Clear Sky Science · it
InterFeat: una pipeline per trovare caratteristiche scientifiche interessanti
Perché contano i pattern nascosti nei dati medici
La medicina moderna raccoglie enormi quantità di informazioni sulla nostra salute, dagli esami del sangue e dalle scansioni ai questionari sullo stile di vita e ai profili genetici. Sepolti in questi dati possono esserci indizi precoci su quali persone svilupperanno determinate malattie e perché, ma individuare i pattern veramente importanti è difficile e di solito dipende dall’intuizione umana. Questo articolo presenta InterFeat, una pipeline informatica progettata per aiutare gli scienziati a setacciare automaticamente vasti dataset di salute e mettere in evidenza una breve lista di fattori di rischio realmente interessanti che potrebbero suggerire nuove intuizioni mediche.
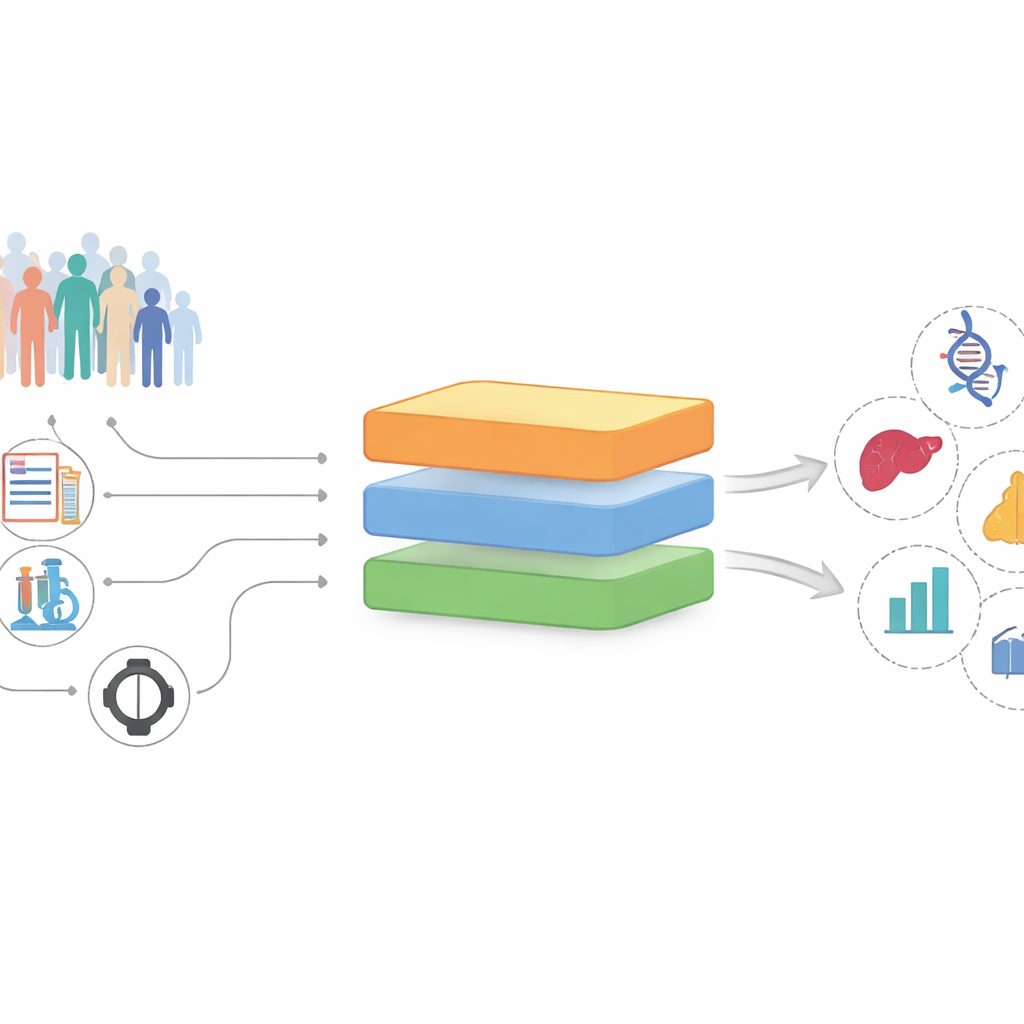
Dai record disordinati a indizi promettenti
I ricercatori hanno costruito e testato InterFeat usando l’UK Biobank, uno studio a lungo termine che segue più di 370.000 adulti con migliaia di misurazioni registrate per ciascuno. Ogni misura – un marcatore ematico, un farmaco, una diagnosi pregressa, un’abitudine di vita – è trattata come una possibile “feature” che potrebbe essere collegata a una malattia futura, come infarto, depressione, calcoli biliari o cancro. Piuttosto che limitarsi a chiedere quali feature predicono bene una malattia, InterFeat pone una domanda più esigente: quali feature sono sia predittive sia potenzialmente in grado di rivelare nuova conoscenza, invece di ribadire ciò che i medici già sanno?
Cosa rende una scoperta veramente interessante
Per formalizzare questa idea, gli autori suddividono l’“interessante” in tre ingredienti. Il primo è la novità: un legame feature–malattia non dovrebbe essere già ben consolidato nella letteratura medica o nei database di riferimento standard. Il secondo è l’utilità: la feature dovrebbe effettivamente aiutare a prevedere chi svilupperà la malattia, non limitarsi a correlare debolmente per caso. Il terzo è la plausibilità: dovrebbe esserci una spiegazione sensata, fondata sulla biologia o sulla medicina attuale, sul perché quella feature potrebbe influenzare il rischio. Questa visione in tre parti è importante perché molti legami statistici appariscenti si rivelano fluttuazioni casuali o riflessi di fattori di confondimento nascosti piuttosto che indizi di nuova biologia.

Come funziona la pipeline InterFeat
InterFeat elabora migliaia di feature in più fasi. Applica innanzitutto controlli statistici e di machine learning per mantenere solo le feature che aiutano davvero a prevedere una malattia, utilizzando misure come l’informazione mutua e punteggi di importanza derivati dai modelli. Successivamente verifica se la coppia feature–malattia è già nota: collega la feature e la malattia a un ampio grafo della conoscenza biomedica costruito da milioni di articoli di ricerca e cerca anche nel database PubMed per valutare quanto frequentemente compaiono insieme. Le feature già fortemente collegate alla malattia vengono rimosse come “non sorprendenti”, lasciando un pool di candidati poco esplorati.
Integrare i modelli linguistici come assistenti esperti di letteratura
I candidati rimanenti vengono quindi passati a un grande modello linguistico, trattato come una sorta di lettore potenziato della letteratura biomedica. Per ciascuna coppia candidata, il sistema recupera automaticamente abstract scientifici e testi di riferimento rilevanti, e il modello linguistico li usa per giudicare quanto la connessione sembri nuova e biologicamente plausibile. Scrive anche una breve spiegazione di possibili meccanismi, come vie infiammatorie condivise o gli effetti di certi farmaci. Questi punteggi vengono combinati in una valutazione complessiva di “interessante”, e i ricercatori ricevono un elenco gerarchizzato e leggibile di ipotesi da esaminare ulteriormente.
Testare il sistema su malattie reali
Il team ha valutato InterFeat su otto malattie principali, includendo condizioni rare come l’occlusione della vena retinica e comuni come la depressione. Partendo da circa 3.700 feature per malattia, la pipeline in genere ha ridotto il campo a meno di 80 candidati – meno del 2% della lista originale. Quando hanno simulato l’esecuzione del metodo nel 2011 e poi osservato come il grafo della conoscenza medica si è evoluto, fino al 21% delle feature segnalate da InterFeat è stata documentata nella letteratura solo anni dopo, suggerendo che la pipeline può emergere associazioni vere in anticipo. In un test separato, quattro medici senior hanno esaminato 137 feature selezionate dal computer per quattro malattie. Hanno valutato il 28% come interessanti, e tra i candidati più alti in classifica da InterFeat, il 40–53% è stato giudicato interessante, molto meglio rispetto a baseline semplici che ordinavano solo per importanza statistica.
Cosa significa per la scoperta medica futura
InterFeat non pretende di dimostrare causalità, né sostituisce il giudizio degli esperti. Agisce invece come un filtro intelligente che trasforma migliaia di segnali possibili in una short list gestibile, arricchita di idee nuove, utili per la predizione e biologicamente sensate. Esempi includono collegamenti tra l’uso prolungato di antibiotici nell’infanzia e infarti in età adulta, o punteggi di rischio genetico per altre condizioni che mostrano connessioni inattese con il cancro esofageo e i calcoli biliari. Combinando test statistici, grandi grafi della conoscenza, ricerca nella letteratura e modelli linguistici in un’unica pipeline configurabile, InterFeat offre ai ricercatori in medicina – e potenzialmente in altri campi ricchi di dati – un modo scalabile per concentrare l’attenzione sui lead più promettenti nascosti in dataset complessi.
Citazione: Ofer, D., Linial, M. & Shahaf, D. InterFeat: a pipeline for finding interesting scientific features. Sci Rep 16, 13980 (2026). https://doi.org/10.1038/s41598-026-43169-5
Parole chiave: estrazione di dati biomedici, fattori di rischio delle malattie, grafi della conoscenza, apprendimento automatico in medicina, generazione di ipotesi