Clear Sky Science · fr
Détection hiérarchique de logiciels malveillants, identification de familles et attribution de variantes à l’aide de modèles hybrides CNN sur des images exécutables en niveaux de gris
Pourquoi c’est important pour les utilisateurs quotidiens d’ordinateurs
Les logiciels malveillants n’arrivent plus sous la forme de quelques virus facilement reconnaissables. Aujourd’hui, les attaquants produisent rapidement d’innombrables programmes se ressemblant qui échappent aux outils antivirus traditionnels. Cette étude montre que, en transformant les programmes en simples images noir et blanc et en les analysant avec des réseaux modernes de reconnaissance d’images, un ordinateur peut non seulement détecter les maliciels avec une fiabilité quasi parfaite, mais aussi les classer par familles et même par souches spécifiques. Ce niveau de détail aide les défenseurs à comprendre ce que cherche à faire une attaque, d’où elle vient et comment l’arrêter.
Des octets de programme aux images en niveaux de gris
Les auteurs se concentrent sur les fichiers exécutables Windows, le type de programmes qui propage souvent les maliciels sur ordinateurs portables, postes de travail et serveurs. Au lieu de disséquer chaque fichier manuellement ou de l’exécuter dans un laboratoire contrôlé, ils lisent ses octets bruts et mappent chaque octet sur un pixel d’une image en niveaux de gris. Le résultat est une image noir et blanc de 224×224 dont les textures et les blocs reflètent la structure interne du fichier : zones de code, remplissage, charges utiles chiffrées, etc. Chaque fichier de leur jeu de données est traité de cette façon, qu’il s’agisse d’un logiciel inoffensif ou d’une des 33 variantes malveillantes distinctes réparties en cinq grandes familles telles que les ransomwares et les logiciels espions. 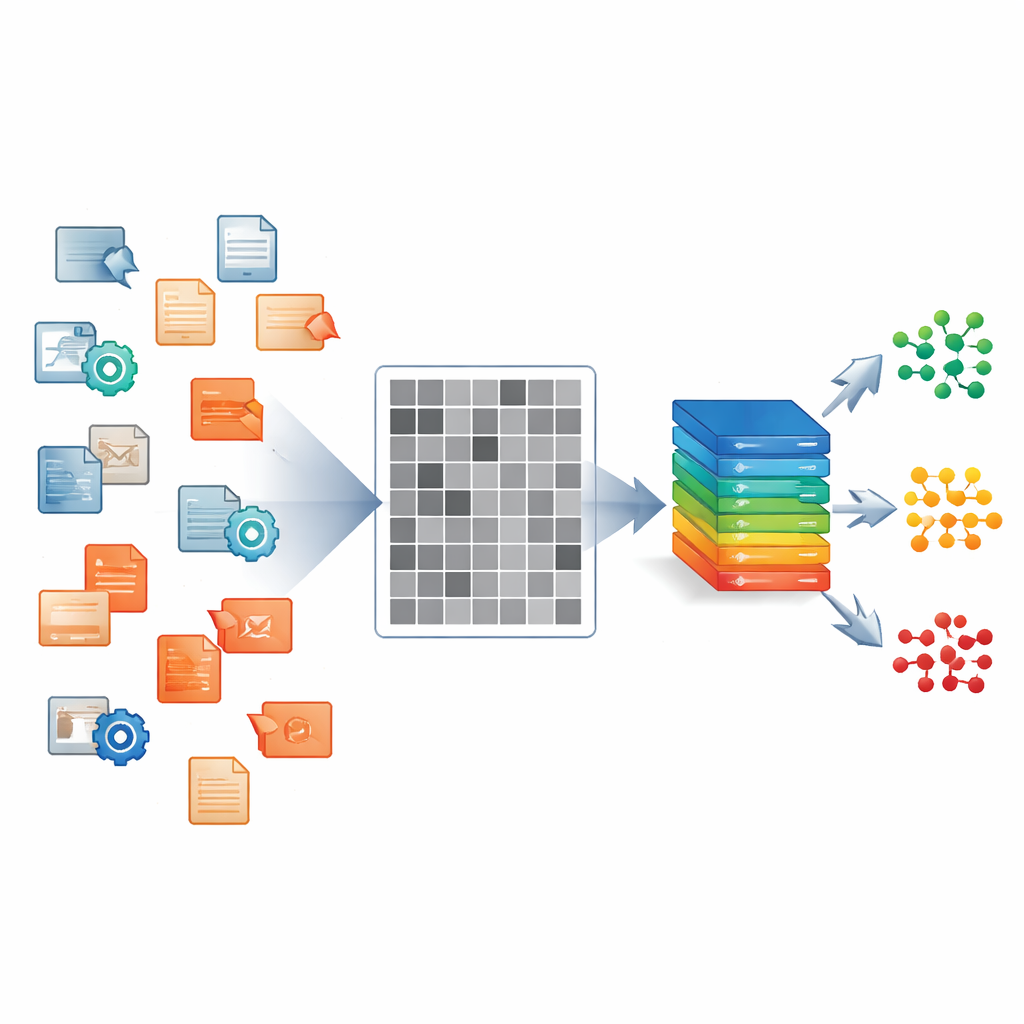
Un modèle, trois réponses à la fois
À partir de ces images, l’équipe construit un système d’apprentissage profond qui fonctionne comme un agent expérimenté des douanes. D’un seul coup d’œil sur une image entrante, il répond à trois questions à la fois : ce fichier est‑il bénin ou malveillant ? Si malveillant, à quelle grande famille appartient‑il ? Et quelle variante spécifique le décrit le mieux ? Le cœur du système est un réseau convolutionnel, le même type d’architecture utilisé pour la reconnaissance d’images courante. Cette colonne vertébrale partagée apprend des caractéristiques visuelles générales à partir des images en niveaux de gris. Au‑dessus se trouvent trois branches de sortie parallèles qui se spécialisent dans les trois niveaux de décision, de sorte que le système apprend comment les motifs grossiers et fins se relient entre eux au lieu de traiter chaque tâche séparément.
Trois manières de lire la structure cachée
Pour tester quelle conception fonctionne le mieux, les auteurs évaluent trois versions « hybrides » du modèle. Dans la première, une tête à convolution temporelle considère l’image aplatie comme une séquence et utilise des filtres dilatés pour relier des régions distantes, capturant des motifs de longue portée dispersés dans le fichier. Une deuxième version ajoute une tête basée sur des capsules qui suit comment de petites parties se combinent en structures plus grandes, visant à distinguer des variantes étroitement liées partageant de nombreux composants. La troisième version utilise une couche séquentielle bidirectionnelle qui lit l’image de gauche à droite et de droite à gauche, imitant comment le contexte de chaque côté d’une région peut en changer le sens. Les trois sont entraînées sur exactement le même jeu de données équilibré, avec une représentation égale de chaque variante malveillante et des fichiers bénins, afin de garantir que les différences de performance reflètent l’architecture plutôt que des particularités des données. 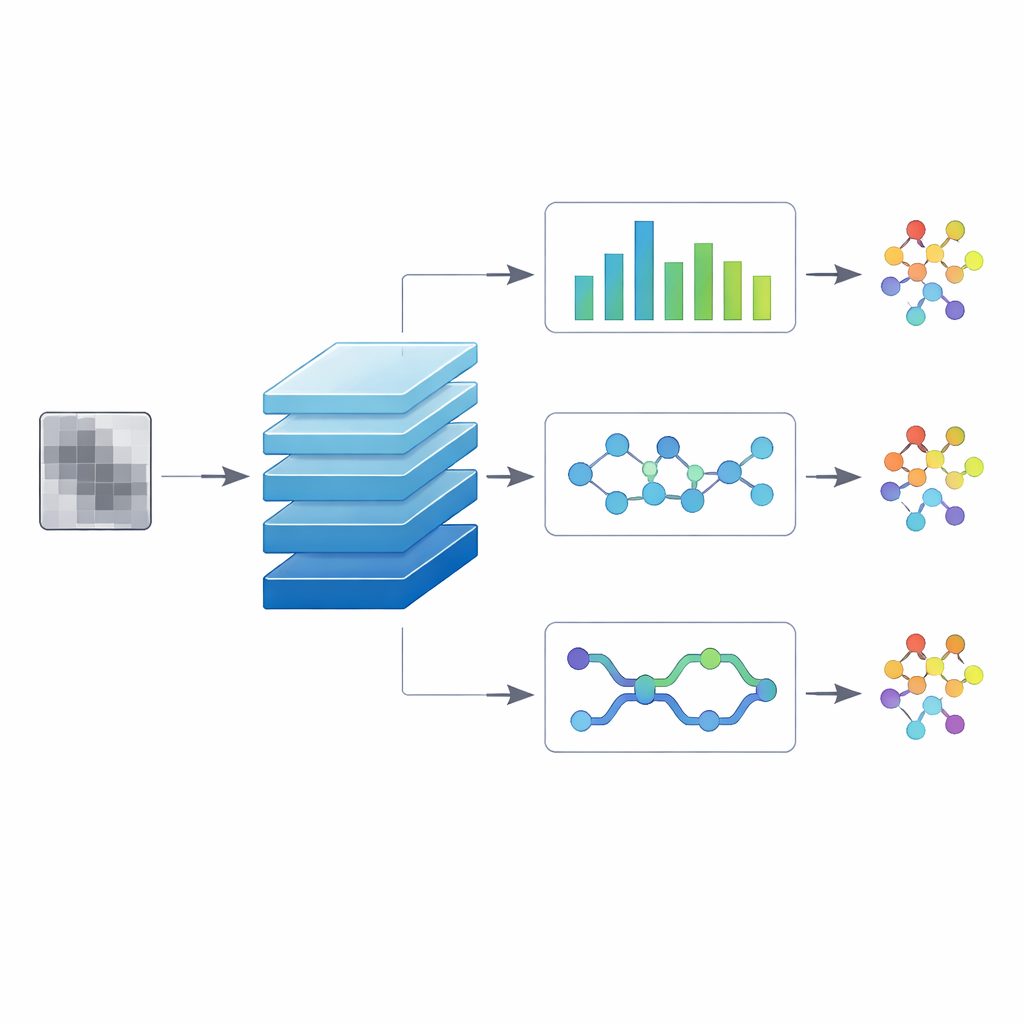
Quelle est l’efficacité ?
Sur plus de 3 000 images de test tenues à l’écart, les modèles hybrides obtiennent des performances remarquables. Pour la question la plus simple — « malveillant ou non ? » — deux des trois atteignent une précision parfaite de 100 %, et la troisième ne manque que quelques fichiers bénins, par excès de prudence. Lorsqu’il s’agit de nommer la famille plus large, la précision reste très élevée à 97–98 %, avec seulement des confusions occasionnelles entre des groupes comportementalement similaires comme les logiciels espions et les chevaux de Troie. Le test le plus difficile est d’identifier la variante exacte parmi 33 options. Là encore, les trois modèles atteignent 93–94 % de précision en n’utilisant que des images en niveaux de gris, et des ventilations détaillées des scores montrent que la plupart des variantes sont reconnues avec une fiabilité très élevée. Une conception, associant la colonne convolutionnelle à des convolutions temporelles, offre la performance la plus équilibrée sur l’ensemble des variantes.
Ce que cela signifie pour les enquêtes numériques
Pour les équipes de sécurité et les analystes forensiques, ces résultats dépassent le simple benchmark académique. Lors d’un incident réel, des milliers de programmes suspects peuvent être collectés sur des machines infectées. Exécuter une analyse comportementale complète sur chacun d’eux est lent et gourmand en ressources. Le système proposé basé sur des images peut rapidement éliminer les fichiers inoffensifs, regrouper le reste par famille et identifier les variantes probables en une seule passe, le tout sans les exécuter. Cela en fait un outil de triage puissant : les enquêteurs peuvent concentrer leurs outils les plus coûteux sur les échantillons les plus importants tout en obtenant une vision au niveau de la campagne. L’étude démontre que de simples images en niveaux de gris des octets de programme, traitées avec des architectures de réseaux neuronaux judicieusement choisies, suffisent à produire une attribution fine des maliciels qui nécessitait auparavant des analyses bien plus élaborées et chronophages.
Citation: Saxena, M., Das, T. Hierarchical malware detection, family identification, and variant attribution using CNN-based hybrid models on grayscale executable images. Sci Rep 16, 9948 (2026). https://doi.org/10.1038/s41598-026-40655-8
Mots-clés: détection de logiciels malveillants, apprentissage profond, images en niveaux de gris, modèles hybrides CNN, informatique légale