Clear Sky Science · fr
SiaCon-DetNet avec HySHO : un cadre d’apprentissage profond basé sur des transformers pour la reconnaissance faciale sensible aux émotions
Pourquoi apprendre aux ordinateurs à lire les émotions compte
Des appels vidéo aux tuteurs virtuels en passant par les applications de santé, nous interagissons de plus en plus avec des machines via des écrans. Pourtant, la plupart de ces systèmes restent émotionnellement « sourds » : ils ne perçoivent pas si nous sommes confus, stressés ou ravis. Cet article présente un nouveau cadre d’intelligence artificielle qui lit les expressions faciales humaines de manière plus précise et plus efficace que les méthodes précédentes, dans le but de rendre les outils numériques plus compréhensifs, équitables et utiles au quotidien.
Comment les visages offrent une fenêtre émotionnelle aux machines
Nos visages diffusent en continu des informations sur ce que nous ressentons, souvent plus honnêtement que nos mots. Les sourires, les froncements, les yeux agrandis et les micro‑tics musculaires aident les gens à conduire une conversation, instaurer la confiance et détecter la détresse. Les chercheurs en psychologie, neurosciences et informatique tentent depuis longtemps d’apprendre aux ordinateurs à lire ces signaux, un domaine connu sous le nom de reconnaissance des émotions faciales. Cette technologie existe déjà dans des plateformes éducatives qui suivent l’engagement des étudiants, des jeux qui s’adaptent à l’humeur du joueur, des outils médicaux qui surveillent la douleur ou la dépression, et des systèmes de sécurité qui cherchent des signes d’agitation. Mais les conditions réelles sont chaotiques : l’éclairage change, les visages sont parfois partiellement couverts et les expressions varient selon les individus et les cultures, rendant la lecture fiable des émotions difficile.
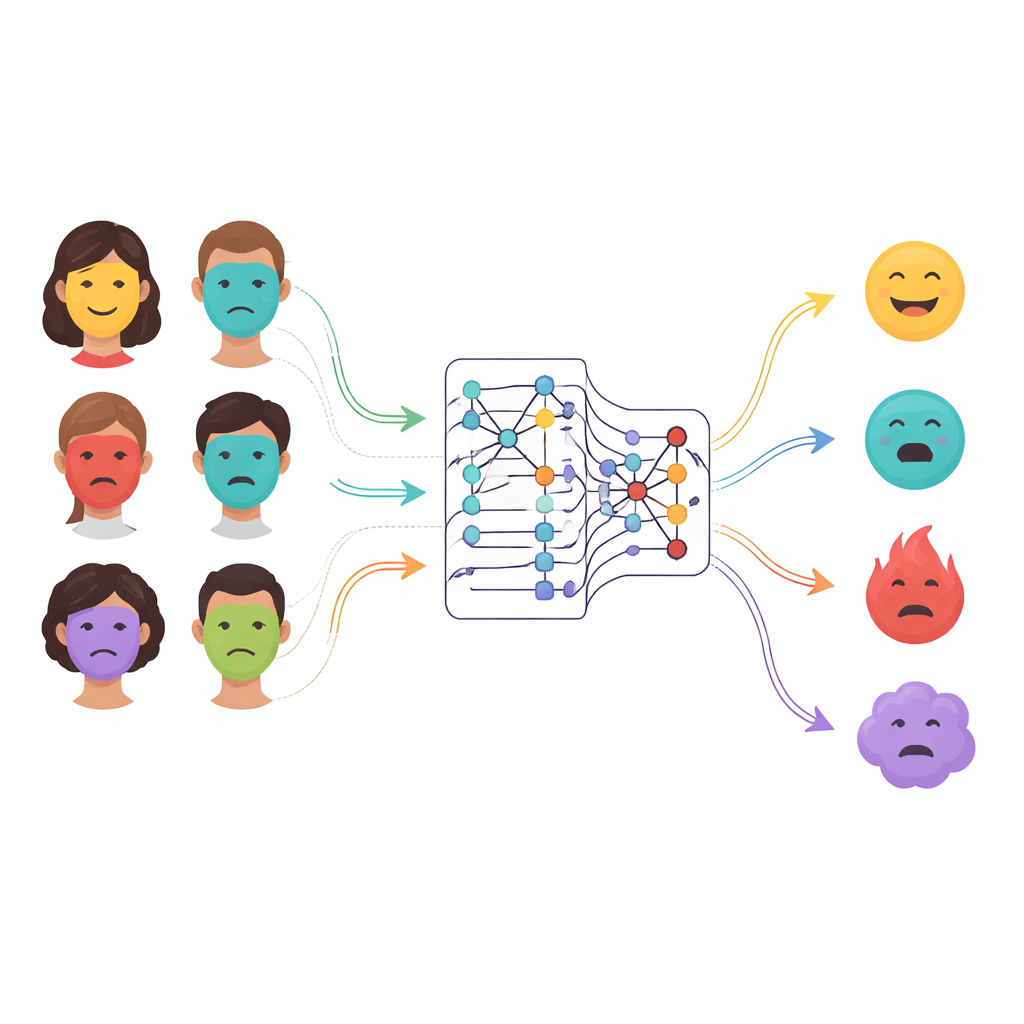
Pourquoi les anciens systèmes émotionnels sont insuffisants
Les premiers systèmes informatiques reposaient sur des règles conçues manuellement, mesurant des caractéristiques simples comme les rides, les contours ou la forme de la bouche et des yeux. Ils peinaient face aux changements de pose, d’éclairage ou aux différences individuelles. L’apprentissage profond a permis des progrès en laissant les réseaux neuronaux apprendre automatiquement des motifs utiles à partir d’images de visages, mais les architectures courantes présentaient encore des limites. Les réseaux convolutifs excellent pour repérer des détails locaux, mais ont du mal à relier des parties éloignées du visage, par exemple la manière dont les yeux et la bouche bougent ensemble dans une expression mixte. Les modèles transformer récents captent ces relations à longue portée, mais peuvent être lourds, gourmands en données et moins efficaces pour saisir des détails très fins et de bas niveau. Nombre de systèmes existants exigent également un réglage manuel minutieux de centaines de paramètres internes et généralisent souvent mal au‑delà des données sur lesquelles ils ont été entraînés.
Une approche à deux yeux et centrée sur l’attention
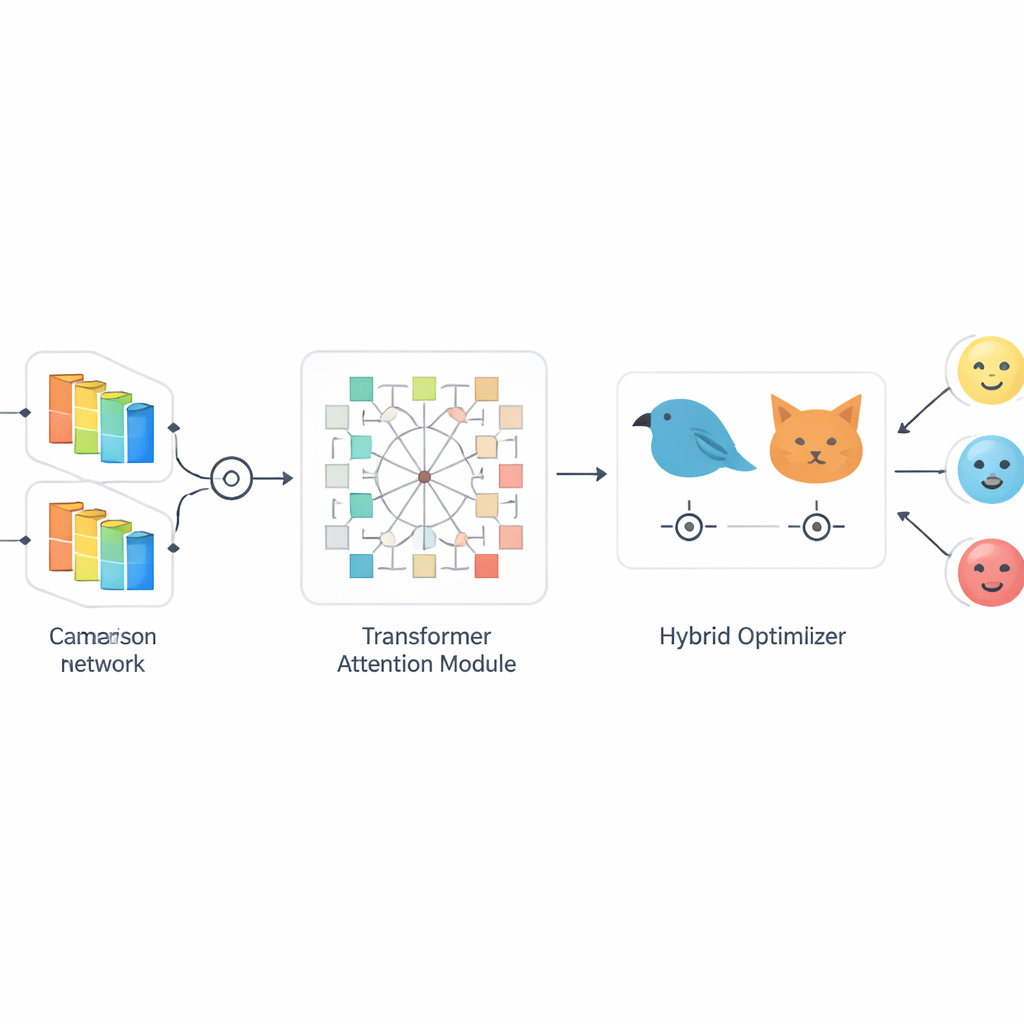
Les auteurs proposent SiaCon-DetNet, un réseau hybride qui combine les forces de plusieurs idées. D’abord, il utilise une structure siamoise — deux branches de traitement identiques qui voient des images de visages appariées — pour apprendre ce qui distingue vraiment une émotion d’une autre. Cette conception jumelle aide le modèle à remarquer de minuscules différences entre, par exemple, la peur et la surprise, qui peuvent impliquer des muscles similaires. Dans chaque branche, des couches convolutionnelles capturent des textures et des formes fines, comme la courbure des sourcils ou la tension de la bouche. Au‑dessus, un module basé sur les transformers agit comme un projecteur d’attention, apprenant comment des régions éloignées du visage se relient entre elles et se focalisant sur les zones les plus informatives. Ensemble, ces composants permettent au système de construire une représentation riche et contextuelle de chaque expression, même lorsque les visages sont partiellement cachés ou éclairés de façon inégale.
Un réglage inspiré de la nature pour un apprentissage plus net et plus rapide
Concevoir un modèle puissant ne suffit pas ; il doit aussi être réglé pour apprendre rapidement sans surapprentissage. Pour cela, l’article introduit HySHO, un schéma d’optimisation « bio‑inspiré » qui mêle des stratégies modélisées sur un oiseau de proie (le épervier / crécerelle) et un félin du désert. Une partie explore une vaste plage de paramètres, comme les taux d’apprentissage et les tailles des filtres, empêchant le système de rester bloqué dans de mauvaises solutions. L’autre partie réalise des ajustements fins dans les régions prometteuses, accélérant la convergence. Ce réglage dynamique est lié à la variabilité des expressions faciales dans un jeu de données donné, permettant au modèle de s’adapter lorsqu’il rencontre des émotions subtiles, mixtes ou bruitées. En conséquence, l’entraînement devient à la fois plus rapide et plus robuste, ce qui favorise des applications en temps réel ou quasi temps réel.
Évaluation du système
Pour évaluer leur cadre, les chercheurs l’ont testé sur trois ensembles de données d’émotions largement utilisés et de difficultés variées. Ces collections incluent des expressions posées et plus naturelles couvrant plusieurs émotions de base telles que la colère, la peur, la joie, la tristesse, le dégoût, la surprise et la neutralité. Le nouveau système a atteint environ 99 % de précision sur le benchmark le plus connu et a maintenu des scores de précision, rappel et F1 également impressionnants pour presque toutes les catégories émotionnelles. Fait important, il y est parvenu tout en s’entraînant plus rapidement que de nombreux modèles d’apprentissage profond populaires basés sur des architectures d’image bien établies. Les analyses des corrélations entre émotions dans chaque jeu de données montrent que le modèle gère des paires difficiles — comme colère contre dégoût ou peur contre tristesse — sans fortes baisses de performance, ce qui suggère qu’il capture la structure fine des expressions plutôt que de mémoriser des cas évidents.
Ce que cela signifie pour la technologie du quotidien
En termes simples, l’étude montre qu’il est possible de concevoir une IA qui « regarde » les visages d’une manière plus humaine — en comparant des différences subtiles, en comprenant le contexte à l’échelle du visage entier et en ajustant sa stratégie d’apprentissage en temps réel. Le cadre SiaCon-DetNet avec HySHO offre une très grande précision tout en restant relativement léger et rapide à entraîner, en faisant un candidat solide pour des outils futurs de dépistage en santé mentale, de tutorat interactif, de service client et de technologies d’assistance pour les personnes ayant des difficultés de communication. Bien que des questions importantes subsistent concernant la vie privée, le consentement et l’équité, ce travail rapproche les systèmes sensibles aux émotions d’une lecture de nos sentiments suffisamment fiable pour répondre avec nuance plutôt qu’avec des approximations.
Citation: M, S., M, U., K, T. et al. SiaCon-DetNet with HySHO: a cutting-edge transformer-based deep learning framework for emotion-aware facial recognition. Sci Rep 16, 14131 (2026). https://doi.org/10.1038/s41598-026-41890-9
Mots-clés: reconnaissance des émotions faciales, apprentissage profond, modèles transformer, interaction homme‑machine, informatique affective