Clear Sky Science · en
InterFeat: a pipeline for finding interesting scientific features
Why hidden patterns in medical data matter
Modern medicine collects enormous amounts of information about our health, from blood tests and scans to lifestyle surveys and genetic readouts. Buried in this data may be early clues about which people will develop certain diseases and why, but spotting the truly important patterns is hard and usually depends on human intuition. This paper introduces InterFeat, a computer pipeline designed to help scientists automatically sift through vast health datasets and highlight a short list of genuinely interesting risk factors that may hint at new medical insights.
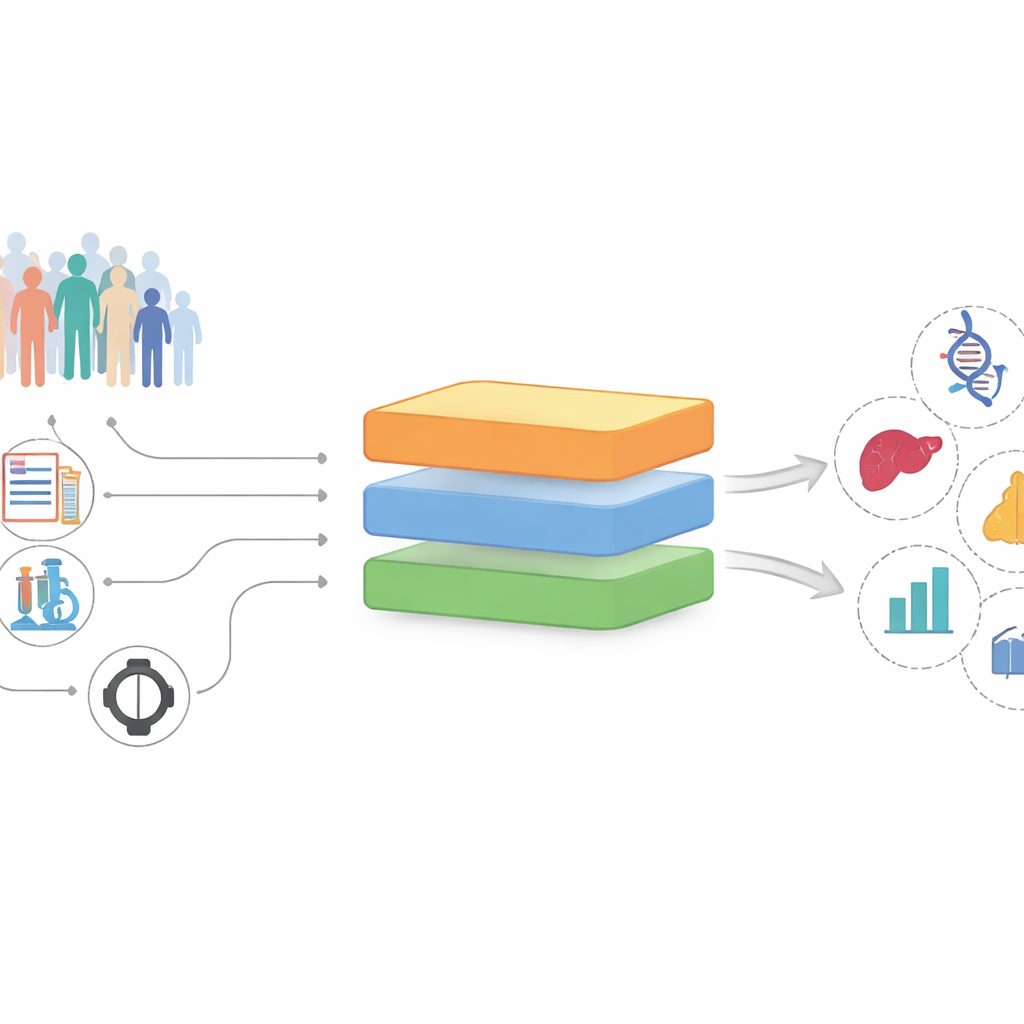
From messy records to promising clues
The researchers built and tested InterFeat using the UK Biobank, a long-term study that follows more than 370,000 adults with thousands of recorded measurements per person. Each measurement – a blood marker, a medication, a previous diagnosis, a lifestyle habit – is treated as a possible “feature” that might relate to a future disease, such as heart attack, depression, gallstones, or cancer. Rather than simply asking which features predict a disease well, InterFeat asks a more demanding question: which features are both predictive and potentially revealing new knowledge, rather than restating what doctors already know?
What makes a finding truly interesting
To formalize this idea, the authors break “interestingness” into three ingredients. First is novelty: a feature–disease link should not already be well established in medical literature or standard reference databases. Second is utility: the feature should actually help predict who will develop the disease, not just correlate weakly by chance. Third is plausibility: there should be a sensible explanation, grounded in current biology or medicine, for why this feature might influence risk. This three-part view is important because many striking statistical links turn out to be flukes or reflections of hidden confounding factors rather than hints of new biology.

How the InterFeat pipeline works
InterFeat processes thousands of features in several stages. It first applies statistical and machine-learning checks to keep only features that truly help forecast a disease, using measures like mutual information and model-based importance scores. Next, it asks whether the feature–disease pair is already known: it connects the feature and disease to a large biomedical knowledge graph built from millions of research papers, and also searches the PubMed database to see how often they appear together. Features that are already strongly linked to the disease are removed as “unsurprising,” leaving a pool of under-explored candidates.
Bringing in language models as literature-savvy assistants
The remaining candidates are then passed to a large language model, treated as a kind of supercharged reader of the biomedical literature. For each candidate pair, the system automatically retrieves relevant scientific abstracts and reference texts, and the language model uses them to judge how novel and how biologically plausible the connection seems. It also writes a short explanation of possible mechanisms, such as shared inflammatory pathways or the effects of certain medications. These scores are combined into an overall “interestingness” rating, and researchers receive a ranked, human-readable list of hypotheses to examine further.
Testing the system on real diseases
The team evaluated InterFeat across eight major diseases, including rare conditions like retinal vein occlusion and common ones like depression. Starting from roughly 3,700 features per disease, the pipeline typically narrowed the field to fewer than 80 candidates – under 2% of the original list. When they simulated running the method in 2011 and then looked at how the medical knowledge graph evolved, up to 21% of the features flagged by InterFeat were only documented in the literature years later, suggesting the pipeline can surface true associations ahead of time. In a separate test, four senior physicians reviewed 137 computer-selected features for four diseases. They rated 28% as interesting, and among the highest-ranked candidates from InterFeat, 40–53% were judged interesting, far better than simple baselines that just sorted by statistical importance.
What this means for future medical discovery
InterFeat does not claim to prove cause and effect, nor does it replace expert judgment. Instead, it acts as an intelligent filter that turns thousands of possible signals into a manageable shortlist enriched for ideas that are new, useful for prediction, and biologically sensible. Examples include links between long-term childhood antibiotic use and adult heart attacks, or genetic risk scores for other conditions showing unexpected connections to esophageal cancer and gallstones. By combining statistical tests, large knowledge graphs, literature search, and language models into one configurable pipeline, InterFeat offers researchers in medicine – and potentially other data-rich fields – a scalable way to focus their attention on the most promising leads hiding in complex datasets.
Citation: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Keywords: biomedical data mining, disease risk factors, knowledge graphs, machine learning in medicine, hypothesis generation