Clear Sky Science · de
SiaCon-DetNet mit HySHO: ein hochmodernes, transformer-basiertes Deep-Learning-Framework für emotionsbewusste Gesichtserkennung
Warum es wichtig ist, Maschinen das Lesen von Gefühlen beizubringen
Von Videokonferenzen über virtuelle Tutoren bis hin zu Gesundheits-Apps begegnen wir Maschinen zunehmend über Bildschirme. Die meisten dieser Systeme sind jedoch noch emotional „taub“: Sie erkennen nicht, ob wir verwirrt, gestresst oder erfreut sind. Dieses Paper stellt ein neues künstliche-Intelligenz-Framework vor, das menschliche Gesichtsausdrücke genauer und effizienter erfasst als frühere Methoden und darauf abzielt, digitale Werkzeuge im Alltag verständnisvoller, gerechter und hilfreicher zu machen.
Wie Gesichter Maschinen ein emotionales Fenster öffnen
Unsere Gesichter senden kontinuierlich Informationen über unsere Gefühlslage aus, oft ehrlicher als unsere Worte. Lächeln, Stirnrunzeln, geweitete Augen und feine Muskelzuckungen helfen Menschen, Gespräche zu steuern, Vertrauen aufzubauen und Notlagen zu erkennen. Forschende aus Psychologie, Neurowissenschaften und Informatik versuchen seit langem, Computern diese Hinweise beizubringen — ein Feld, das als Gesichtsemotionserkennung bekannt ist. Solche Technologien finden sich bereits in Bildungsplattformen zur Messung der Schüler*innen-Engagements, in Spielen, die sich an die Stimmung des Spielers anpassen, in medizinischen Tools zur Überwachung von Schmerz oder Depression sowie in Sicherheitssystemen, die nach Anzeichen von Unruhe suchen. Unter realen Bedingungen ist die Lage jedoch kompliziert: Lichtverhältnisse ändern sich, Gesichter sind teilweise verdeckt, und Ausdrücke variieren zwischen Individuen und Kulturen, wodurch zuverlässiges Emotionserkennen eine Herausforderung bleibt.
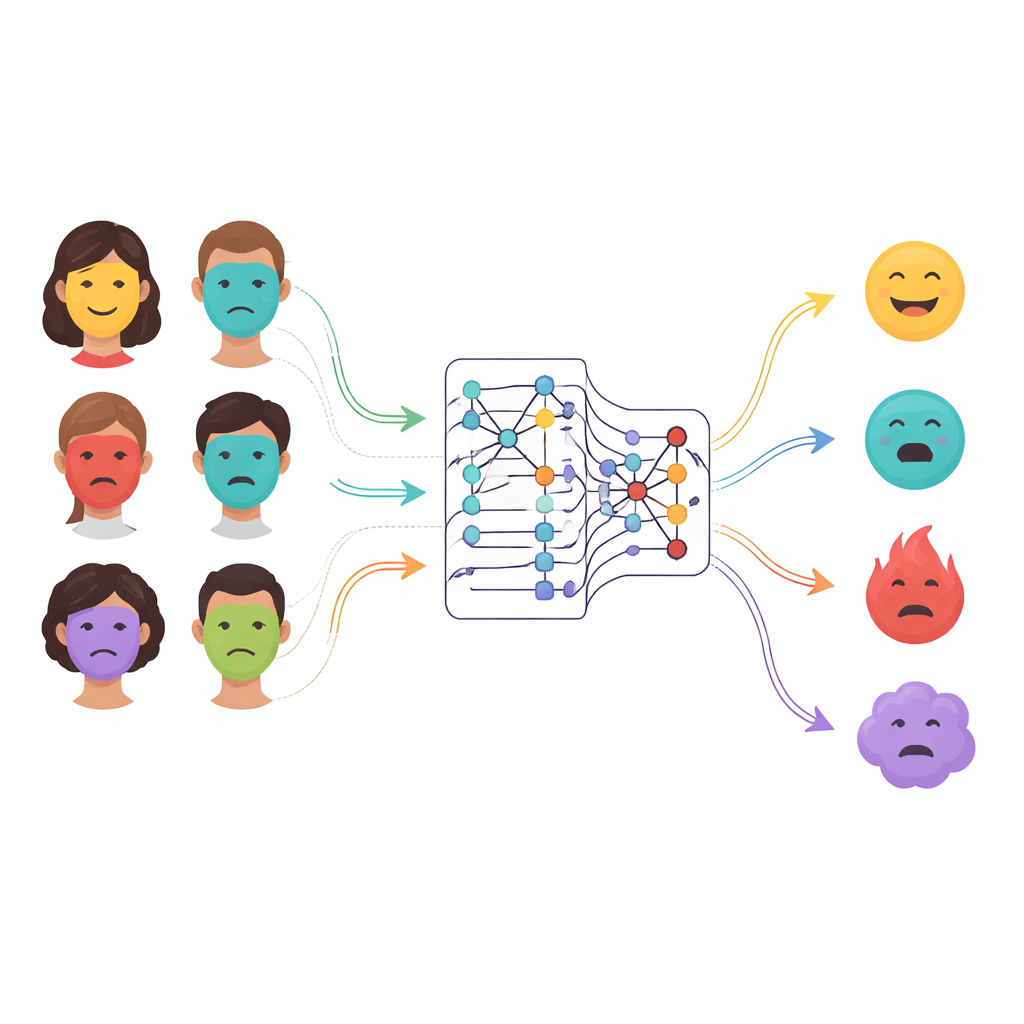
Warum ältere Emotionssysteme nicht ausreichen
Frühe Computersysteme stützten sich auf von Menschen entworfene Regeln und maßen einfache Merkmale wie Falten, Kanten oder die Form von Mund und Augen. Diese Methoden hatten Probleme bei Änderungen der Kopfhaltung, Beleuchtung oder individuellen Unterschieden. Deep Learning brachte Fortschritte, weil neuronale Netze automatisch nützliche Muster aus Gesichtsaufnahmen lernen können, aber gängige Architekturen haben weiterhin Schwachstellen. Konvolutionale Netze sind gut darin, lokale Details zu erkennen, tun sich jedoch schwer damit, weit auseinanderliegende Teile des Gesichts miteinander in Beziehung zu setzen — etwa wie Augen und Mund gemeinsam in einem gemischten Ausdruck reagieren. Neuere Transformer-Modelle erfassen diese fernreichenden Zusammenhänge, können aber rechnerisch aufwendig, datenhungrig und weniger gut darin sein, sehr feine, niedrigstufige Details zu erfassen. Viele bestehende Systeme erfordern außerdem aufwändige manuelle Abstimmung hunderter internter Parameter und generalisieren oft schlecht über die Trainingsdaten hinaus.
Ein neuer, doppelt betrachtender und auf Aufmerksamkeit fokussierter Ansatz
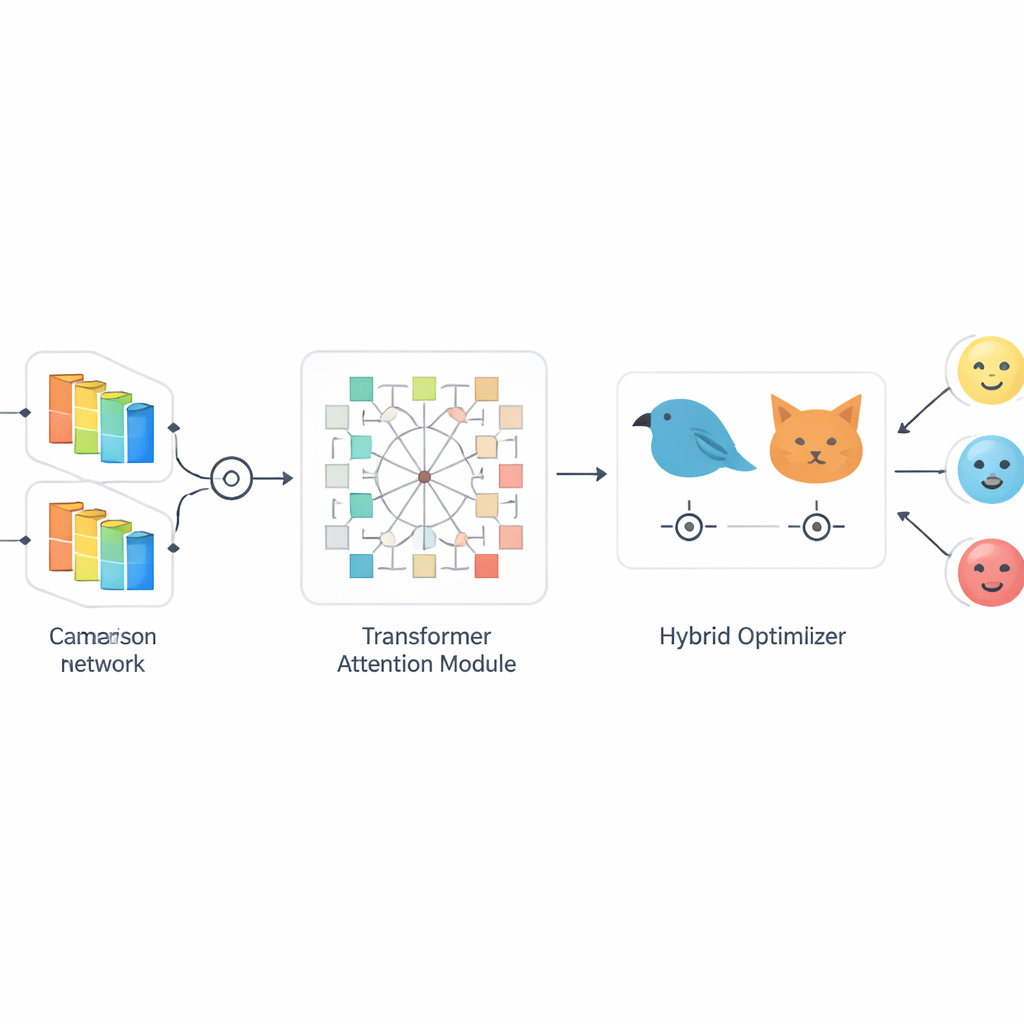
Die Autor*innen schlagen SiaCon-DetNet vor, ein hybrides Netzwerk, das die Stärken mehrerer Ideen kombiniert. Zunächst verwendet es eine Siamese-Struktur — zwei identische Verarbeitungspfad, die passende Gesichtsabbildungen vergleichen — um zu lernen, was Emotionen tatsächlich unterscheidet. Dieses Zwillingsdesign hilft dem Modell, winzige Unterschiede zu erkennen, etwa zwischen Angst und Überraschung, die ähnliche Muskelbewegungen enthalten können. Innerhalb jedes Zweigs erfassen konvolutionale Schichten feinkörnige Texturen und Formen wie Augenbrauenkrümmungen oder Mundspannung. Darüber legt ein transformerbasiertes Modul eine Art Aufmerksamkeits-Scheinwerfer, der lernt, wie weit entfernte Bereiche des Gesichts zueinander in Beziehung stehen, und sich auf die informativsten Zonen konzentriert. Zusammen ermöglichen diese Komponenten dem System, ein reiches, kontextsensitives Bild jedes Ausdrucks zu erstellen — selbst wenn Gesichter teilweise verdeckt oder ungleichmäßig beleuchtet sind.
Von der Natur inspirierte Optimierung für schärferes und schnelleres Lernen
Ein leistungsfähiges Modell zu entwerfen ist nur die halbe Miete; es muss auch so abgestimmt werden, dass es schnell lernt, ohne zu überanpassen. Zur Lösung dieses Problems führt das Paper HySHO ein, ein „bio-inspiriertes“ Optimierungsschema, das Strategien kombiniert, die an einen Jagdvogel (Wespenbussard) und eine Wüstenkatze erinnern. Ein Teil erkundet ein breites Feld von Einstellungen wie Lernraten und Filtergrößen und verhindert, dass das System in schlechten Lösungen stecken bleibt. Der andere Teil nimmt feinere Anpassungen in vielversprechenden Regionen vor und beschleunigt so die Konvergenz. Diese dynamische Abstimmung steht in Verbindung mit dem Ausmaß, in dem Gesichtsausdrücke innerhalb eines Datensatzes variieren, sodass sich das Modell selbst an subtile, gemischte oder verrauschte Emotionen anpassen kann. Dadurch wird das Training sowohl schneller als auch robuster, was Echtzeit- oder nahezu Echtzeit-Anwendungen unterstützt.
Erprobung des Systems
Um ihr Framework zu bewerten, testeten die Forschenden es an drei weit verbreiteten Emotionsdatensätzen, die sich in Größe und Schwierigkeit unterscheiden. Diese Sammlungen enthalten gestellte und natürlichere Ausdrücke über mehrere Basisemotionen hinweg wie Ärger, Angst, Glück, Traurigkeit, Ekel, Überraschung und Neutralität. Das neue System erreichte auf dem bekanntesten Benchmark rund 99 Prozent Genauigkeit und zeigte gleichermaßen beeindruckende Präzisions-, Recall- und F1-Werte über nahezu alle Emotionskategorien. Wichtig ist, dass es dies erreichte, während das Training schneller verlief als bei vielen populären Deep-Learning-Modellen auf bekannten Bildarchitekturen. Analysen der Korrelationen zwischen verschiedenen Emotionen in den Datensätzen zeigten, dass das Modell schwierige Paare — etwa Ärger versus Ekel oder Angst versus Traurigkeit — ohne große Einbußen in der Leistung behandelte, was darauf hindeutet, dass es die feine Struktur von Ausdrücken erfasst und nicht nur offensichtliche Fälle auswendig lernt.
Was das für Alltags-Technologie bedeutet
Einfach gesagt zeigt die Studie, dass KI so gestaltet werden kann, dass sie Gesichter auf eine menschlichere Weise „anschaut“ — subtile Unterschiede vergleicht, Kontext über das gesamte Gesicht versteht und die eigene Lernstrategie dynamisch anpasst. Das vorgestellte SiaCon-DetNet mit HySHO liefert extrem hohe Genauigkeit bei vergleichsweise geringer Komplexität und schneller Trainingszeit und ist damit ein vielversprechender Kandidat für zukünftige Anwendungen in der psychischen Gesundheitsvorsorge, interaktiven Lehrsystemen, Kundenservice und assistiven Technologien für Menschen mit Kommunikationsschwierigkeiten. Obwohl wichtige Fragen zu Privatsphäre, Einwilligung und Fairness offen bleiben, rückt diese Arbeit emotionsbewusste Systeme näher an die Fähigkeit, unsere Gefühle verlässlich genug zu erkennen, um mit Sensibilität statt mit Vermutungen zu reagieren.
Zitation: M, S., M, U., K, T. et al. SiaCon-DetNet with HySHO: a cutting-edge transformer-based deep learning framework for emotion-aware facial recognition. Sci Rep 16, 14131 (2026). https://doi.org/10.1038/s41598-026-41890-9
Schlüsselwörter: Erkennung von Gesichtsemotionen, Deep Learning, Transformer-Modelle, Mensch–Computer-Interaktion, affektive Informatik