear Sky Science · ja
InterFeat: 興味深い科学的特徴を見つけるためのパイプライン
医療データに潜むパターンが重要な理由
現代医療は血液検査やスキャン、生活習慣アンケート、遺伝情報など、私たちの健康に関する膨大な情報を収集しています。このデータの奥深くには、どの人がどの病気を発症するか、そしてその理由についての初期の手がかりが埋もれている可能性がありますが、本当に重要なパターンを見つけるのは難しく、多くの場合は人間の直感に頼ります。本論文はInterFeatを紹介します。これは研究者が膨大な健康データセットを自動でふるいにかけ、医療上の新たな示唆を与える可能性のある短いリストの有望な危険因子を抽出するのを助けるためのコンピュータパイプラインです。
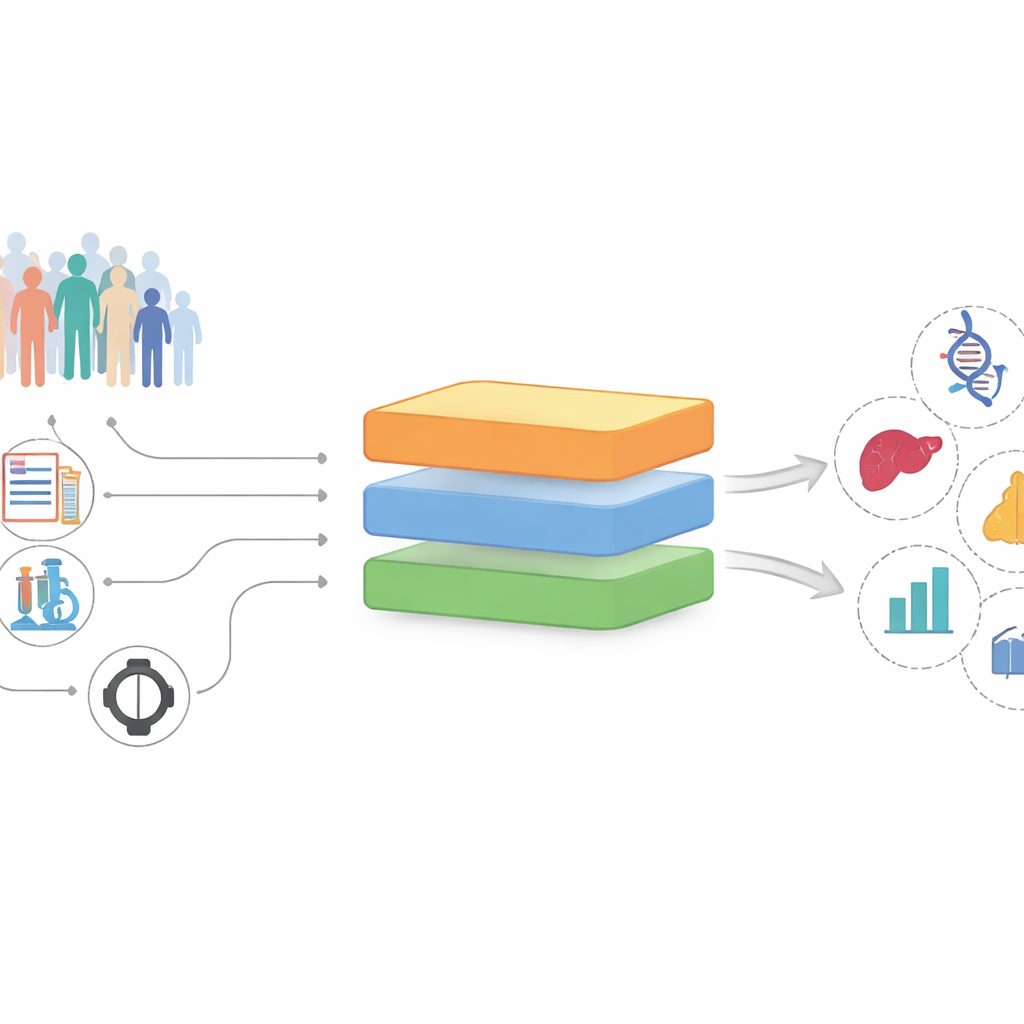
散逸した記録から有望な手がかりへ
研究者らは、各人ごとに何千もの測定値が記録されている長期コホートであるUKバイオバンクを用いてInterFeatを構築・検証しました。各測定値—血液マーカー、薬剤、既往診断、生活習慣など—は、将来の疾患(心臓発作、うつ病、胆石、がんなど)と関連するかもしれない“特徴”として扱われます。InterFeatは単にどの特徴が疾患をよく予測するかを問うのではなく、より厳密な問いを立てます。すなわち、既知の医療知見を繰り返すだけでなく、予測力がありかつ新しい知見を示唆する特徴はどれか、という点です。
本当に興味深い発見とは何か
この考え方を形式化するために、著者らは「興味深さ」を三つの要素に分解します。第一は新規性:特徴と疾患の結びつきが医療文献や標準的な参照データベースですでに確立されていないこと。第二は有用性:特徴が単なる偶然の弱い相関ではなく、実際に誰が疾患を発症するかを予測するのに役立つこと。第三は妥当性:その特徴がリスクに影響を与える理由について、現行の生物学や医学に根ざしたもっともらしい説明が存在すること。この三要素の視点は、多くの統計的に目を引く関連がめったに再現されず、隠れた交絡要因の反映であることが多い点を踏まえると重要です。

InterFeatパイプラインの仕組み
InterFeatは数千の特徴をいくつかの段階で処理します。まず統計的および機械学習ベースのチェックを適用し、相互情報量やモデルに基づく重要度スコアなどの指標を用いて、実際に疾患予測に寄与する特徴だけを残します。次に、その特徴–疾患ペアがすでに知られているかどうかを確認します。特徴と疾患を何百万もの研究論文から構築された大規模なバイオメディカル・ナレッジグラフに結び付け、さらにPubMedを検索して両者がどの程度共出現するかを調べます。疾患と強く結び付いて既知と判断された特徴は「驚きがない」として除外され、十分に探究されていない候補群が残ります。
文献に精通したアシスタントとして言語モデルを取り込む
残った候補は大型言語モデルに渡され、バイオメディカル文献の高度な読者として扱われます。各候補ペアについて、システムは関連する科学的要旨や参照文献を自動的に取得し、言語モデルはそれらを用いて結びつきの新規性や生物学的妥当性を評価します。また、共有する炎症経路や特定の薬剤の影響など、考え得るメカニズムの短い説明も生成します。これらのスコアは総合的な「興味深さ」評価に統合され、研究者には検討用にランク付けされた人間の読みやすい仮説リストが提供されます。
実際の疾患でシステムを検証する
チームは網膜静脈閉塞のような希少疾患からうつ病のような一般的な疾患を含む8つの主要疾患でInterFeatを評価しました。各疾患ごとにおよそ3,700の特徴から出発し、パイプラインは通常80未満の候補に絞り込みました—元のリストの2%未満です。2011年時点で手法をシミュレートし、その後ナレッジグラフがどのように発展したかを調べると、InterFeatが指摘した特徴のうち最大21%が文献に記載されるのは数年後であり、パイプラインが先行して真の関連を浮上させる可能性が示唆されました。別のテストでは、4人のシニア医師が4疾患についてコンピュータ選択の137特徴を検討しました。彼らは28%を興味深いと評価し、InterFeatで上位にランクされた候補のうち40–53%が興味深いと判断され、単に統計的重要度でソートするような簡易なベースラインよりもはるかに良好でした。
将来の医学的発見にとっての意味
InterFeatは因果を証明することを主張するものでも、専門家の判断に取って代わるものでもありません。むしろ、数千の可能なシグナルを新規性が高く、予測に有用で、生物学的に妥当なアイデアに富んだ扱いやすいショートリストに変える知的フィルターとして機能します。例としては、幼少期の長期的な抗生物質使用と成人の心筋梗塞との関連、あるいは他の疾患に対する遺伝的リスクスコアが食道がんや胆石と予期せぬ関連を示す事例などがあります。統計的検定、大規模ナレッジグラフ、文献検索、言語モデルを一つの設定可能なパイプラインに組み合わせることで、InterFeatは医学や他のデータ豊富な分野の研究者に対し、複雑なデータセットに潜む最も有望な手がかりに注意を集中させるためのスケーラブルな方法を提供します。
引用: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
キーワード: バイオメディカルデータマイニング, 疾患の危険因子, ナレッジグラフ, 医学における機械学習, 仮説生成