Clear Sky Science · nl
Een machine learning-gebaseerde farmacokinetiekvoorspeller (EGFR-PROPK) voor EGFR-gerichte PROTACs
Slimmer geneesmiddelontwerp voor moeilijk behandelbare kankers
Veel veelbelovende nieuwe kankergeneesmiddelen falen niet omdat ze hun doel missen, maar omdat het lichaam ze te snel verwijdert, op de verkeerde plaatsen opslaat of slecht opneemt. Een nieuwe klasse medicijnen, PROTACs, kan ziekteveroorzakende eiwitten vernietigen die ooit als “ongedruggable” werden beschouwd, maar hun gedrag in het lichaam is bijzonder moeilijk te voorspellen. Deze studie introduceert een machine learning-hulpmiddel, EGFR-PROPK, specifiek ontworpen om te voorspellen hoe een groep PROTACs tegen een belangrijk kankereiwit zich door het lichaam verplaatst, met als doel wetenschappers te helpen betere geneesmiddelkandidaten eerder te kiezen en minder jaren en middelen te verspillen aan doodlopende wegen.
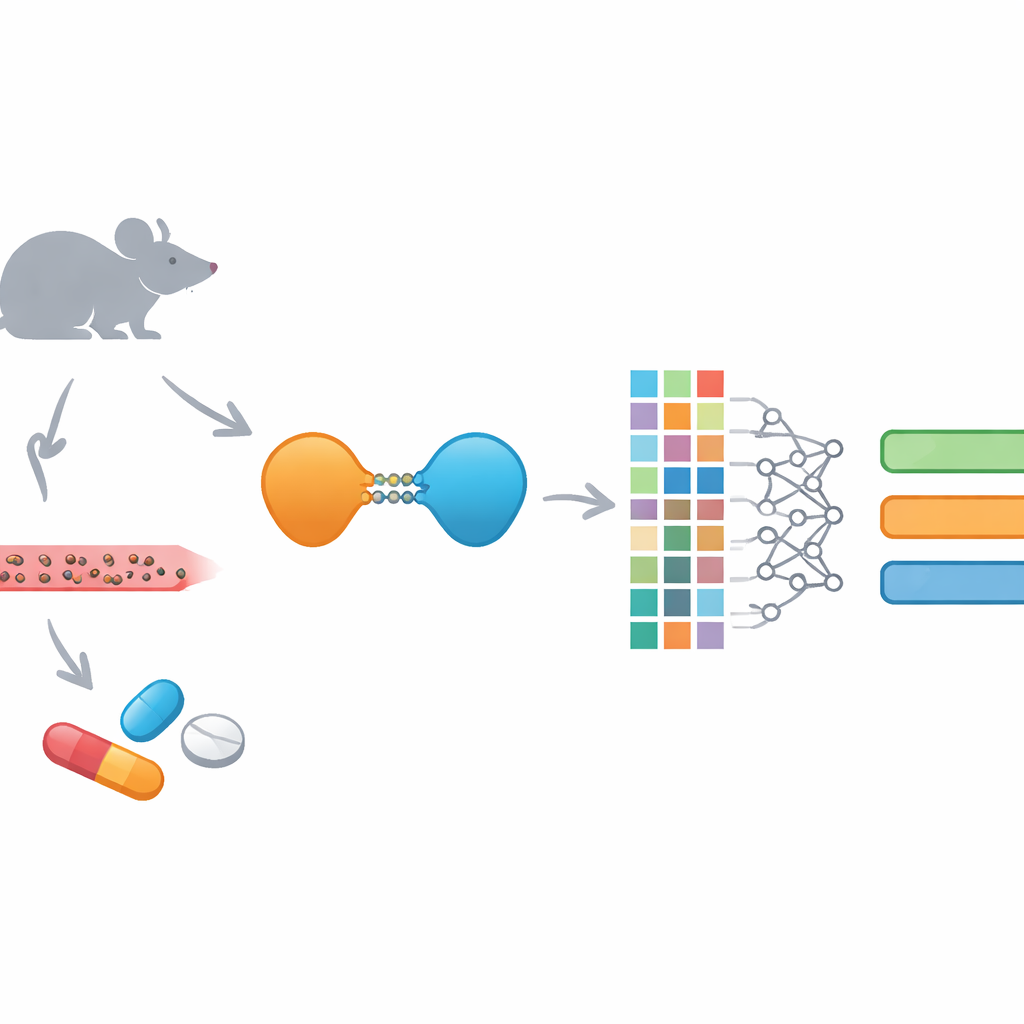
Nieuwe eiwitvernietigende medicijnen en hun uitdagingen
PROTACs zijn ongebruikelijke geneesmiddelen: in plaats van alleen een eiwit te blokkeren, markeren ze het voor vernietiging door het eigen afbraaksysteem van de cel. Elke PROTAC koppelt een bindingsdeel voor het ziekte-doel aan een onderdeel dat een cellulair “versnipperaar” rekruteert, verbonden door een flexibele keten. Dit ontwerp stelt ze in staat om eiwitten aan te vallen die normale medicijnen niet gemakkelijk kunnen bereiken en laat vaak tijdelijke binding toe in plaats van voortdurende bezetting van een eiwitplaats. Diezelfde grootte en complexiteit maken PROTACs echter moeilijk te leveren en te controleren in het lichaam. Ze hebben de neiging groot, relatief vetachtig en sterk aan bloedproteïnen gebonden te zijn, wat de opname, distributie, afbraak en uitscheiding bemoeilijkt.
Waarom gebruikelijke regels voor geneesmiddelgedrag tekortschieten
Traditionele geneesmiddelontwikkelaars gebruiken eenvoudige grootheden, zoals molecuulgewicht, lipofiliciteit (LogP) en vuistregelmetingen van “drug-likeness”, om te gokken hoe een verbinding zich in het lichaam kan gedragen. De onderzoekers vroegen zich eerst af of deze bekende maten konden verklaren hoe 100 PROTACs die de epidermale groeifactorreceptor (EGFR) targetten — een belangrijke drijfveer in veel vormen van kanker — zich gedragen in levende muizen. Ze concentreerden zich op drie kern-eigenschappen: clearence (hoe snel het lichaam het geneesmiddel verwijdert), halfwaardetijd (hoe lang het geneesmiddel in circulatie blijft) en schijnbaar distributievolume (hoe wijd het zich in weefsels verspreidt). Toen ze deze eigenschappen vergeleken met basisbeschrijvingen, waren de datapunten verspreid zonder duidelijke trends, wat aantoonde dat eenvoudige chemische regels niet voldoende zijn om het gedrag van PROTACs te voorspellen.
Het trainen van een op maat gemaakte voorspeller
Om deze kloof te dichten bouwde het team EGFR-PROPK, een machine learning-voorspeller specifiek afgestemd op EGFR-gerichte PROTACs. Ze voerden eerst muisstudies uit met 100 verschillende PROTACs en maten hun clearence, halfwaardetijd en distributievolume na toediening. Vervolgens beschreven ze elk molecuul met verschillende rijke “fingerprints” die de gedetailleerde structuur coderen en berekenden ze 200 aanvullende chemische kenmerken. Deze numerieke beschrijvingen werden ingevoerd in een op CatBoost gebaseerde model, een modern algoritme dat uitblinkt in het vinden van patronen in tabeldata. In tegenstelling tot algemene hulpmiddelen werd EGFR-PROPK direct getraind op in vivo-resultaten voor PROTACs, waardoor het subtiele verbanden kon leren tussen complexe linker‑vormen, totale grootte en hoe lang de medicijnen in het bloed blijven of zich in weefsels verspreiden.
Een hogere prestatie dan algemene modellen en het blootleggen van verborgen nuances
De onderzoekers vergeleken EGFR-PROPK met veelgebruikte voorspellingsplatformen die vooral zijn gebouwd voor traditionele kleine-molecuul geneesmiddelen. Wanneer die generieke modellen “as is” op PROTACs werden toegepast, waren hun voorspellingen slecht: geschatte waarden voor halfwaardetijd, clearence en weefseldistributie week vaak sterk af van echte metingen. Zelfs nadat één concurrerend model was bijgetraind met PROTAC-gegevens, bleef het achter. EGFR-PROPK daarentegen behaalde een substantieel betere overeenstemming tussen voorspelde en experimentele waarden, vooral voor halfwaardetijd en clearence, met matige verbeteringen voor distributie. Het model ging ook goed om met casestudies uit de praktijk: twee PROTACs met zeer vergelijkbare structuren maar heel verschillend gedrag werden nauwkeuriger onderscheiden door EGFR-PROPK dan door algemene tools, wat het belang van PROTAC-specifieke trainingsdata onderstreept.
Het chemische landschap in kaart brengen en zijn grenzen
Naast prestatiecijfers controleerde het team of hun 100 PROTACs een breed scala aan ontwerpen dekte of slechts een klein hoekje van de chemische ruimte. Door moleculen terug te brengen tot hun kernscaffolds en ze te visualiseren tussen duizenden gepatenteerde PROTACs, lieten ze zien dat hun set vele verschillende structurele types beslaat, vooral in de flexibele linkers. Dit betekent dat het model goed geschikt is voor het verfijnen van EGFR-gerichte PROTACs die belangrijke bouwstenen delen maar variëren in hoe hun onderdelen zijn verbonden. Tegelijk benadrukken de auteurs dat het hulpmiddel een domeinspecialist is: de nauwkeurigheid kan afnemen voor PROTACs die rond geheel andere doelen of afbraakroutes zijn gebouwd, wat wijst op de behoefte aan uitbreiding en transfer learning over datasets heen.
Wat dit betekent voor toekomstige medicijnen
Voor niet-experts is de belangrijkste conclusie dat de “leidingen” van een geneesmiddel in het lichaam — hoe het wordt opgenomen, waar het naartoe gaat en hoe lang het blijft — het verschil kunnen maken tussen succes en falen van een veelbelovende kankertherapie, en dat de gebruikelijke vuistregels voor kleine pillen niet goed werken voor de nieuwe generatie degraders zoals PROTACs. Door EGFR-PROPK te creëren tonen de onderzoekers aan dat zorgvuldig verzamelde dierdata, gecombineerd met geavanceerde patroonherkenningsmethoden, een veel scherper vroegtijdig beeld kunnen geven van hoe deze complexe moleculen zich zullen gedragen. Dit soort op maat gemaakte voorspelling zou chemici moeten helpen PROTACs te ontwerpen die niet alleen de juiste eiwitten vernietigen maar ze ook op de juiste niveaus bereiken, wat de weg vrijmaakt voor effectievere en veiligere behandelingen tegen resistente kankers.
Bronvermelding: Zhang, R., Li, F., Liu, Y. et al. A machine learning-based pharmacokinetics predictor (EGFR-PROPK) for EGFR-targeting PROTACs. Commun Chem 9, 134 (2026). https://doi.org/10.1038/s42004-026-01938-3
Trefwoorden: PROTAC farmacokinetiek, EGFR-gerichte degraderes, machine learning in geneesmiddelontwerp, ADMET-voorspelling, gerichte eiwitafbraak