Clear Sky Science · en
Pre-training genomic language model with variants for better modeling functional genomics
Teaching Computers to Read the Language of DNA
Each person’s DNA carries millions of tiny differences, or variants, that help shape everything from height to disease risk. Scientists know that many of these variants influence how strongly genes are turned on or off, but connecting the dots from DNA letters to gene activity has been difficult. This study introduces new artificial intelligence models that treat DNA like a language, using patterns of variants observed in hundreds of thousands of people to better predict how genes behave in specific cells and individuals.
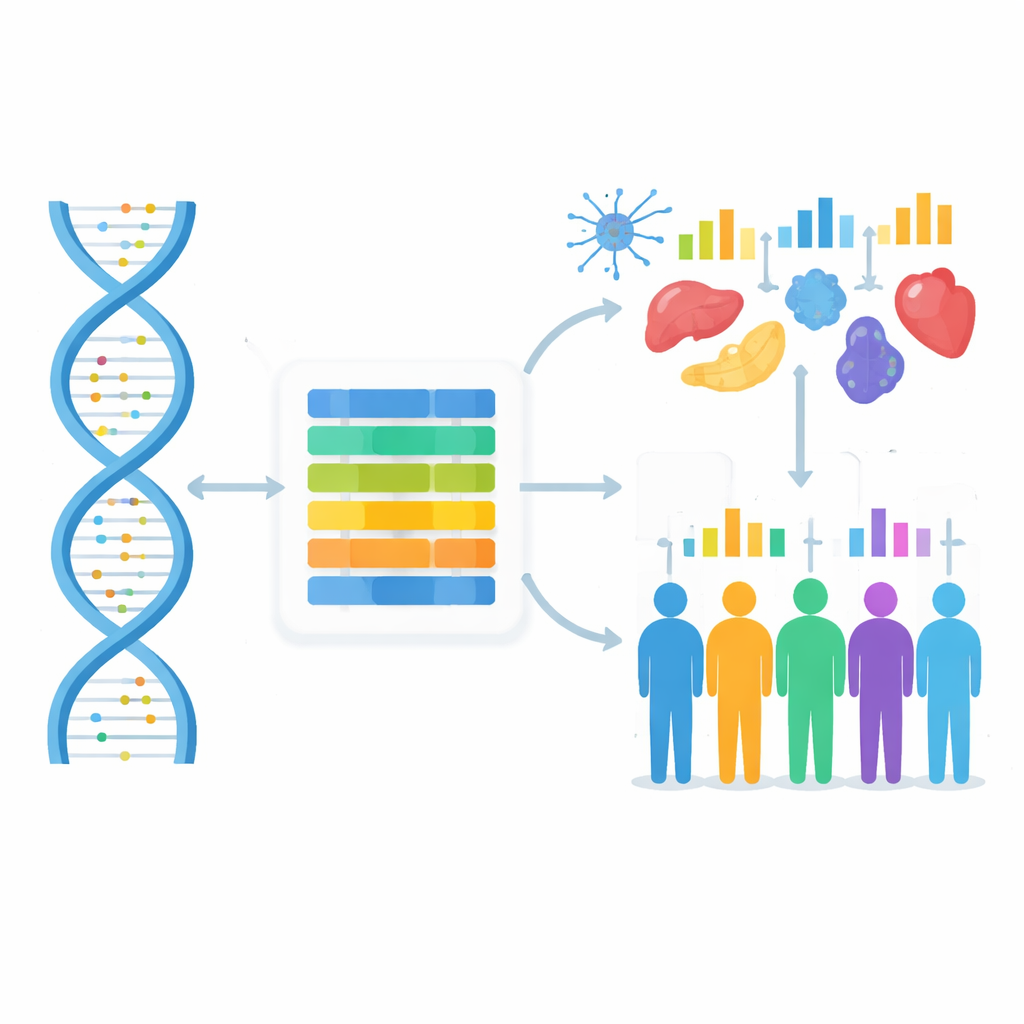
Why DNA Can Be Treated Like Human Language
Just as words take on different meanings depending on the surrounding sentence, stretches of DNA can play different roles depending on their genomic “context.” Regulatory regions can sit far from the genes they control, and the same piece of DNA may contribute to several biological functions. The authors build on the idea that these long-range patterns resemble the polysemy and context dependence seen in natural language. Using neural network architectures originally developed for text, they aim to learn how DNA “grammar” and human genetic variation together shape gene function and expression.
Building a Genomic Language Model from Real Human Variation
The researchers created UKBioBERT, a DNA language model trained on both the human reference genome and over 13 million variants from roughly 300,000 UK Biobank participants. During training, the model is shown modified DNA sequences where some bases are hidden and must be guessed from context, similar to filling in missing words in a sentence. This self-supervised process forces the model to internalize which sequence patterns tend to co-occur and how variants alter those patterns. The team then tests the model’s internal representations by asking whether sequences from genes with similar known functions end up close together in this learned space. By several clustering measures, UKBioBERT separates gene functions more clearly than previous genomic models, without ever being told those functions during training.
From Sequence Patterns to Gene Activity in Cells and People
Learning the “language” of DNA is useful only if it helps explain real biology, especially gene expression—the level at which genes are switched on in different cell types and individuals. The authors plug UKBioBERT’s sequence embeddings into existing deep-learning frameworks that predict gene activity from DNA. At the cell-line level, they enhance an architecture called EPInformer, which already combines promoter and enhancer sequences with epigenetic signals. Adding UKBioBERT’s DNA embeddings and separate text-based descriptions of gene function leads to more accurate predictions of gene expression in several human cell lines, with higher correlations between predicted and measured values and more stable performance across cross-validation splits.
Personalized Predictions and What Makes a Gene Predictable
The team then turns to a harder task: predicting gene expression for individual people based solely on their whole-genome sequences. They first use UKBioBERT embeddings with a traditional statistical method to predict expression for 41 representative genes in the GTEx cohort. Performance rivals or slightly trails strong baselines that use hand-crafted genetic features, and far exceeds an unfine-tuned sequence model. Intriguingly, genes differ widely in how predictable their expression is. This variation is not well explained by standard measures like heritability. Instead, genes whose expression levels naturally fall into clearer clusters across individuals—patterns that UKBioBERT’s embeddings can capture—tend to be more predictable. Genes involved in many different biological functions are harder to predict from sequence alone.
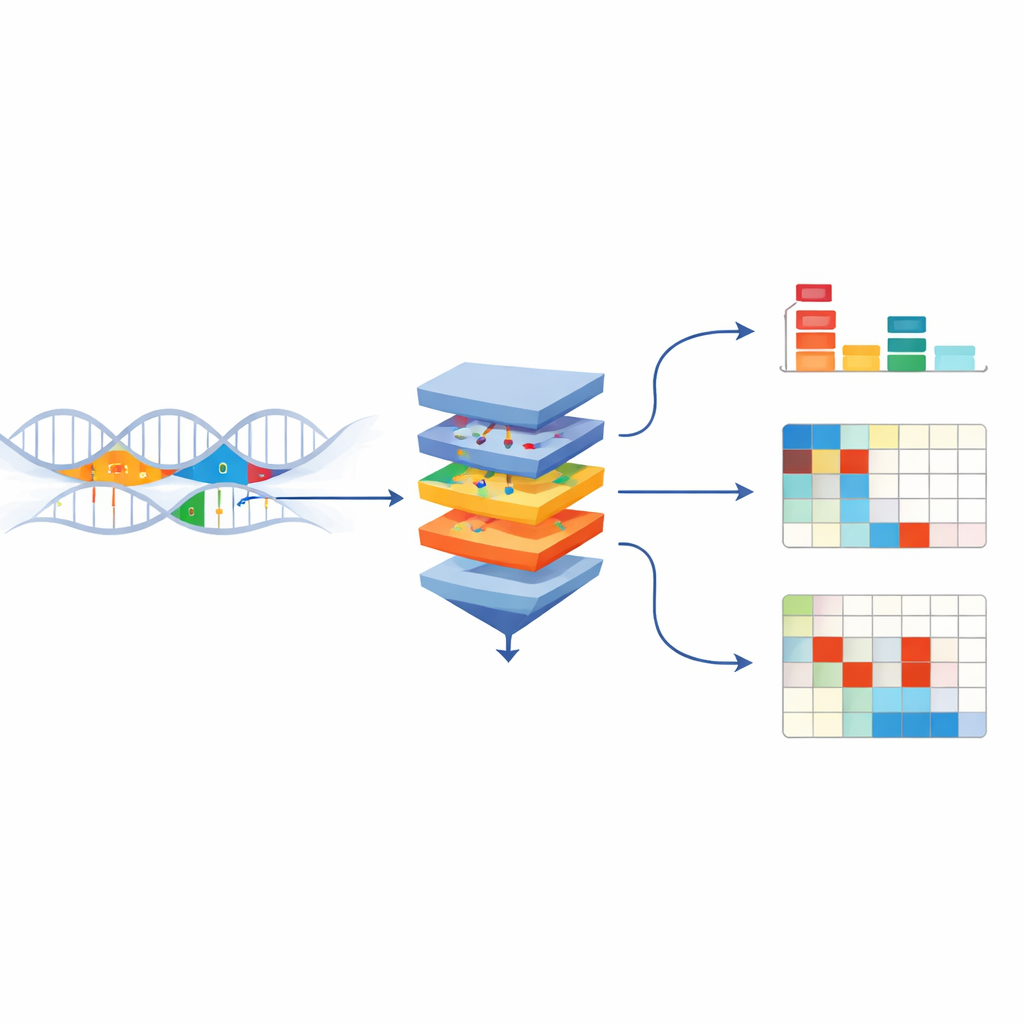
Fusing Models for Stronger Individual-Level Predictions
To push personalized prediction further, the authors fuse UKBioBERT with powerful sequence-to-function models Enformer and Borzoi, creating UKBioFormer and UKBioZoi. These hybrids combine long-range sequence modeling with variant-aware embeddings and are fine-tuned efficiently using parameter-saving techniques. Across the same gene set, UKBioFormer often outperforms both the previous best deep model (Performer) and standard statistical approaches for genes whose expression is reasonably predictable. It also shows improved generalization when models trained on people of European ancestry are applied to African American individuals, suggesting that learning from raw sequence plus population variants captures some shared regulatory logic across groups.
Seeing How Single Variants Change Gene Activity
Because UKBioFormer is a neural network, it can be probed to reveal how individual variants influence its predictions. The authors use gradient-based methods and in-silico mutation experiments to estimate how changing specific bases alters predicted expression. For several genes, including one called JUP, the model correctly infers the direction and approximate size of effects for a majority of known regulatory variants (eQTLs), including some rare ones. It also highlights local sequence motifs around these variants that match known binding patterns of regulatory proteins. This shows that the model is not merely fitting overall expression levels, but is learning mechanistic links between sequence motifs, variants, and gene regulation.
What This Work Means for Genomics and Medicine
This study demonstrates that training genomic language models directly on large collections of human variants yields richer DNA representations that improve gene expression prediction and variant interpretation. While not every gene is predictable from sequence alone, the combined UKBioBERT–UKBioFormer framework performs particularly well for genes whose expression patterns are structured and variant-driven. It also provides a practical way to explore which variants are most likely to alter gene activity before running costly experiments. As datasets become more diverse and methods for multi-gene training improve, such models could become important tools for linking personal genomes to molecular traits and, ultimately, for guiding research on genetically influenced diseases.
Citation: Liu, T., Zhang, X., Lin, J. et al. Pre-training genomic language model with variants for better modeling functional genomics. npj Artif. Intell. 2, 46 (2026). https://doi.org/10.1038/s44387-026-00103-4
Keywords: genomic language models, gene expression prediction, genetic variants, functional genomics, UK Biobank