Clear Sky Science · it
Rilevamento malware gerarchico, identificazione delle famiglie e attribuzione delle varianti usando modelli ibridi basati su CNN su immagini eseguibili in scala di grigi
Perché è importante per gli utenti quotidiani del computer
Il software dannoso non arriva più come pochi virus facilmente riconoscibili. Oggi gli aggressori producono rapidamente innumerevoli programmi simili tra loro che eludono gli strumenti antivirus tradizionali. Questo studio mostra che convertendo i programmi in semplici immagini in bianco e nero e analizzandole con reti moderne di riconoscimento delle immagini, un computer può non solo individuare il malware con affidabilità quasi perfetta, ma anche classificarlo in famiglie e persino in ceppi specifici. Un livello di dettaglio del genere aiuta i difensori a capire cosa sta tentando di fare un attacco, da dove proviene e come fermarlo.
Dai byte del programma alle immagini in scala di grigi
Gli autori si concentrano sui file eseguibili Windows, il tipo di programmi che comunemente diffonde malware su laptop, desktop e server. Invece di sezionare ogni file manualmente o eseguirlo in un laboratorio controllato, leggono i suoi byte grezzi e mappano ogni byte a un pixel in un’immagine in scala di grigi. Il risultato è un’immagine 224×224 in bianco e nero le cui trame e blocchi riflettono la struttura interna del file: regioni di codice, padding, payload crittografati e altro. Ogni file del loro dataset viene trattato in questo modo, sia che si tratti di software innocuo sia che appartenga a una delle 33 varianti di malware distinte distribuite in cinque ampie famiglie come ransomware e spyware. 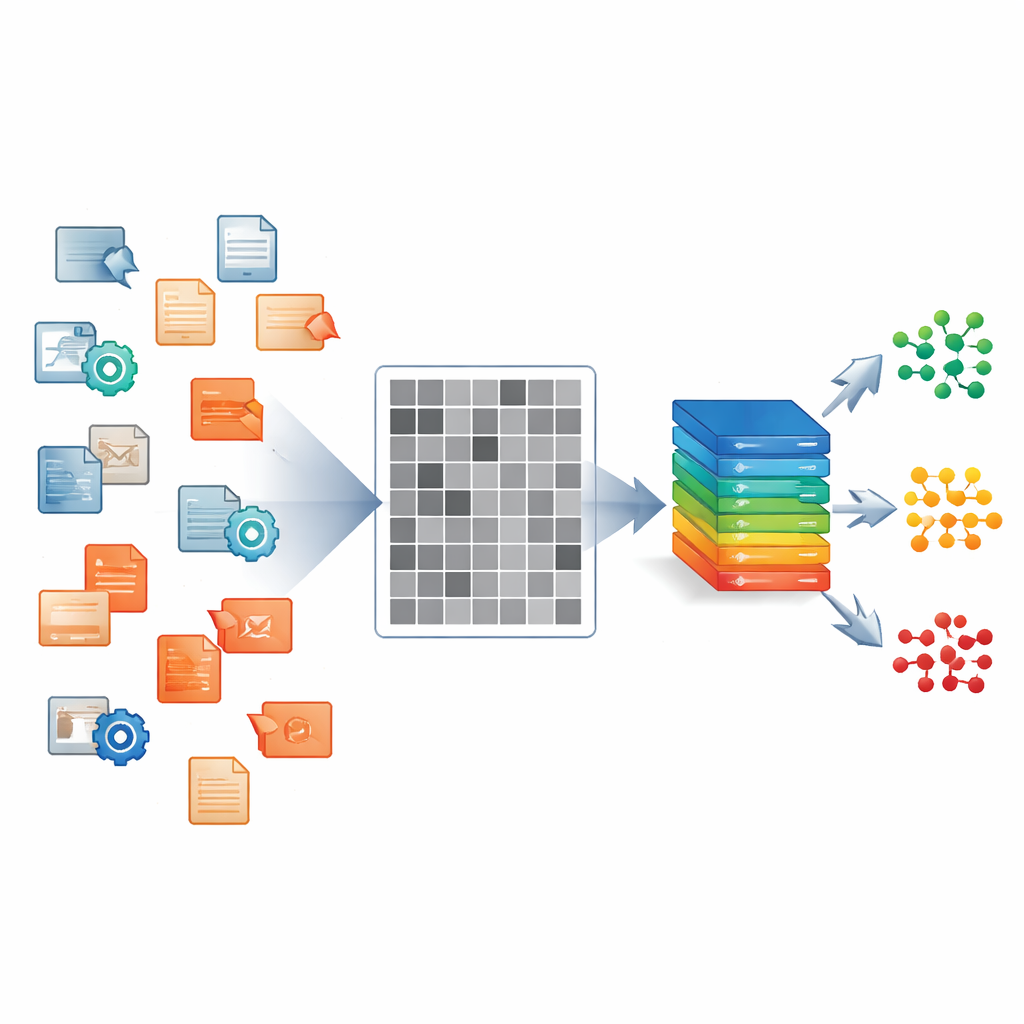
Un modello, tre risposte contemporaneamente
Su queste immagini il team costruisce un sistema di deep learning che funziona come un esperto agente doganale. Con un’unica occhiata a un’immagine in ingresso risponde a tre domande contemporaneamente: questo file è benigno o dannoso? In caso dannoso, a quale famiglia ampia appartiene? E quale variante specifica lo descrive meglio? Il nucleo del sistema è una rete convoluzionale, lo stesso tipo di architettura usata per il riconoscimento delle immagini di tutti i giorni. Questo backbone condiviso apprende caratteristiche visive generali dalle immagini in scala di grigi. Sopra di esso si trovano tre rami di output paralleli che si specializzano nei tre livelli decisionali, così il sistema può imparare come i pattern grossolani e quelli fini si relazionano invece di trattare ogni compito separatamente.
Tre modi per leggere la struttura nascosta
Per indagare quale progetto funzioni meglio, gli autori testano tre versioni “ibride” del modello. In una, una testa a convoluzione temporale tratta l’immagine appiattita come una sequenza e usa filtri dilatati per collegare regioni distanti, catturando pattern a lungo raggio sparsi nel file. Una seconda versione aggiunge una testa basata su capsule che tiene traccia di come piccole parti si combinano in strutture più grandi, con l’obiettivo di distinguere varianti strettamente correlate che condividono molti componenti. La terza versione usa uno strato sequenziale bidirezionale che legge l’immagine sia da sinistra a destra sia da destra a sinistra, imitando come il contesto su entrambi i lati di una regione possa cambiarne il significato. Tutte e tre vengono addestrate sullo stesso dataset bilanciato, con uguale rappresentazione di ogni variante di malware e dei file benigni, per garantire che le differenze di prestazione riflettano l’architettura e non peculiarità dei dati. 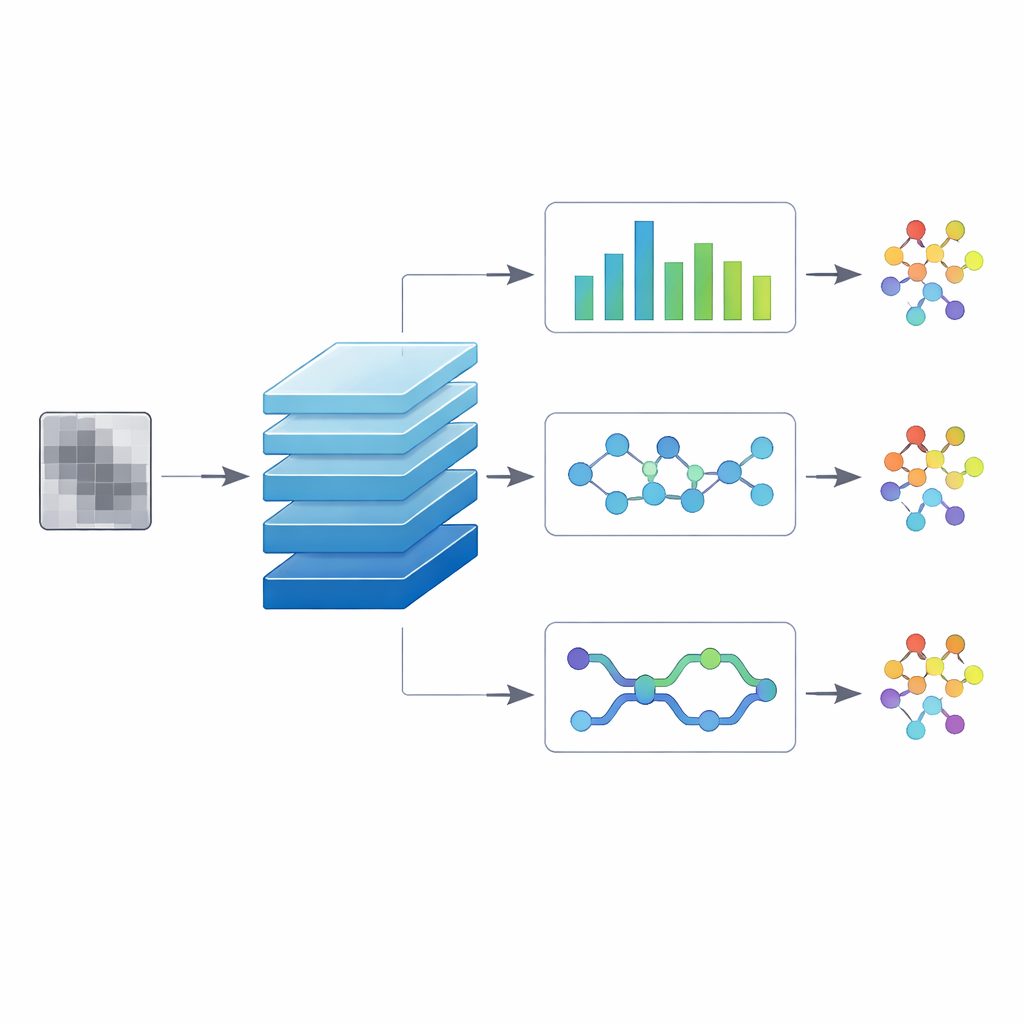
Quanto funziona bene?
Su oltre 3.000 immagini di test tenute da parte, gli ibridi ottengono risultati sorprendentemente buoni. Per la domanda più semplice — “dannoso o no?” — due dei tre raggiungono una perfetta accuratezza del 100% e il terzo sbaglia solo su una manciata di file benigni, tendendo a preferire la cautela. Quando viene chiesto di nominare la famiglia più ampia, l’accuratezza rimane molto alta, tra il 97% e il 98%, con solo occasionali confusioni tra gruppi con comportamenti simili come spyware e trojan. La prova più impegnativa è identificare la variante esatta tra 33 opzioni. Anche qui, tutti e tre i modelli raggiungono un’accuratezza del 93–94% usando soltanto immagini in scala di grigi, e le analisi dettagliate mostrano che la maggior parte delle varianti viene riconosciuta con affidabilità molto elevata. Una delle architetture, che abbina il backbone convoluzionale a convoluzioni temporali, offre la performance più bilanciata su tutte le varianti.
Cosa significa per le indagini digitali
Per i team di sicurezza e gli analisti forensi, questi risultati sono più di un semplice benchmark accademico. In un incidente reale, migliaia di programmi sospetti potrebbero essere raccolti dalle macchine infette. Eseguire analisi comportamentali complete su ciascuno è lento e dispendioso in termini di risorse. Il sistema proposto basato su immagini può rapidamente filtrare i file innocui, raggruppare il resto per famiglia e individuare le varianti probabili in un’unica passata, il tutto senza eseguirli. Questo lo rende uno strumento di triage potente: gli investigatori possono concentrare gli strumenti più costosi sui campioni più importanti pur ottenendo informazioni a livello di campagna. Lo studio dimostra che semplici immagini in scala di grigi dei byte dei programmi, elaborate con architetture di rete neurale scelte con cura, sono sufficienti per supportare un’attribuzione del malware a grana fine che prima richiedeva analisi molto più elaborate e dispendiose in termini di tempo.
Citazione: Saxena, M., Das, T. Hierarchical malware detection, family identification, and variant attribution using CNN-based hybrid models on grayscale executable images. Sci Rep 16, 9948 (2026). https://doi.org/10.1038/s41598-026-40655-8
Parole chiave: rilevamento malware, deep learning, immagini in scala di grigi, modelli ibridi CNN, informatica forense