Clear Sky Science · it
SiaCon-DetNet con HySHO: un framework avanzato basato su transformer per il riconoscimento facciale consapevole delle emozioni
Perché insegnare ai computer a leggere le emozioni è importante
Dalle videochiamate ai tutor virtuali e alle app per la salute, incontriamo sempre più spesso macchine attraverso schermi. Tuttavia la maggior parte di questi sistemi è ancora emotivamente «sorda»: non rileva se siamo confusi, stressati o contenti. Questo articolo presenta un nuovo framework di intelligenza artificiale che interpreta le espressioni facciali umane in modo più accurato ed efficiente rispetto ai metodi precedenti, con l’obiettivo di rendere gli strumenti digitali più comprensivi, equi e utili nella vita quotidiana.
Come i volti offrono alle macchine una finestra sulle emozioni
I nostri volti trasmettono continuamente informazioni su come ci sentiamo, spesso in modo più sincero delle parole. Sorrisi, accigliature, occhi spalancati e microscopiche contrazioni muscolari aiutano le persone a orientarsi nelle conversazioni, costruire fiducia e individuare il disagio. Ricercatori in psicologia, neuroscienze e informatica hanno da tempo cercato di insegnare ai computer a leggere questi segnali, un campo noto come riconoscimento delle emozioni facciali. Questa tecnologia è già presente in piattaforme educative che monitorano l’impegno degli studenti, in videogiochi che si adattano all’umore del giocatore, in strumenti medici che valutano dolore o depressione e in sistemi di sicurezza che osservano segni di agitazione. Ma nelle condizioni reali le cose sono complicate: la luce cambia, i volti sono parzialmente coperti e le espressioni variano tra individui e culture, rendendo affidabile la lettura delle emozioni una sfida difficile.
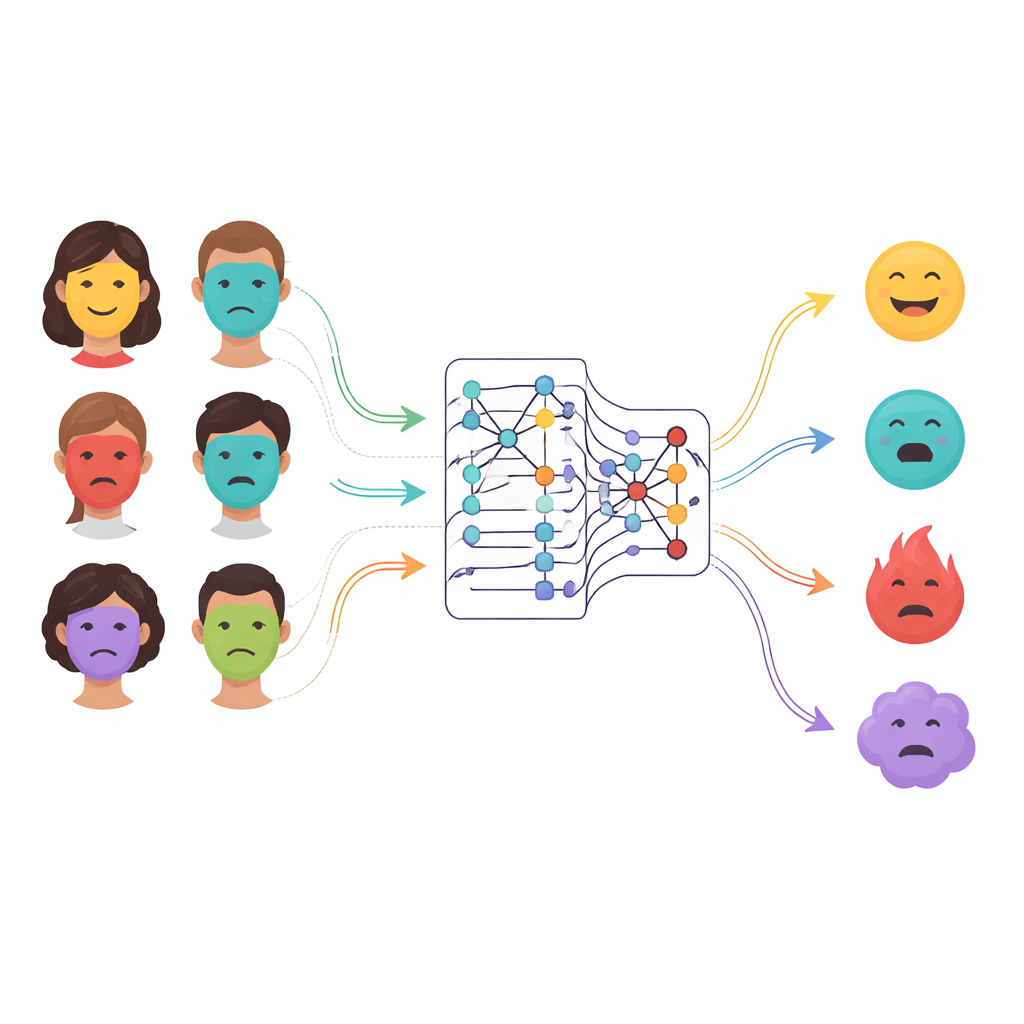
Perché i sistemi di riconoscimento emotivo più vecchi non bastano
I primi sistemi informatici si basavano su regole progettate a mano, misurando caratteristiche semplici come rughe, contorni o la forma di bocca e occhi. Questi approcci faticavano con i cambiamenti di posa, illuminazione o differenze individuali. Il deep learning ha fatto progressi permettendo alle reti neurali di apprendere automaticamente pattern utili dalle immagini dei volti, ma le architetture comuni presentavano ancora punti ciechi. Le reti convoluzionali eccellono nel riconoscere dettagli locali, ma hanno difficoltà a collegare parti distanti del volto, ad esempio come occhi e bocca si muovono insieme in un’espressione mista. I modelli transformer più recenti catturano queste relazioni a lungo raggio, ma possono essere pesanti, richiedere molti dati e non essere ideali nel cogliere dettagli molto sottili e di basso livello. Molti sistemi esistenti richiedono inoltre una messa a punto manuale accurata di centinaia di parametri interni e spesso generalizzano male al di fuori dei dati su cui sono stati addestrati.
Un nuovo approccio a doppio occhio e centrato sull’attenzione
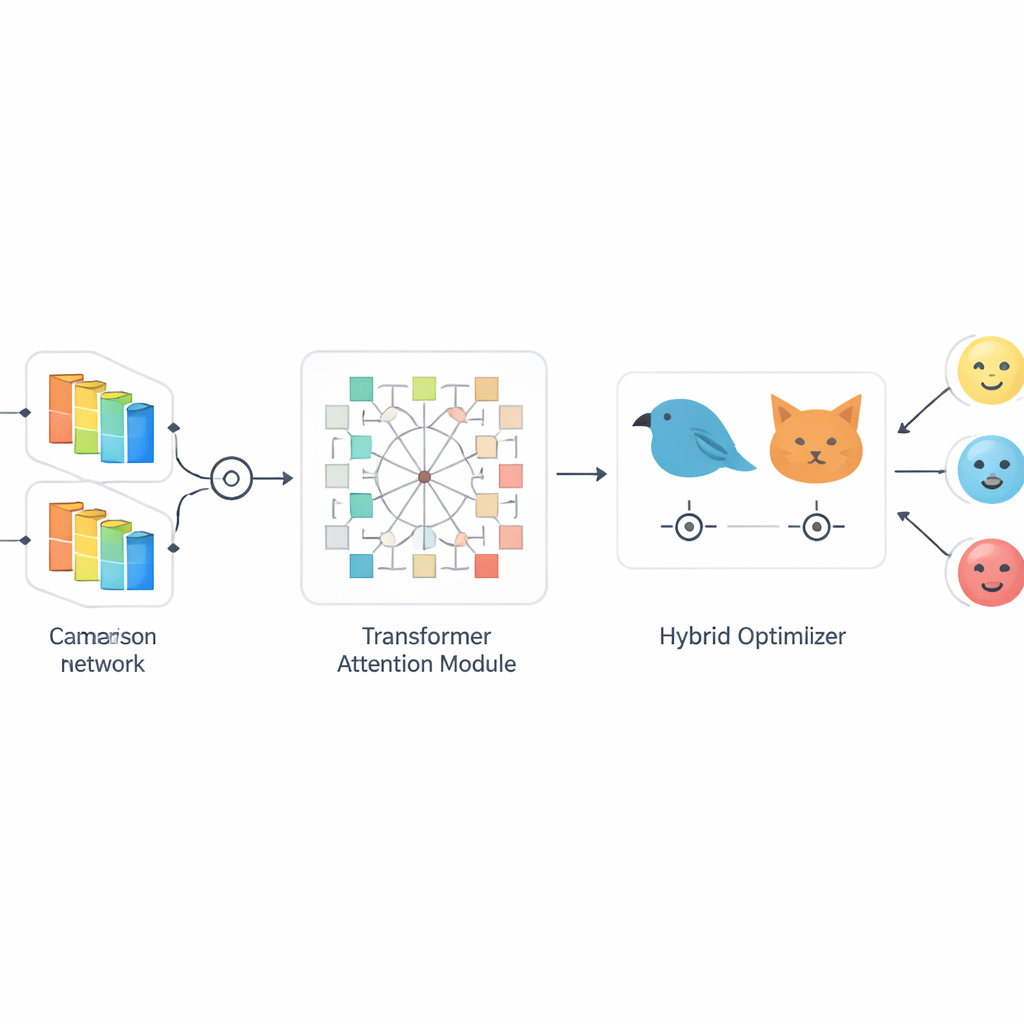
Gli autori propongono SiaCon-DetNet, una rete ibrida che combina i punti di forza di diverse idee. Innanzitutto utilizza una struttura siamese—due rami di elaborazione identici che osservano immagini del volto corrispondenti—per imparare cosa distingue davvero un’emozione dall’altra. Questo design gemello aiuta il modello a notare piccole differenze tra, per esempio, paura e sorpresa, che possono coinvolgere muscoli simili. All’interno di ogni ramo, strati convoluzionali catturano texture e forme fini, come le curve delle sopracciglia o la tensione delle labbra. Soprattutto, un modulo basato su transformer agisce come un faro di attenzione, imparando come regioni distanti del volto si correlano tra loro e concentrandosi sulle zone più informative. Insieme, questi componenti permettono al sistema di costruire un quadro ricco e consapevole del contesto di ogni espressione, anche quando i volti sono parzialmente nascosti o illuminati in modo disomogeneo.
Tuning ispirato alla natura per un apprendimento più netto e veloce
Progettare un modello potente è solo metà della sfida; va anche messo a punto in modo che apprenda rapidamente senza overfitting. Per affrontare questo aspetto, l’articolo introduce HySHO, uno schema di ottimizzazione «bio-ispirato» che combina strategie modellate su un uccello da caccia (il nibbio o il gheppio settentrionale) e su un felino del deserto. Una parte esplora un ampio ventaglio di configurazioni, come tassi di apprendimento e dimensioni dei filtri, evitando che il sistema resti bloccato in soluzioni scadenti. L’altra parte effettua aggiustamenti di precisione nelle regioni più promettenti, accelerando la convergenza. Questo tuning dinamico è legato a quanto variano le espressioni facciali in un dato dataset, permettendo al modello di adattarsi quando incontra emozioni sottili, miste o rumorose. Di conseguenza, l’addestramento diventa sia più rapido sia più robusto, favorendo applicazioni in tempo reale o quasi in tempo reale.
Mettere il sistema alla prova
Per valutare il loro framework, i ricercatori lo hanno testato su tre dataset di emozioni ampiamente usati, che differiscono per dimensione e difficoltà. Queste collezioni includono espressioni posate e più naturali attraverso diverse emozioni di base come rabbia, paura, felicità, tristezza, disgusto, sorpresa e neutralità. Il nuovo sistema ha raggiunto circa il 99 percento di accuratezza sul benchmark più noto e ha mantenuto altrettanto impressionanti valori di precision, recall e F1-score su quasi tutte le categorie emotive. Importante, ha fatto ciò addestrandosi più rapidamente di molti popolari modelli di deep learning basati su architetture di immagini ben conosciute. Le analisi di come le diverse emozioni si correlano in ciascun dataset hanno mostrato che il modello gestisce coppie delicate—come rabbia contro disgusto o paura contro tristezza—senza grandi cali di prestazione, suggerendo che cattura la struttura fine delle espressioni piuttosto che memorizzare i casi ovvi.
Cosa significa per la tecnologia di tutti i giorni
In termini semplici, lo studio dimostra che un’IA può essere progettata per «guardare» i volti in modo più simile a come fa un essere umano—confrontando differenze sottili, comprendendo il contesto su tutto il volto e adattando la propria strategia di apprendimento al volo. Il framework proposto SiaCon-DetNet con HySHO offre un’accuratezza estremamente elevata rimanendo relativamente leggero e rapido da addestrare, rendendolo un forte candidato per futuri strumenti di screening della salute mentale, tutoraggio interattivo, assistenza clienti e tecnologie assistive per persone con difficoltà di comunicazione. Pur essendo ancora aperte questioni importanti su privacy, consenso ed equità, questo lavoro avvicina i sistemi consapevoli delle emozioni alla capacità di leggere i nostri stati d’animo con affidabilità sufficiente per rispondere con sensibilità anziché con approssimazione.
Citazione: M, S., M, U., K, T. et al. SiaCon-DetNet with HySHO: a cutting-edge transformer-based deep learning framework for emotion-aware facial recognition. Sci Rep 16, 14131 (2026). https://doi.org/10.1038/s41598-026-41890-9
Parole chiave: riconoscimento delle emozioni facciali, deep learning, modelli transformer, interazione uomo–computer, computazione affettiva