Clear Sky Science · tr
Uzmanlık triajı için kıyaslama ve yarışma yoluyla tıbbi yapay zekâyı ilerletmek
Bakımda daha akıllıca ilk durakların önemi
İnsanlar kendilerini kötü hissettiklerinde sıklıkla ilk sordukları soru basittir: “Nereye gitmeliyim?” Ancak yanlış klinik veya bölümün seçilmesi değerli zamanı boşa harcayabilir ve dolu hastanelere yük bindirebilir. Bu makale, gelişmiş yapay zekânın (YZ) gerçek hasta–hekim konuşmalarını kullanarak hastaları doğru tıbbi uzmanlığa daha güvenilir biçimde yönlendirmeye nasıl yardımcı olabileceğini araştırıyor. Bu dağınık, günlük diyalogu titiz bir test ortamına ve kamusal bir yarışmaya dönüştürerek, yazarların dikkatli değerlendirmenin YZ triajını umut verici demoların ötesinde güvenli araçlara nasıl taşıyabileceğini gösteriyor; bir gün bunlar hastane web sitelerinin, telefon uygulamalarının ve kayıt masalarının arkasında çalışabilir.
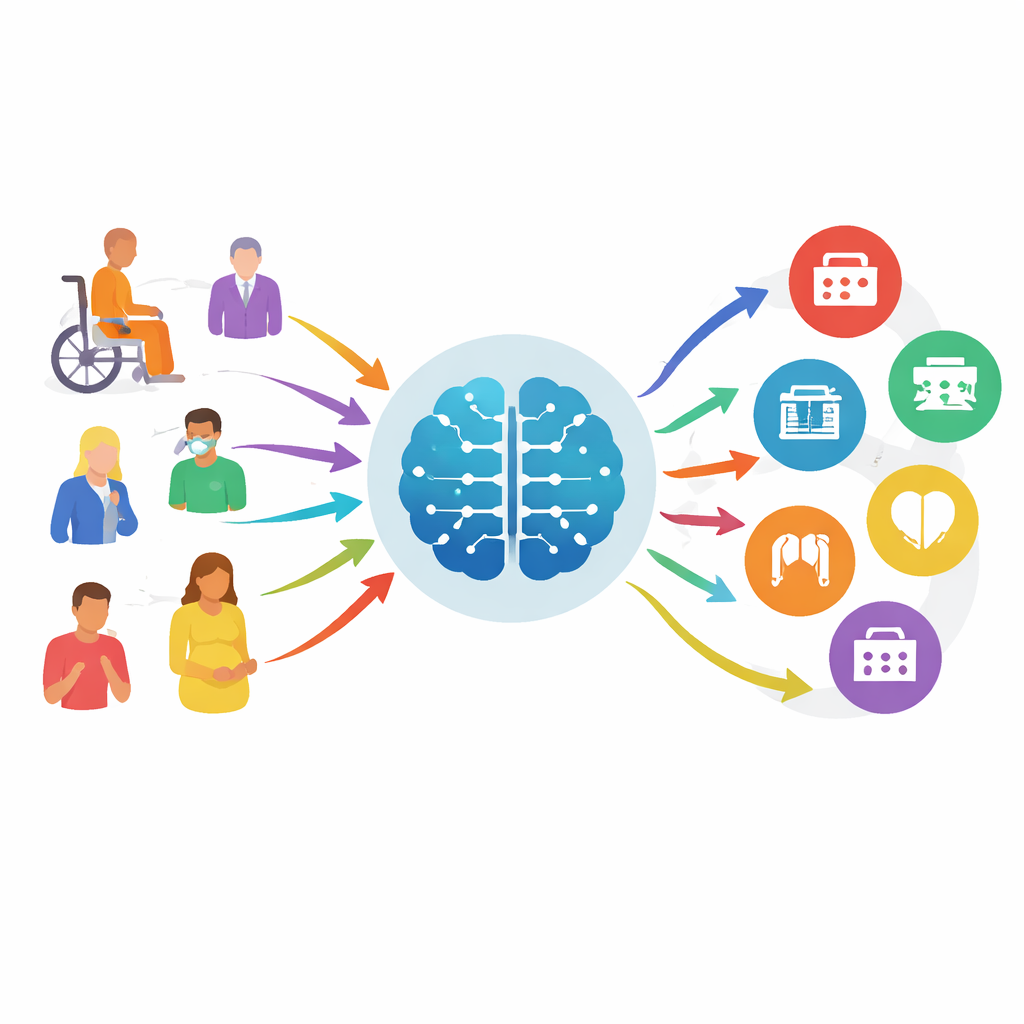
Tahminlerden rehberli kıyaslamalara
Günümüzün çevrimiçi semptom kontrol araçları çoğunlukla yetersiz performans gösteriyor, ciddi sorunları kaçırabiliyor ve belirsiz yönlendirmeler sunabiliyor. Aynı zamanda, modern sohbet botlarının temelini oluşturan yeni büyük dil modelleri doğal dili ve tıbbi bağlamı anlamada daha iyi hâle geliyor. Bu modellerin “uzmanlık triajında” (bir hastanın hangi bölüme gitmesi gerektiğini belirleme, hastalığı teşhis etme değil) güvenli bir şekilde yardımcı olup olamayacağını görmek için araştırmacılar MedTriage adında, genel tıp, çocuk sağlığı, kadın doğum, diş hekimliği ve geleneksel Çin tıbbı olmak üzere beş ana alana dair gerçek, anonimleştirilmiş kayıtlardan oluşan büyük bir kıyaslama seti oluşturdular. MedTriage, gerçek hayatı yansıtan üç tür girdi içeriyor: yaş ve cinsiyet bilgisiyle kısa ön büro şikâyetleri, doktorların yazdığı daha ayrıntılı klinik notlar ve çevrimiçi yönlendirme sistemlerinden alınan çok turlu hasta–bot sohbet kayıtları.
Hastane verisini adil bir yarışmaya dönüştürmek
Bu kıyaslamayı kullanarak ekip, MedBench adlı ülke çapında bir yarışma başlattı ve hastaneleri, araştırma laboratuvarlarını ve şirketleri en iyi triaj modellerini göndermeye davet etti. Tüm ekiplerin sistemlerini aynı şekilde paketlemeleri ve katılımcılardan gizlenen standartlaştırılmış test setlerini kullanmaları gerekiyordu. Bu, modellerin adil şekilde karşılaştırılmasını ve cevapları ezberleyememelerini sağladı. Sonuçlar büyük farkları ortaya koydu: bazı modeller doğrulama verilerinden görülmemiş test vakalarına geçişte iyi performans gösterirken, diğerleri keskin düşüşler yaşadı; bu da kurum içi testlerde iyi görünen sistemlerin yeni hasta popülasyonları veya farklı hastane alışkanlıklarıyla karşılaştıklarında başarısız olma riskini vurguluyor.
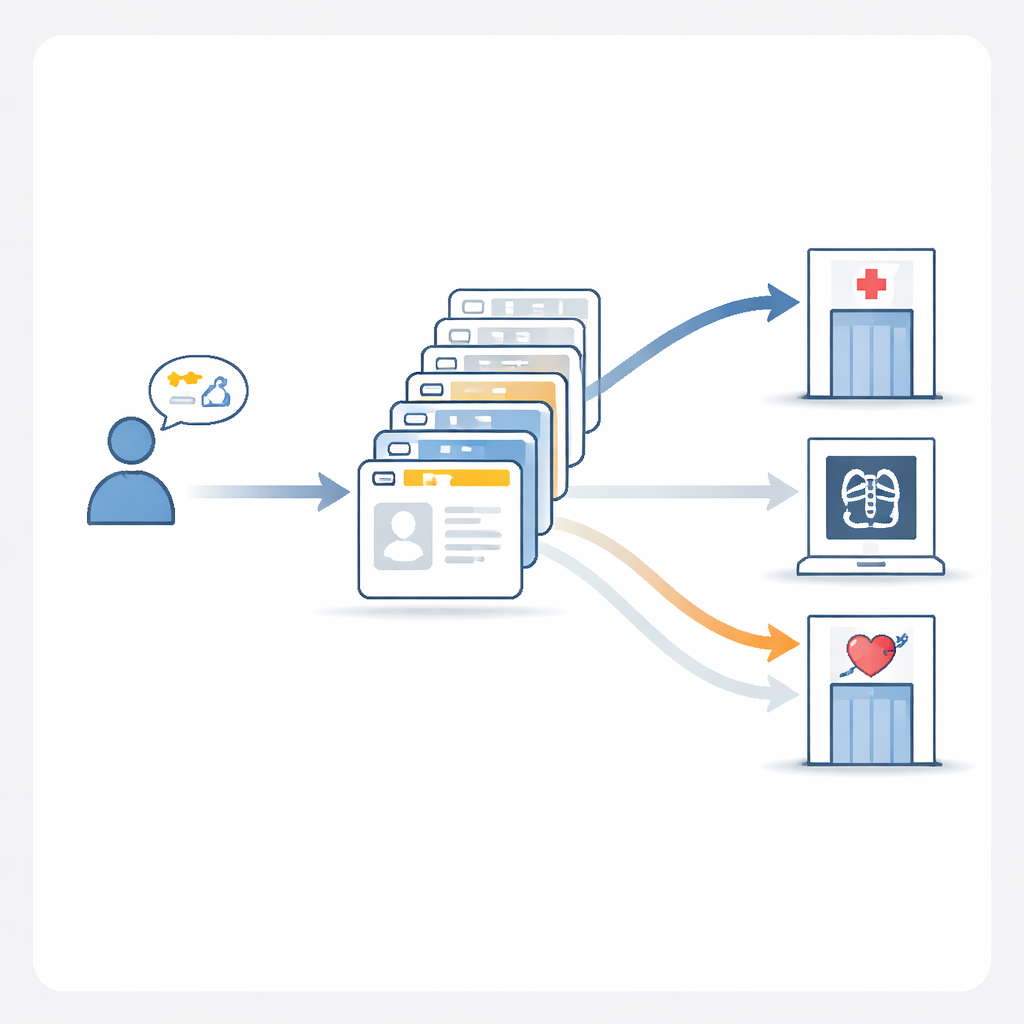
YZ içinde en iyi işe yarayan yaklaşımlar
Yarışma sonuçlarını gözden geçirdikten sonra yazarlar, triaj doğruluğunu gerçekten neyin iyileştirdiğini sistematik olarak test etmek için kendi referans modellerini, MedGPT-Guide’ı inşa ettiler. Yapay zekâdan adım adım “akıl yürütmesini açıklamasını” istemek bir miktar yardımcı oldu, ancak en büyük kazanımlar özenle seçilmiş örneklerden geldi. MedGPT-Guide modele yirmi geçmiş vaka gösteriyor—yeni hastaya çok benzeyen on vaka ve rastgele seçilmiş on vaka—ve ardından bölümler listesinin karıştırıldığı birden çok çalıştırmayı karşılaştıran bir topluluk (ensemble) stratejisi kullanıyor. Bu “10 alakalı + 10 rastgele + topluluk” tarifi tam eşleşme doğruluğunu yaklaşık %80’e yaklaştırdı ve popüler genel amaçlı modellerden belirgin şekilde daha iyi oldu. Pratikte bu, sistemin bakımında birden fazla uzmanlık alanı gerektirebilecek bir hasta için doğru ve eksiksiz bölüm setini önermeye çok daha yatkın olduğu anlamına geliyor.
Açıklar, koruyucular ve gerçek dünya sınırları
Bu ilerlemeye rağmen makale, YZ triajının gözetimsiz çalıştırılmaya hazır olmadığını vurguluyor. Ayrıntılı hata analizleri farklı modellerin farklı türde hatalar yaptığını gösteriyor: bazıları çok sayıda bölüm önermek konusunda aşırıya kaçıyor, diğerleri ise önemli bölümleri atlıyor. Önyargı süreklilik arz eden bir endişe; örneğin modeller çocuklar için belirli hizmetleri fazla önerirken yaşlı yetişkinlerde bunları neredeyse hiç önermeyebilir ve bu da mevcut eşitsizlikleri kötüleştirebilir. Gizlilik başka büyük bir zorluk çünkü triaj sistemleri HIPAA, GDPR ve Çin’in PIPL’i gibi kanunlarla korunması gereken hassas sağlık konuşmalarından öğreniyor. Son olarak, düzenlemeler ve hastane iş akışları bölgeden bölgeye büyük ölçüde farklılık gösteriyor; bu da dikkatli yerel uyarlama ve denetim olmadan tek bir sistemi her yerde konuşlandırmayı zorlaştırıyor.
Bu çalışmanın bakımı ilerletmedeki rolü
Sonuç olarak çalışmanın temel mesajı tek bir kazanan modelden ziyade doğru test alanını inşa etmek üzerine. MedTriage’i yayımlayarak ve açık bir yarışma düzenleyerek yazarlar, “değerlendirme odaklı eğitimin” YZ rehberliğini istikrarlı biçimde iyileştirebileceğini ve düzeltilmesi gereken güvenlik ve adalet sorunlarını ortaya çıkarabileceğini gösteriyor. Onlar, YZ sistemlerinin klinisyenlerin yerine değil yanında çalışmasını öngörüyor: geniş dil modelleri erken hasta kabul ve yönlendirmeyi ele alabilirken, yüksek uzmanlıktaki araçlar dar tanısal görevlerde yoğunlaşabilir. Hastalar için nihai vaat basit: doğruluğun, eşitliğin, gizliliğin ve hesap verebilirliğin tasarımın merkezinde tutulması koşuluyla daha sorunsuz ve daha doğru bir sağlık sistemine ilk adım.
Atıf: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
Anahtar kelimeler: tıbbi triaj yapay zekâsı, büyük dil modelleri, klinik karar desteği, sağlık hizmetleri kıyaslaması, hasta yönlendirme