Clear Sky Science · es
SiaCon-DetNet con HySHO: un marco de aprendizaje profundo basado en transformadores de vanguardia para el reconocimiento facial consciente de emociones
Por qué importa enseñar a las máquinas a leer las emociones
Desde llamadas por video hasta tutores virtuales y aplicaciones de salud, cada vez interactuamos más con máquinas a través de pantallas. Sin embargo, la mayoría de estos sistemas siguen siendo emocionalmente “sordos”: no detectan si estamos confundidos, estresados o contentos. Este artículo presenta un nuevo marco de inteligencia artificial que interpreta las expresiones faciales humanas con mayor precisión y eficiencia que métodos anteriores, con el objetivo de que las herramientas digitales sean más comprensivas, justas y útiles en la vida cotidiana.
Cómo los rostros ofrecen una ventana emocional a las máquinas
Nuestros rostros transmiten continuamente información sobre cómo nos sentimos, a menudo con más honestidad que las palabras. Sonrisas, ceños fruncidos, ojos abiertos y pequeños espasmos musculares ayudan a las personas a gestionar conversaciones, generar confianza y detectar angustia. Investigadores en psicología, neurociencia e informática llevan tiempo intentando enseñar a las máquinas a leer estas señales, un campo conocido como reconocimiento de emociones faciales. Esta tecnología ya aparece en plataformas educativas que rastrean la atención estudiantil, en juegos que se adaptan al estado de ánimo del jugador, en herramientas médicas que monitorean dolor o depresión y en sistemas de seguridad que buscan signos de agitación. Pero las condiciones del mundo real son desordenadas: la iluminación cambia, los rostros pueden estar parcialmente cubiertos y las expresiones varían entre individuos y culturas, lo que convierte la lectura fiable de emociones en un reto difícil.
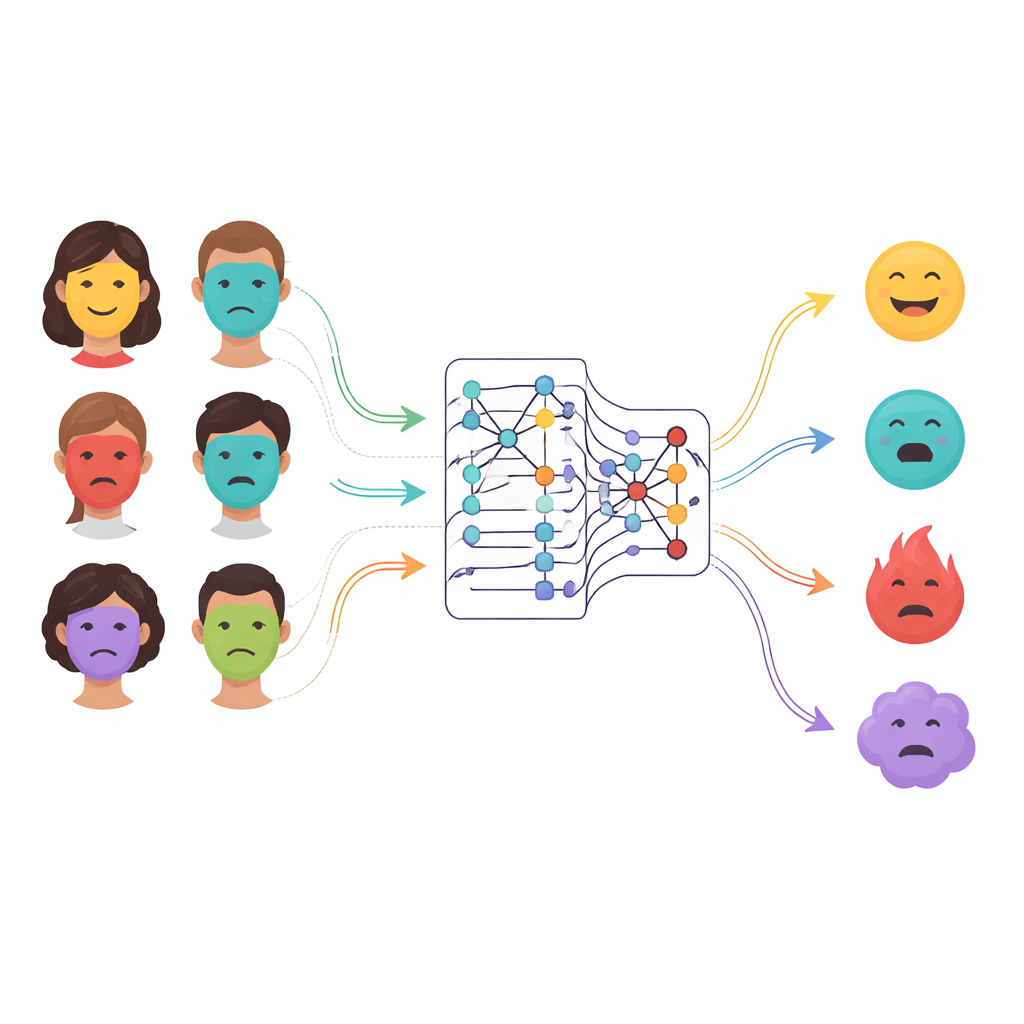
Por qué los sistemas antiguos de detección emocional se quedan cortos
Los primeros sistemas informáticos dependían de reglas diseñadas a mano, midiendo características simples como arrugas, bordes o la forma de la boca y los ojos. Estos fallaban ante cambios de pose, iluminación o diferencias individuales. El aprendizaje profundo supuso un avance al permitir que las redes neuronales aprendieran automáticamente patrones útiles a partir de imágenes faciales, pero las arquitecturas comunes aún tenían puntos ciegos. Las redes convolucionales son excelentes para detectar detalles locales, pero les cuesta relacionar partes distantes del rostro, como cómo se mueven conjuntamente ojos y boca en una expresión mixta. Los modelos transformadores más recientes capturan estas relaciones a largo alcance, pero pueden ser pesados, requerir muchos datos y no ser ideales para captar detalles finos a bajo nivel. Muchos sistemas existentes también exigen un ajuste manual cuidadoso de cientos de parámetros internos y a menudo generalizan mal fuera de los datos con los que se entrenaron.
Un nuevo enfoque de doble mirada y atención focalizada
Los autores proponen SiaCon-DetNet, una red híbrida que combina las fortalezas de varias ideas. Primero, emplea una estructura siamés—dos ramas de procesamiento idénticas que ven imágenes faciales emparejadas—para aprender qué distingue realmente una emoción de otra. Este diseño gemelo ayuda al modelo a notar diferencias diminutas entre, por ejemplo, miedo y sorpresa, que pueden implicar músculos similares. Dentro de cada rama, las capas convolucionales capturan texturas y formas de alta resolución, como las curvas de las cejas o la tensión de la boca. Sobre esto, un módulo basado en transformadores actúa como un foco de atención, aprendiendo cómo se relacionan regiones distantes del rostro y concentrándose en las zonas más informativas. Juntos, estos componentes permiten al sistema construir una imagen rica y con contexto de cada expresión, incluso cuando los rostros están parcialmente ocultos o iluminados de forma desigual.
Ajuste inspirado en la naturaleza para un aprendizaje más nítido y rápido
Diseñar un modelo potente es solo la mitad de la batalla; también debe ajustarse para que aprenda rápido sin sobreajustarse. Para ello, el artículo presenta HySHO, un esquema de optimización “bioinspirado” que mezcla estrategias modeladas en un ave rapaz (gavilán norteño) y un felino del desierto. Una parte explora una amplia gama de configuraciones, como tasas de aprendizaje y tamaños de filtros, evitando que el sistema quede atrapado en soluciones pobres. La otra realiza ajustes finos en regiones prometedoras, acelerando la convergencia. Este ajuste dinámico se vincula a cuánto varían las expresiones faciales en un conjunto de datos dado, permitiendo que el modelo se adapte cuando encuentra emociones sutiles, mixtas o ruidosas. Como resultado, el entrenamiento se vuelve tanto más rápido como más robusto, lo que respalda aplicaciones en tiempo real o casi en tiempo real.
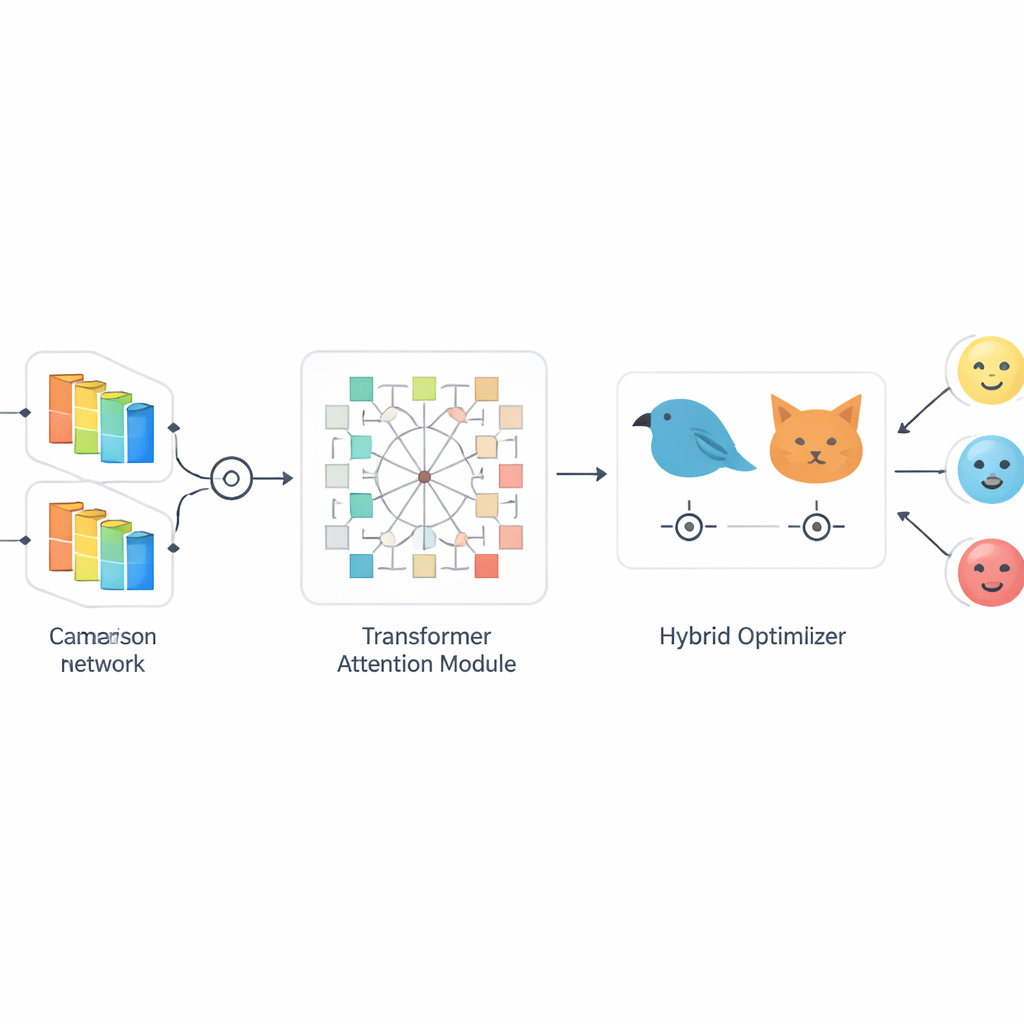
Poniendo el sistema a prueba
Para evaluar su marco, los investigadores lo probaron en tres conjuntos de datos de emociones ampliamente usados que difieren en tamaño y dificultad. Estas colecciones incluyen expresiones posadas y más naturales a través de varias emociones básicas como ira, miedo, alegría, tristeza, asco, sorpresa y neutralidad. El nuevo sistema alcanzó alrededor del 99 por ciento de precisión en el banco de pruebas más conocido y mantuvo niveles igualmente impresionantes de precisión, recall y puntuaciones F1 en casi todas las categorías emocionales. Es importante destacar que lo consiguió mientras se entrenaba más rápido que muchos modelos populares de aprendizaje profundo construidos sobre arquitecturas de imagen conocidas. Los análisis de cómo se correlacionan distintas emociones en cada conjunto mostraron que el modelo manejó pares difíciles—como ira frente a asco o miedo frente a tristeza—sin caídas significativas en el rendimiento, lo que sugiere que captura la estructura fina de las expresiones en lugar de memorizar casos obvios.
Qué significa esto para la tecnología cotidiana
En términos sencillos, el estudio muestra que se puede diseñar una IA para “mirar” los rostros de manera más parecida a la humana—comparando diferencias sutiles, entendiendo el contexto en todo el rostro y ajustando su propia estrategia de aprendizaje sobre la marcha. El marco propuesto SiaCon-DetNet con HySHO ofrece una precisión extremadamente alta mientras se mantiene relativamente ligero y rápido de entrenar, lo que lo convierte en un candidato sólido para futuras herramientas en cribado de salud mental, tutoría interactiva, atención al cliente y tecnologías de asistencia para personas con dificultades de comunicación. Aunque siguen existiendo cuestiones importantes sobre privacidad, consentimiento y equidad, este trabajo acerca a los sistemas conscientes de las emociones a la capacidad de leer nuestros sentimientos con la fiabilidad suficiente como para responder con sensibilidad en lugar de conjeturas.
Cita: M, S., M, U., K, T. et al. SiaCon-DetNet with HySHO: a cutting-edge transformer-based deep learning framework for emotion-aware facial recognition. Sci Rep 16, 14131 (2026). https://doi.org/10.1038/s41598-026-41890-9
Palabras clave: reconocimiento de emociones faciales, aprendizaje profundo, modelos transformadores, interacción humano–computadora, computación afectiva