Clear Sky Science · zh
通过基准测试与竞赛推进专业分诊的医疗人工智能
为何更智能的首诊地点很重要
当人们感觉不适时,他们的第一个问题通常很直接:“我应该去哪儿?”但选择错误的门诊或科室可能浪费宝贵时间并加剧医院拥挤。本文探讨了先进的人工智能(AI)如何更可靠地引导患者就诊到正确的专科,研究基于患者与临床医生之间的真实对话。通过把这些杂乱的日常对话转化为严格的测试平台并发起公开竞赛,作者展示了如何通过审慎评估将AI分诊从有前景的演示推进到更安全的工具,未来可能部署在医院网站、手机应用和挂号窗口后面。
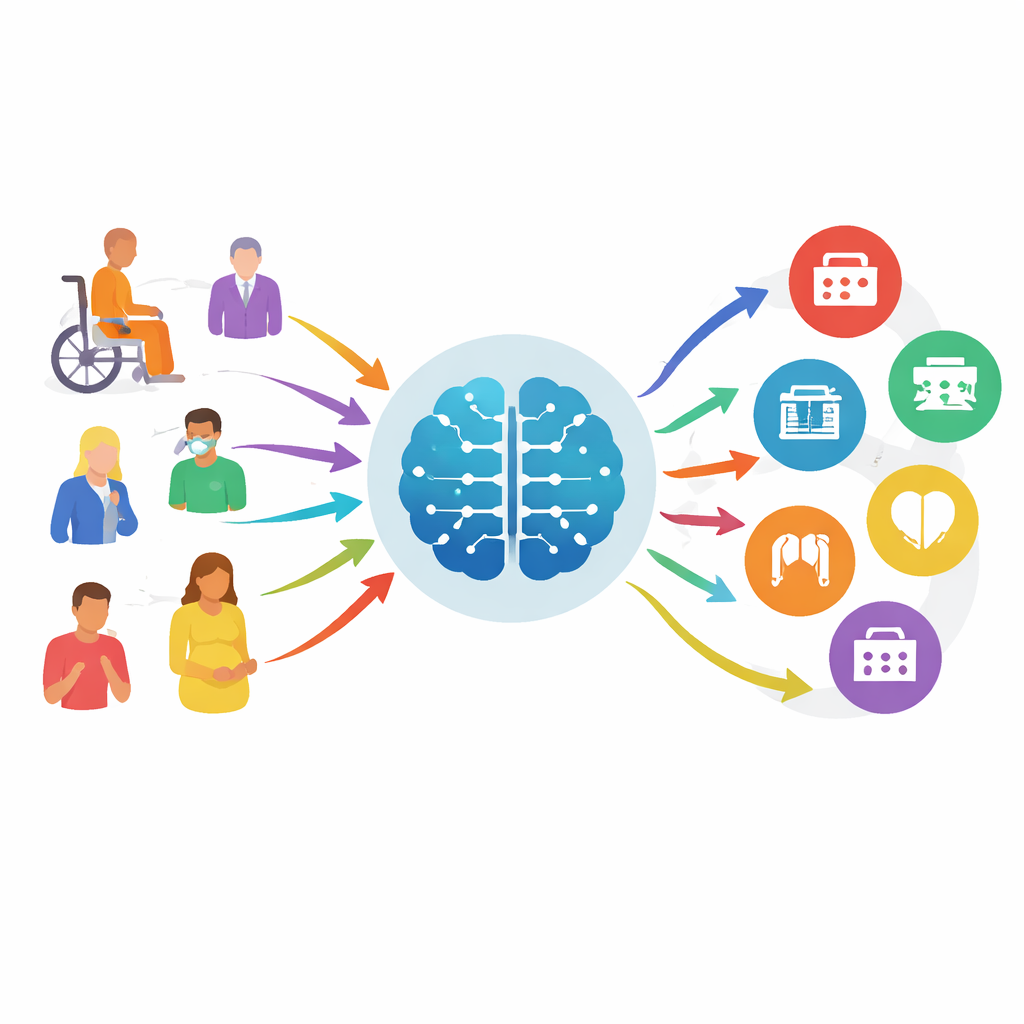
从盲猜到有指导的基准
现有的在线症状检查工具常常表现不佳,遗漏严重问题并给出含糊的建议。与此同时,新一代大型语言模型——现代聊天机器人的底层AI——在理解自然语言和医学语境方面越来越强。为了评估这些模型是否能安全地辅助“专科分诊”(决定患者应看哪个科室,而不是判定疾病),研究人员构建了MedTriage,这是一个由真实、去标识化记录组成的大型基准,涵盖五个主要领域:全科医学、儿科、产科与妇科、牙科和中医。MedTriage包含三类与现实相符的输入:前台式的简短主诉加年龄与性别、医生书写的更丰富的临床记录,以及来自在线咨询系统的多轮患者—机器人聊天记录。
把医院数据变成公平的竞赛
借助这一基准,研究团队发起了一项名为MedBench的全国性竞赛,邀请医院、研究实验室和企业提交其最佳分诊模型。所有参赛队伍必须以相同方式打包系统,并使用对参与者隐藏的标准化测试集。这样确保模型之间的比较公平,且不能简单地记忆答案。结果暴露了巨大差距:一些模型在从验证数据迁移到未见测试样本时表现稳健,而其他模型则表现急剧下降,突显了仅靠内部评估可能掩盖在新患者群体或不同医院习惯下失效的风险。
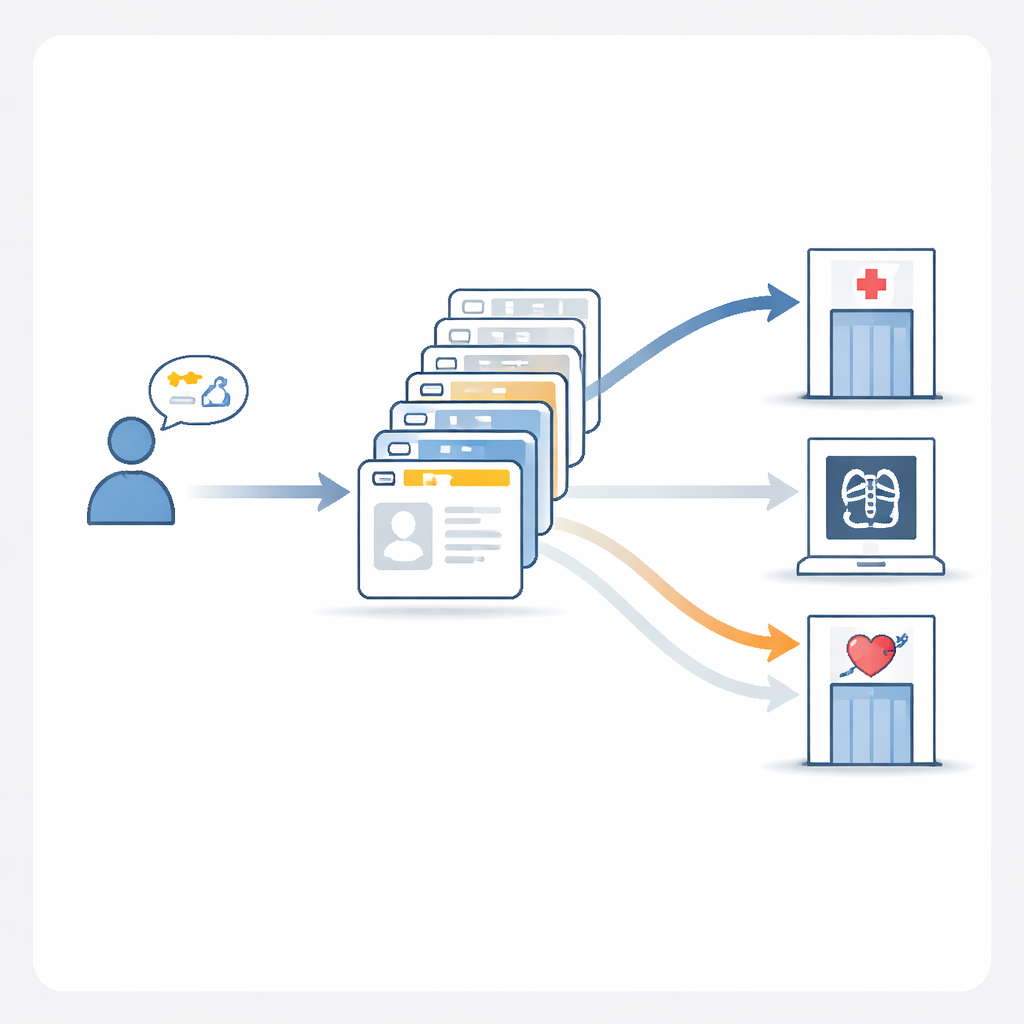
AI内部什么方法最有效
在审查竞赛结果后,作者构建了自己的参考模型MedGPT-Guide,以系统性地测试哪些方法能真正提升分诊准确性。他们发现,仅仅要求AI“逐步解释其推理”能带来一定提升,但最大收益来自精心挑选的示例。MedGPT-Guide向模型展示二十个既往病例——十个与新患者高度相似,十个随机选取——然后采用一种集成策略,比较多次运行中科室列表的随机排列。这种“10个相关+10个随机+集成”方案将精确匹配准确率推近80%,显著优于常见的通用模型。实际上,这意味着系统更有可能为可能涉及多个专科的患者推荐完整且正确的科室组合。
差距、保障与现实限制
尽管取得进展,论文强调AI分诊尚不适合无人监督运行。详细的错误分析显示,不同模型会犯不同类型的错误:有些会过度推荐多个科室,另一些则漏掉重要科室。偏见是持续关注的问题;例如,模型可能会对儿童过度推荐某些服务,而对老年人则很少推荐,从而可能加剧现有的不平等。隐私是另一大挑战,因为分诊系统从敏感的健康对话中学习,这些对话须根据HIPAA、GDPR和中国的个人信息保护法(PIPL)等法律进行保护。最后,各地监管和医院工作流程差异很大,要在所有地方部署统一系统而不进行谨慎的本地化适配与监督十分困难。
这项工作如何推动医疗前进
最终,研究的核心信息不在于某个单一的获胜模型,而在于构建合适的测试场景。通过发布MedTriage并举办公开竞赛,作者表明“以评估驱动的训练”可以稳步改进AI引导,同时揭示需要修复的安全性与公平性问题。他们设想的AI系统是与临床医生协作而非取代临床医生:通用语言模型可以处理早期患者接待与分流,而高度专门化的工具则专注于狭窄的诊断任务。对患者而言,最终的承诺很简单——更顺畅、更准确的进入医疗体系的第一步——前提是未来的工作把准确性、公平性、隐私和问责置于设计的核心。
引用: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
关键词: 医疗分诊人工智能, 大型语言模型, 临床决策支持, 医疗基准测试, 患者分流