Clear Sky Science · pl
Hierarchiczne wykrywanie złośliwego oprogramowania, identyfikacja rodzin i przypisywanie wariantów z użyciem hybrydowych modeli CNN na obrazach wykonywalnych w odcieniach szarości
Dlaczego to ma znaczenie dla przeciętnych użytkowników komputerów
Złośliwe oprogramowanie nie przychodzi już w postaci kilku łatwo rozpoznawalnych wirusów. Dziś napastnicy szybko produkują niezliczone podobne programy, które omijają tradycyjne narzędzia antywirusowe. Badanie pokazuje, że przekształcając programy w proste czarno‑białe obrazy i analizując je za pomocą współczesnych sieci rozpoznawania obrazów, komputer może nie tylko wykrywać malware z niemal doskonałą niezawodnością, ale także przyporządkowywać je do rodzin, a nawet konkretnych szczepów. Ten poziom szczegółowości pomaga obrońcom zrozumieć, co próbuje osiągnąć atak, skąd pochodzi i jak go zatrzymać.
Z bajtów programu do obrazów w odcieniach szarości
Autorzy koncentrują się na plikach wykonywalnych Windows, czyli na programach, które często rozpowszechniają malware na laptopach, komputerach stacjonarnych i serwerach. Zamiast ręcznie analizować każdy plik lub uruchamiać go w kontrolowanym środowisku, czytają jego surowe bajty i mapują każdy bajt na piksel obrazu w odcieniach szarości. Wynikiem jest obraz 224×224 w czerni i bieli, którego tekstury i bloki odzwierciedlają strukturę wewnątrz pliku: regiony kodu, wypełnienia, zaszyfrowane ładunki i inne. Każdy plik w ich zbiorze danych jest traktowany w ten sposób, niezależnie od tego, czy to nieszkodliwe oprogramowanie, czy jeden z 33 różnych wariantów z pięciu szerokich rodzin, takich jak ransomware i spyware. 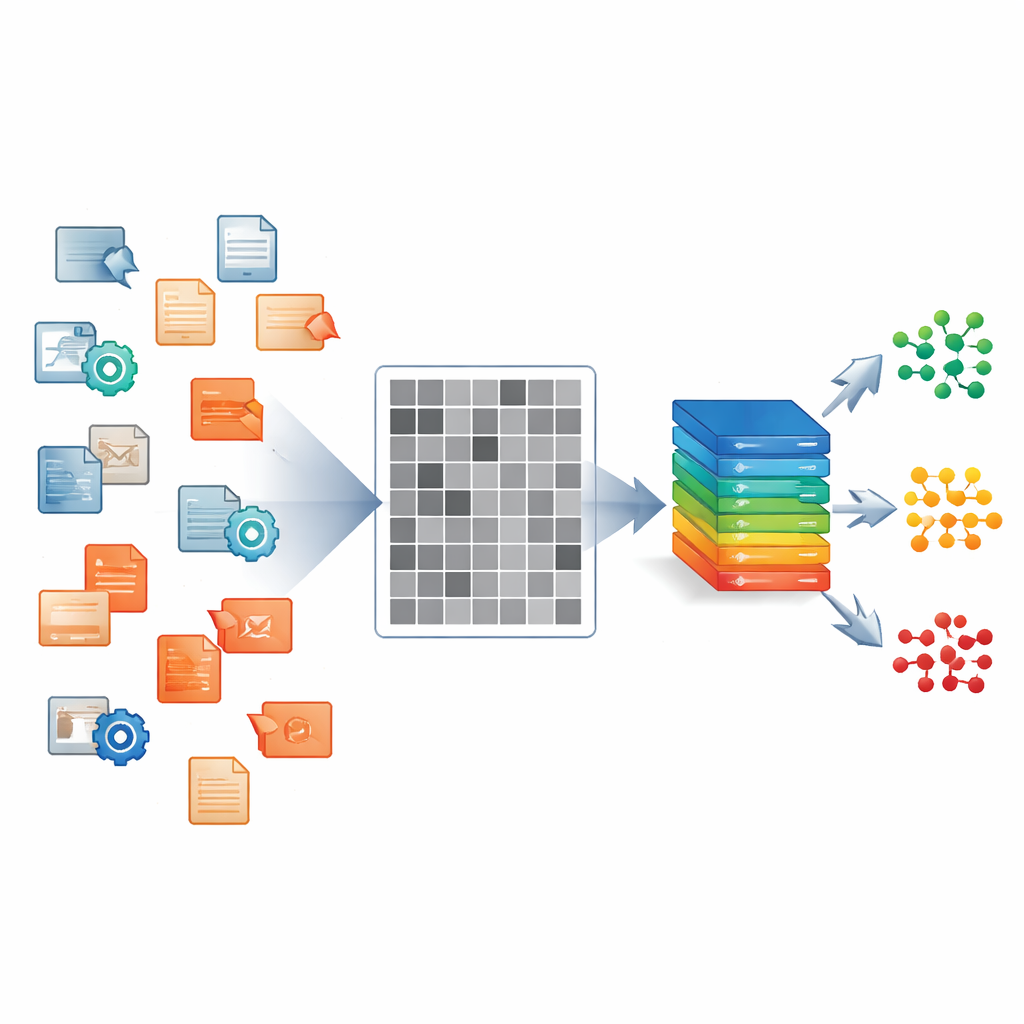
Jeden model, trzy odpowiedzi naraz
Na podstawie tych obrazów zespół buduje system uczenia głębokiego, który działa jak doświadczony funkcjonariusz kontroli. Jednym spojrzeniem na nadchodzący obraz odpowiada na trzy pytania: Czy ten plik jest nieszkodliwy czy złośliwy? Jeśli złośliwy — do której szerokiej rodziny należy? I który konkretny wariant najlepiej go opisuje? Rdzeniem systemu jest sieć splotowa, ten sam rodzaj architektury używany w codziennym rozpoznawaniu obrazów. Wspólne „plecy” uczą się ogólnych cech wizualnych z obrazów w odcieniach szarości. Nad nimi znajdują się trzy równoległe gałęzie wyjściowe wyspecjalizowane w trzech poziomach decyzji, dzięki czemu system uczy się, jak wzorce o różnej skali są ze sobą powiązane, zamiast traktować każde zadanie oddzielnie.
Trzy sposoby czytania ukrytej struktury
Aby sprawdzić, która konstrukcja działa najlepiej, autorzy testują trzy „hybrydowe” wersje modelu. W jednej główka z splotami czasowymi traktuje spłaszczony obraz jak sekwencję i używa dylatowanych filtrów do łączenia odległych regionów, wychwytując rozproszone wzorce długiego zasięgu. Druga wersja dodaje główkę opartą na kapsułach, która śledzi, jak małe części łączą się w większe struktury, co ma pomóc w rozróżnianiu blisko spokrewnionych wariantów dzielących wiele komponentów. Trzecia wersja wykorzystuje dwukierunkową warstwę sekwencyjną, która czyta obraz zarówno od lewej do prawej, jak i od prawej do lewej, naśladując sytuację, w której kontekst po obu stronach regionu zmienia jego znaczenie. Wszystkie trzy są trenowane na dokładnie tym samym zrównoważonym zbiorze danych, z równą reprezentacją każdego wariantu malware i plików nieszkodliwych, aby zapewnić, że różnice w wydajności odzwierciedlają architekturę, a nie przypadki danych. 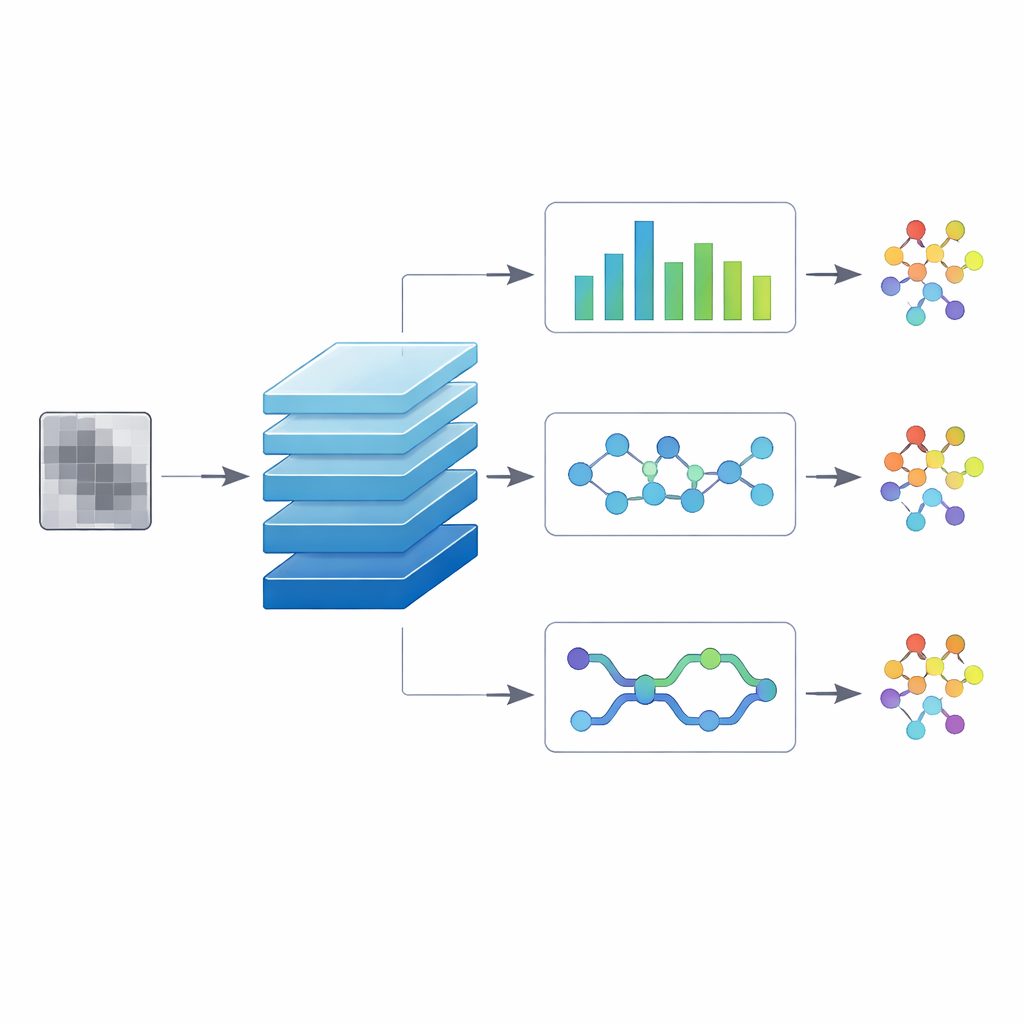
Jak dobrze to działa?
Na ponad 3000 obrazach testowych, niewykorzystywanych podczas treningu, hybrydy wypadają imponująco. W najprostszej kwestii — „złośliwy czy nie?” — dwie z trzech osiągają perfekcyjną dokładność 100%, a trzecia myli się tylko w kilku przypadkach, wykazując skłonność do ostrożności i oznaczając niektóre pliki nieszkodliwe jako podejrzane. Przy identyfikacji szerszej rodziny dokładność pozostaje bardzo wysoka, 97–98%, z jedynie sporadycznym myleniem grup o podobnym zachowaniu, na przykład spyware i trojanów. Najtrudniejsze jest wskazanie dokładnego wariantu spośród 33 opcji. Nawet tutaj wszystkie trzy modele osiągają 93–94% dokładności, korzystając wyłącznie z obrazów w odcieniach szarości, a szczegółowe rozkłady wyników pokazują, że większość wariantów jest rozpoznawana z bardzo wysoką niezawodnością. Jedna konstrukcja — łącząca sieci splotowe z splotami czasowymi — oferuje najbardziej zrównoważoną wydajność w odniesieniu do wszystkich wariantów.
Co to oznacza dla dochodzeń cyfrowych
Dla zespołów bezpieczeństwa i analityków sądowo‑informacyjnych te wyniki to coś więcej niż akademicki punkt odniesienia. W rzeczywistym incydencie zainfekowane maszyny mogą dostarczyć tysiące podejrzanych programów. Uruchamianie pełnej analizy behawioralnej każdego z nich jest powolne i kosztowne pod względem zasobów. Proponowany system oparty na obrazach może szybko odfiltrować pliki nieszkodliwe, pogrupować pozostałe według rodzin i wskazać prawdopodobne warianty w jednym przebiegu, wszystko bez uruchamiania ich. To czyni go potężnym narzędziem do triage: badacze mogą skoncentrować najdroższe narzędzia na najważniejszych próbkach, jednocześnie uzyskując wgląd na poziomie kampanii. Badanie wykazuje, że proste obrazy bajtów programów w odcieniach szarości, przetwarzane za pomocą starannie dobranych architektur sieci neuronowych, wystarczają do wspierania szczegółowego przypisywania malware, które wcześniej wymagało znacznie bardziej złożonej i czasochłonnej analizy.
Cytowanie: Saxena, M., Das, T. Hierarchical malware detection, family identification, and variant attribution using CNN-based hybrid models on grayscale executable images. Sci Rep 16, 9948 (2026). https://doi.org/10.1038/s41598-026-40655-8
Słowa kluczowe: wykrywanie złośliwego oprogramowania, uczenie głębokie, obrazy w odcieniach szarości, hybrydowe modele CNN, informatyka śledcza