Clear Sky Science · de
InterFeat: eine Pipeline zur Auffindung interessanter wissenschaftlicher Merkmale
Warum verborgene Muster in medizinischen Daten wichtig sind
Die moderne Medizin sammelt enorme Mengen an Informationen über unsere Gesundheit – von Bluttests und Bildgebungen bis zu Lebensstilbefragungen und genetischen Messungen. In diesen Daten können frühe Hinweise darauf verborgen sein, welche Personen bestimmte Krankheiten entwickeln werden und warum, doch es ist schwierig, die wirklich wichtigen Muster zu erkennen; oft hängt das von menschlicher Intuition ab. Dieses Papier stellt InterFeat vor, eine Computer-Pipeline, die Wissenschaftlern helfen soll, automatisch riesige Gesundheitsdatensätze zu durchsuchen und eine kurze Liste von tatsächlich interessanten Risikofaktoren hervorzuheben, die auf neue medizinische Einsichten hindeuten könnten.
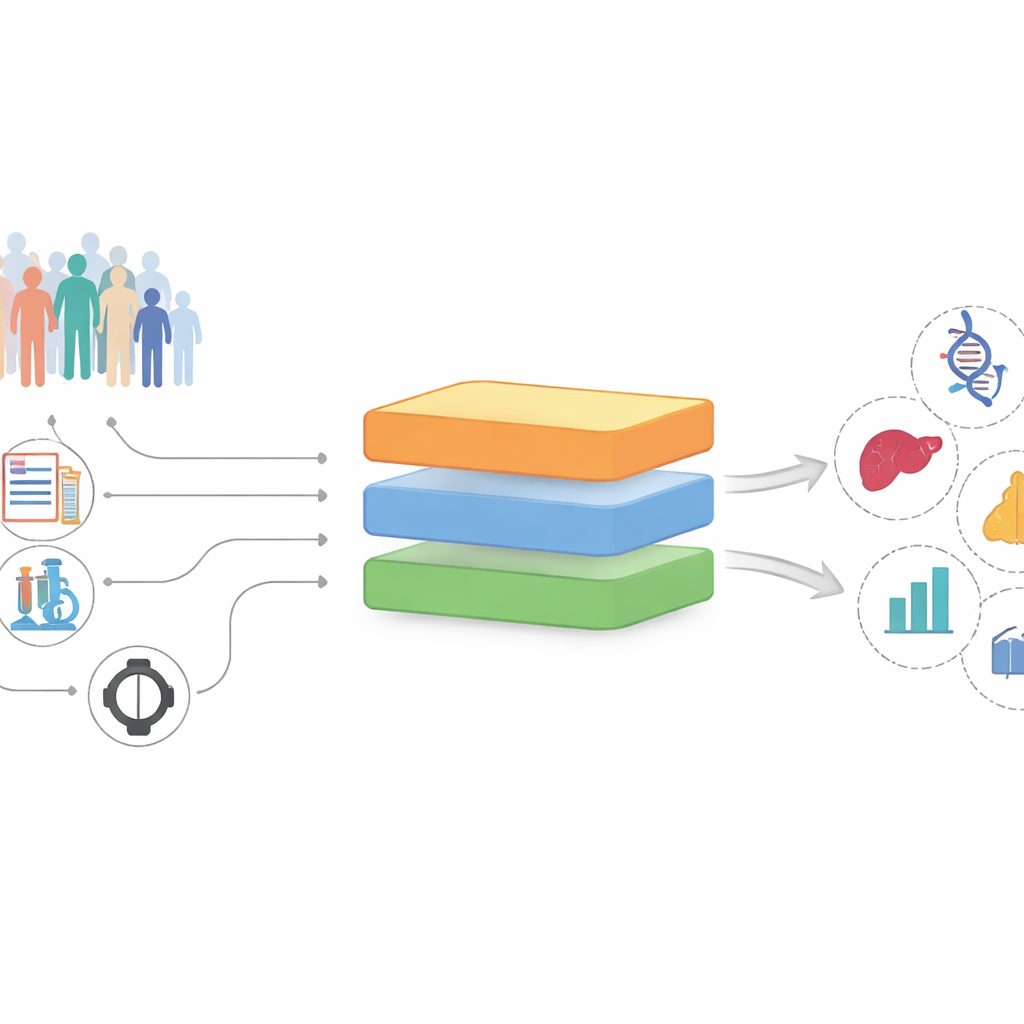
Von unordentlichen Aufzeichnungen zu vielversprechenden Hinweisen
Die Forschenden entwickelten und testeten InterFeat anhand der UK Biobank, einer Langzeitstudie, die mehr als 370.000 Erwachsene begleitet und bei jeder Person Tausende von Messwerten erfasst. Jede Messung – ein Blutwert, ein Medikament, eine frühere Diagnose, eine Lebensgewohnheit – wird als mögliches „Feature“ behandelt, das mit einer zukünftigen Erkrankung wie Herzinfarkt, Depression, Gallensteinen oder Krebs in Verbindung stehen könnte. Anstatt nur zu fragen, welche Merkmale eine Krankheit gut vorhersagen, stellt InterFeat eine anspruchsvollere Frage: Welche Merkmale sind sowohl prädiktiv als auch potenziell wissensbereichernd, statt lediglich Bekanntes aus der ärztlichen Praxis zu wiederholen?
Was eine Entdeckung wirklich interessant macht
Um diese Idee zu formalisieren, teilen die Autoren die „Interessantheit" in drei Bestandteile auf. Zuerst Neuheit: Eine Merkmal–Krankheits-Verbindung sollte in der medizinischen Literatur oder in standardmäßigen Referenzdatenbanken nicht bereits gut etabliert sein. Zweitens Nützlichkeit: Das Merkmal sollte tatsächlich helfen vorherzusagen, wer die Krankheit entwickelt, und nicht nur zufällig schwach korrelieren. Drittens Plausibilität: Es sollte eine sinnvolle Erklärung geben, die auf aktueller Biologie oder Medizin basiert, warum dieses Merkmal das Risiko beeinflussen könnte. Diese Dreiteilung ist wichtig, weil viele auffällige statistische Zusammenhänge sich als Zufallstreffer oder als Spiegelung versteckter Störfaktoren erweisen, statt auf neue biologische Mechanismen hinzuweisen.

Wie die InterFeat-Pipeline funktioniert
InterFeat verarbeitet Tausende von Merkmalen in mehreren Stufen. Zuerst wendet sie statistische und maschinelle Lernprüfungen an, um nur jene Merkmale zu behalten, die tatsächlich zur Vorhersage einer Krankheit beitragen, unter Verwendung von Maßen wie Mutual Information und modellbasierten Wichtigkeitsscores. Anschließend prüft sie, ob das Merkmal–Krankheits-Paar bereits bekannt ist: Sie verbindet Merkmal und Krankheit mit einem großen biomedizinischen Wissensgraphen, der aus Millionen von Forschungsartikeln aufgebaut wurde, und durchsucht zudem die PubMed-Datenbank, um zu sehen, wie oft sie gemeinsam auftreten. Merkmale, die bereits stark mit der Krankheit verknüpft sind, werden als „nicht überraschend" entfernt, sodass ein Pool untererforschter Kandidaten verbleibt.
Sprachemodelle als literaturkundige Assistenten einbeziehen
Die verbleibenden Kandidaten werden anschließend an ein großes Sprachmodell übergeben, das als eine Art leistungsfähiger Leser der biomedizinischen Literatur fungiert. Für jedes Kandidatenpaar ruft das System automatisch relevante wissenschaftliche Abstracts und Referenztexte ab, und das Sprachmodell nutzt diese, um einzuschätzen, wie neu und wie biologisch plausibel die Verbindung erscheint. Es verfasst außerdem eine kurze Erklärung möglicher Mechanismen, etwa gemeinsame entzündliche Signalwege oder die Auswirkungen bestimmter Medikamente. Diese Bewertungen werden zu einer Gesamtbewertung der „Interessantheit" kombiniert, und die Forschenden erhalten eine gereihte, für Menschen lesbare Liste von Hypothesen zur weiteren Prüfung.
Test des Systems an realen Krankheiten
Das Team bewertete InterFeat für acht wichtige Krankheiten, darunter seltene Erkrankungen wie Verschluss von Netzhautvenen und häufige wie Depression. Ausgehend von etwa 3.700 Merkmalen pro Krankheit reduzierte die Pipeline das Feld typischerweise auf weniger als 80 Kandidaten – unter 2 % der ursprünglichen Liste. Als sie simulierten, die Methode im Jahr 2011 anzuwenden und dann beobachteten, wie sich der medizinische Wissensgraph weiterentwickelte, waren bis zu 21 % der von InterFeat markierten Merkmale erst Jahre später in der Literatur dokumentiert worden, was darauf hindeutet, dass die Pipeline wahre Assoziationen frühzeitig erkennen kann. In einem separaten Test bewerteten vier erfahrene Ärztinnen und Ärzte 137 computerselektierte Merkmale für vier Krankheiten. Sie stuften 28 % als interessant ein; unter den am höchsten gerankten Kandidaten von InterFeat wurden 40–53 % als interessant beurteilt – deutlich besser als einfache Baselines, die lediglich nach statistischer Wichtigkeit sortierten.
Was das für künftige medizinische Entdeckungen bedeutet
InterFeat beansprucht nicht, Ursache und Wirkung zu beweisen, und ersetzt nicht das fachliche Urteil. Stattdessen fungiert es als intelligenter Filter, der Tausende möglicher Signale in eine handhabbare Shortlist verwandelt, die an Ideen angereichert ist, die neu, für Vorhersagen nützlich und biologisch sinnvoll sind. Beispiele beinhalten Zusammenhänge zwischen langfristiger Antibiotikagabe in der Kindheit und Herzinfarkten im Erwachsenenalter oder genetische Risikoscores für andere Erkrankungen, die unerwartete Verknüpfungen zu Speiseröhrenkrebs und Gallensteinen zeigen. Indem es statistische Tests, große Wissensgraphen, Literatursuche und Sprachmodelle zu einer konfigurierbaren Pipeline kombiniert, bietet InterFeat Forschenden in der Medizin – und potenziell auch in anderen datenreichen Bereichen – eine skalierbare Methode, um ihre Aufmerksamkeit auf die vielversprechendsten Hinweise in komplexen Datensätzen zu lenken.
Zitation: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Schlüsselwörter: biomedizinische Datenanalyse, Krankheitsrisikofaktoren, Wissensgraphen, Maschinelles Lernen in der Medizin, Hypothesengenerierung