Clear Sky Science · nl
Hiërarchische malwaredetectie, familie-identificatie en varianttoewijzing met CNN-gebaseerde hybride modellen op grijswaarden uitvoerbare afbeeldingen
Waarom dit belangrijk is voor alledaagse computergebruikers
Kwaadaardige software verschijnt niet langer als een paar gemakkelijk te herkennen virussen. Tegenwoordig produceren aanvallers in snel tempo talloze look‑alike programma’s die traditionele antivirusprogramma’s omzeilen. Deze studie laat zien dat door programma’s om te zetten in eenvoudige zwart‑wit plaatjes en ze te lezen met moderne beeldherkenningsnetwerken, een computer niet alleen malware met bijna perfecte betrouwbaarheid kan opsporen, maar deze ook in families en zelfs specifieke stammen kan indelen. Dat niveau van detail helpt verdedigers te begrijpen wat een aanval probeert te bereiken, waar hij vandaan komt en hoe hij te stoppen.
Van programbytes naar grijsplaatjes
De auteurs richten zich op Windows‑uitvoerbare bestanden, het soort programma’s dat vaak malware verspreidt op laptops, desktops en servers. In plaats van elk bestand handmatig te analyseren of het in een gecontroleerd lab uit te voeren, lezen ze de ruwe bytes rechtstreeks en zetten elke byte om in een pixel in een grijswaardenafbeelding. Het resultaat is een 224×224 zwart‑wit afbeelding waarvan de texturen en blokken structuren in het bestand weerspiegelen: codegebieden, opvulling, versleutelde payloads en meer. Elk bestand in hun dataset wordt op deze manier behandeld, of het nu onschadelijke software is of een van 33 verschillende malwarevarianten die vijf brede families omvatten, zoals ransomware en spyware. 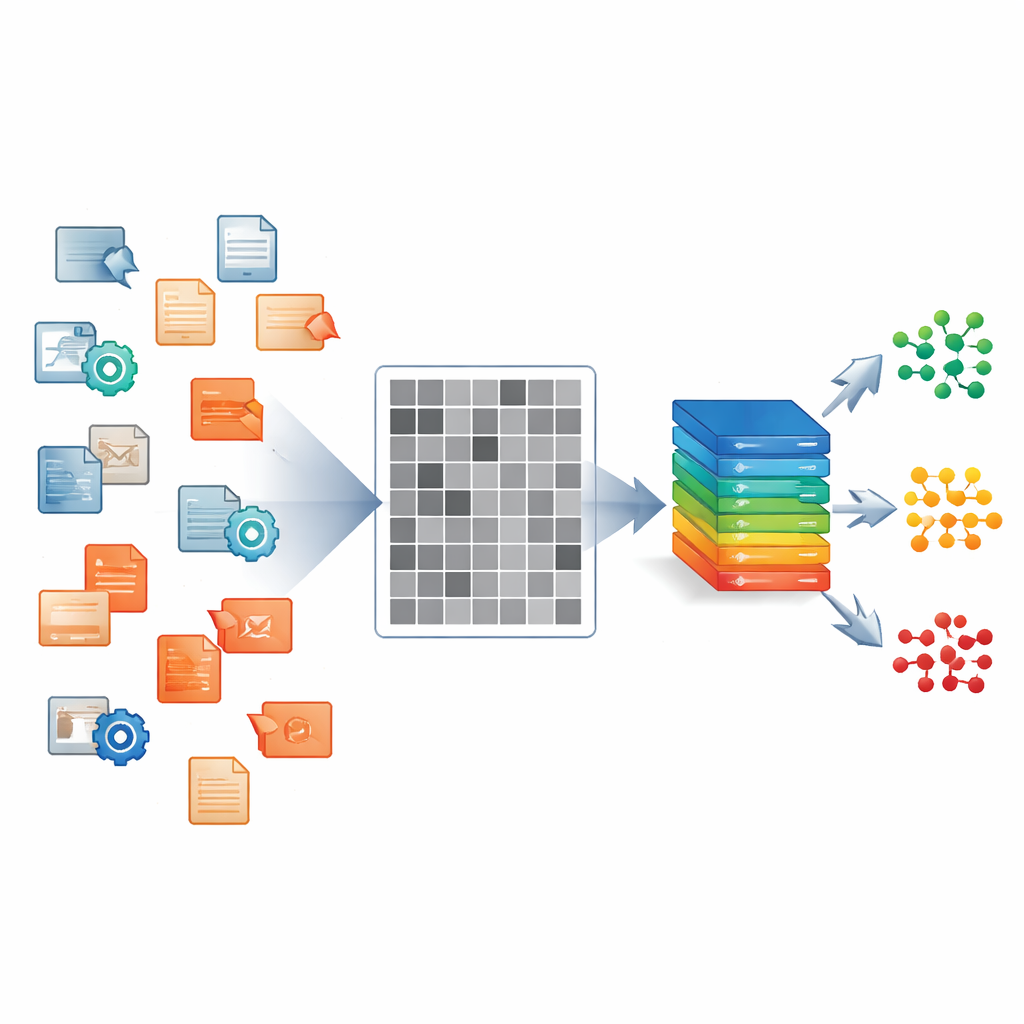
Één model, drie antwoorden tegelijk
Op basis van deze afbeeldingen bouwen de onderzoekers een deep‑learning systeem dat functioneert als een ervaren douanebeambte. Met één blik op een binnenkomende afbeelding beantwoordt het drie vragen tegelijk: is dit bestand onschadelijk of kwaadaardig? Als het kwaadaardig is, tot welke brede familie behoort het? En welke specifieke variant beschrijft het het beste? De kern van het systeem is een convolutioneel netwerk, hetzelfde type architectuur dat wordt gebruikt voor alledaagse beeldherkenning. Deze gedeelde backbone leert algemene visuele kenmerken uit de grijswaardenafbeeldingen. Daarboven bevinden zich drie parallelle uitvoertakken die zich specialiseren in de drie beslissingsniveaus, zodat het systeem kan leren hoe grof‑ en fijnmazige patronen zich tot elkaar verhouden in plaats van elke taak apart te behandelen.
Drie manieren om verborgen structuur te lezen
Om te onderzoeken welk ontwerp het beste werkt, testen de auteurs drie “hybride” versies van het model. In de ene behandelt een temporale convolutie‑kop de afgevlakte afbeelding als een sequentie en gebruikt gedilateerde filters om verre regio’s met elkaar te verbinden, waardoor langafstandspatronen die over het bestand verspreid zijn worden vastgelegd. Een tweede versie voegt een capsule‑gebaseerde kop toe die bijhoudt hoe kleine onderdelen zich combineren tot grotere structuren, met als doel nauw verwante varianten te onderscheiden die veel componenten delen. De derde versie gebruikt een bidirectionele sequentielaag die de afbeelding zowel van links‑naar‑rechts als van rechts‑naar‑links leest, waarbij het nabije context aan beide zijden van een regio meeneemt die de betekenis kan veranderen. Alle drie worden getraind op exact dezelfde gebalanceerde dataset, met gelijke vertegenwoordiging van elke malwarevariant en van onschadelijke bestanden, zodat prestatieverschillen architectuurreflecties zijn en niet het gevolg van data‑eigenaardigheden. 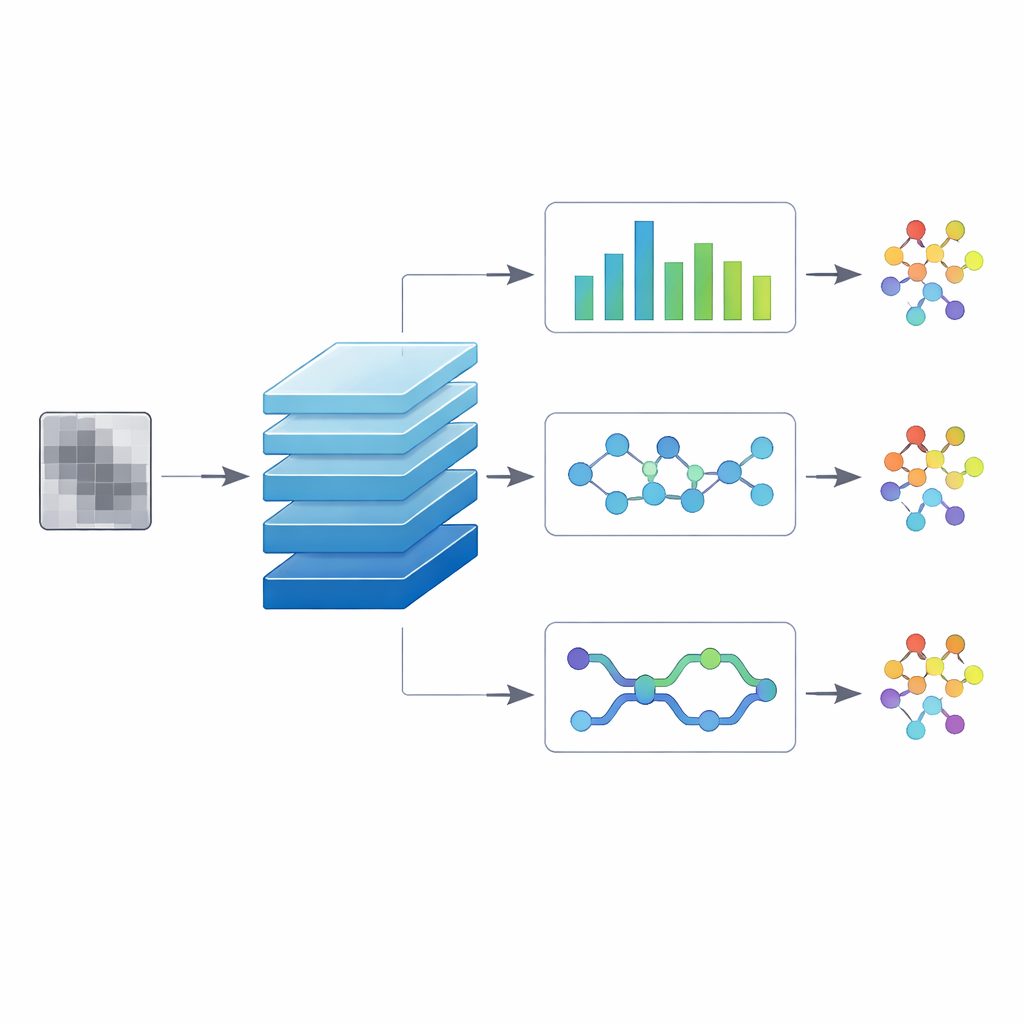
Hoe goed werkt het?
Over meer dan 3.000 apart gehouden testafbeeldingen presteren de hybriden opvallend goed. Voor de eenvoudigste vraag—“kwaadaardig of niet?”—bereiken twee van de drie een foutloze 100% nauwkeurigheid, en de derde maakt slechts een handvol fouten bij onschuldige bestanden, waarbij hij de voorkeur geeft aan voorzichtigheid. Wanneer wordt gevraagd naar de bredere familie, blijft de nauwkeurigheid zeer hoog met 97–98%, met slechts af en toe verwarring tussen gedragsmatig vergelijkbare groepen zoals spyware en trojans. De zwaarste test is het noemen van de exacte variant uit 33 opties. Zelfs hier bereiken alle drie modellen 93–94% nauwkeurigheid met alleen grijswaardenafbeeldingen, en gedetailleerde score‑uitsplitsingen tonen dat de meeste varianten met zeer hoge betrouwbaarheid worden herkend. Eén ontwerp, dat de convolutionele backbone koppelt aan temporale convoluties, biedt de meest evenwichtige prestaties over alle varianten.
Wat dit betekent voor digitale onderzoeken
Voor beveiligingsteams en forensische analisten zijn deze resultaten meer dan een academische benchmark. In een echt incident kunnen duizenden verdachte programma’s worden verzameld van geïnfecteerde systemen. Het uitvoeren van volledige gedragsanalyses op elk bestand is traag en vraagt veel middelen. Het voorgestelde beeldgebaseerde systeem kan snel onschuldige bestanden filteren, de rest per familie groeperen en waarschijnlijke varianten in één keer aanwijzen, allemaal zonder ze uit te voeren. Dat maakt het een krachtig triagehulpmiddel: onderzoekers kunnen hun duurste middelen richten op de belangrijkste monsters terwijl ze tegelijk inzicht krijgen op campagneniveau. De studie toont aan dat eenvoudige grijsplaatjes van programbytes, verwerkt met zorgvuldig gekozen neurale‑netwerkontwerpen, voldoende zijn voor fijnmazige malwaretoewijzing die vroeger veel uitgebreider en tijdrovender analyse vereiste.
Bronvermelding: Saxena, M., Das, T. Hierarchical malware detection, family identification, and variant attribution using CNN-based hybrid models on grayscale executable images. Sci Rep 16, 9948 (2026). https://doi.org/10.1038/s41598-026-40655-8
Trefwoorden: malwaredetectie, deep learning, grijswaardenafbeeldingen, CNN-hybride modellen, digitale forensische wetenschap