Clear Sky Science · nl
Vooruitgang in medische AI via benchmarking en competitie voor specialisme-triage
Waarom slimere eerste stappen in de zorg ertoe doen
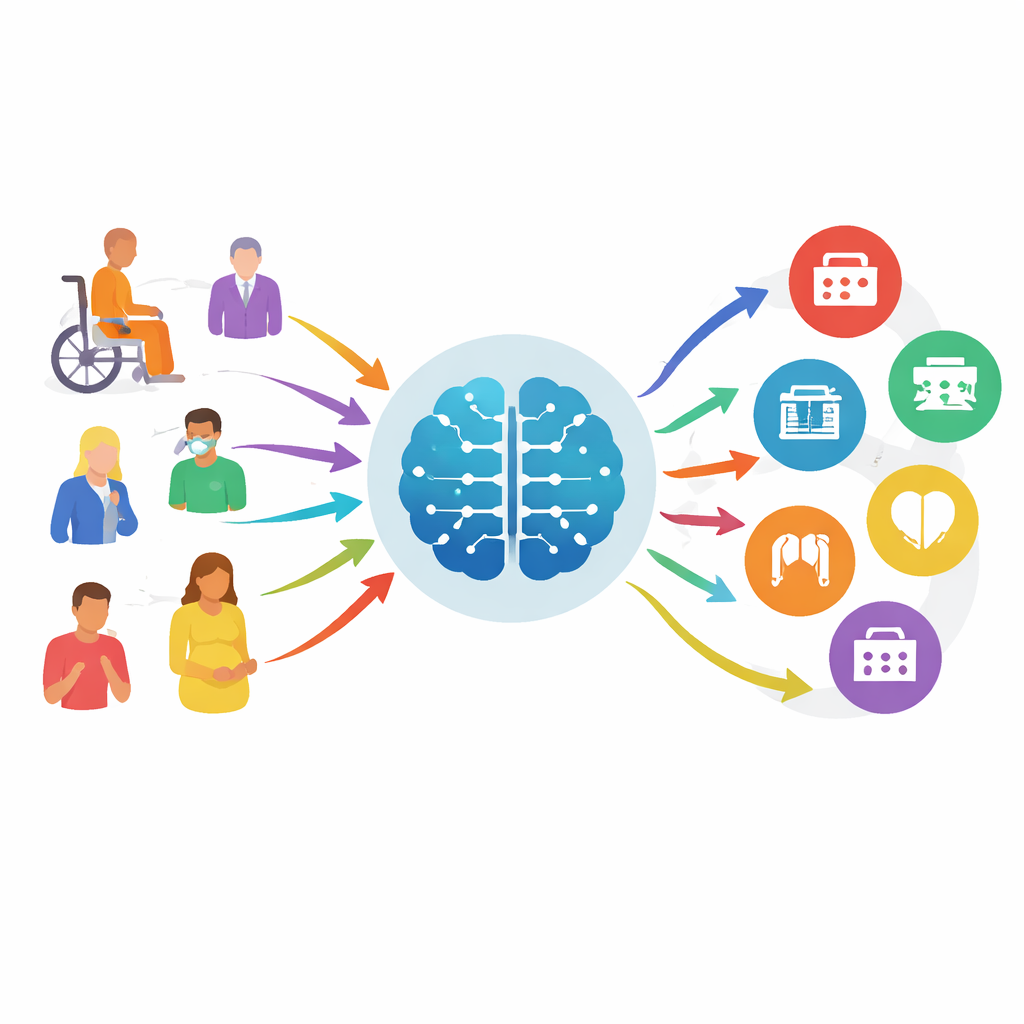
Wanneer mensen zich niet goed voelen, is hun eerste vraag vaak eenvoudig: “Waar moet ik heen?” Het kiezen van de verkeerde kliniek of afdeling kan echter kostbare tijd verspillen en druk zetten op reeds volle ziekenhuizen. Dit artikel onderzoekt hoe geavanceerde kunstmatige intelligentie (AI) patiënten betrouwbaarder kan helpen naar het juiste medische specialisme te leiden, op basis van echte gesprekken tussen patiënten en zorgverleners. Door die rommelige, alledaagse dialoog om te zetten in een rigoureuze testomgeving en een publieke competitie, laten de auteurs zien hoe zorgvuldige evaluatie AI-triage kan verschuiven van veelbelovende demonstraties naar veiligere hulpmiddelen die op den duur achter ziekenhuiswebsites, telefoonapps en balies kunnen zitten.
Van giswerk naar gestuurde benchmarks
De huidige online symptoomchecks presteren vaak slecht: ze missen ernstige problemen en geven vage adviezen. Tegelijkertijd worden nieuwe grote taalmodellen—dezelfde soort AI achter moderne chatbots—beter in het begrijpen van natuurlijke taal en medische context. Om te onderzoeken of deze modellen veilig kunnen helpen bij “specialisme-triage” (het bepalen welke afdeling een patiënt moet zien, niet welke ziekte deze heeft), bouwden de onderzoekers MedTriage, een grote benchmark samengesteld uit echte, geanonimiseerde gegevens uit vijf hoofdgebieden: algemene geneeskunde, kindergeneeskunde, verloskunde en gynaecologie, tandheelkunde en traditionele Chinese geneeskunde. MedTriage bevat drie soorten invoer die het echte leven weerspiegelen: korte, balieachtige klachten met leeftijd en geslacht, rijkere klinische aantekeningen van artsen, en meerstaps patiënt–bot chatlogs van online adviesdiensten.
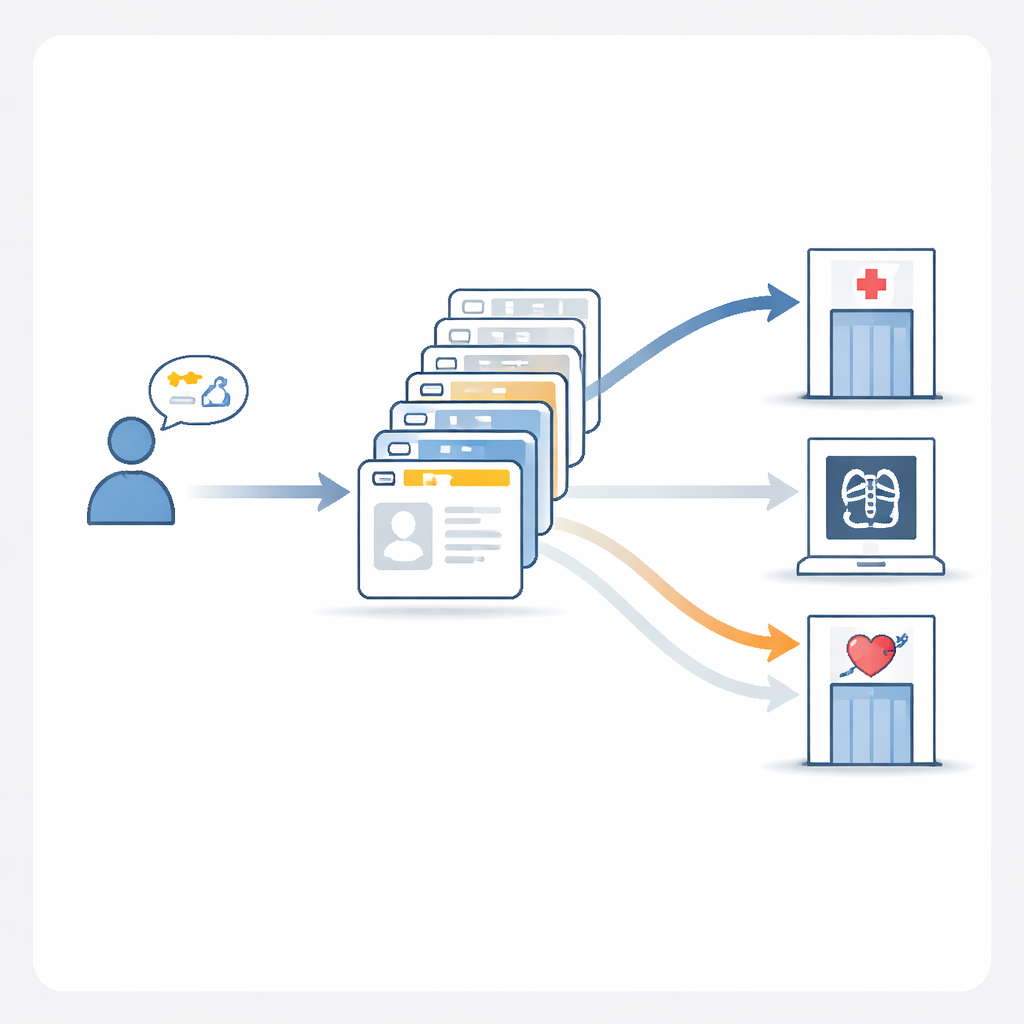
Ziekenhuisgegevens omzetten in een eerlijke wedstrijd
Met deze benchmark lanceerde het team een landelijke competitie genaamd MedBench, waarin ziekenhuizen, onderzoekslaboratoria en bedrijven werden uitgenodigd hun beste triagemodellen in te zenden. Alle teams moesten hun systemen op dezelfde manier verpakken en gebruikmaken van gestandaardiseerde testsets die voor de deelnemers verborgen waren. Dit zorgde ervoor dat modellen eerlijk werden vergeleken en niet eenvoudigweg de antwoorden konden uit het hoofd leren. De resultaten toonden grote verschillen: sommige modellen hielden goed stand bij overgang van validatiegegevens naar ongeziene testcases, terwijl andere scherp terugvielen, wat het risico benadrukt van systemen die er intern goed uitzien maar falen bij nieuwe patiëntpopulaties of andere ziekenhuisgebruiken.
Wat werkt het beste binnen de AI
Na beoordeling van de competitie-uitkomsten bouwden de auteurs hun eigen referentiemodel, MedGPT-Guide, om systematisch te testen wat daadwerkelijk de triage-accuratesse verbetert. Ze ontdekten dat het simpelweg vragen aan de AI om stap-voor-stap zijn redenering uit te leggen enigszins hielp, maar de grootste winst kwam van zorgvuldig gekozen voorbeeldgevallen. MedGPT-Guide toont het model twintig eerdere gevallen—tien die zeer vergelijkbaar zijn met de nieuwe patiënt en tien willekeurig geselecteerde—en gebruikt vervolgens een ensemble-strategie die meerdere runs vergelijkt met door elkaar gehaalde afdelingslijsten. Dit ’10 relevant + 10 willekeurig + ensemble’-recept bracht de exact-match nauwkeurigheid dicht bij 80%, duidelijk beter dan populaire algemeen toepasbare modellen. In de praktijk betekent dit dat het systeem veel waarschijnlijker de volledige, correcte set afdelingen aanbeveelt voor een patiënt wiens zorg mogelijk meerdere specialismen vereist.
Hiaten, vangrails en beperkingen in de praktijk
Ondanks deze vooruitgang benadrukt het artikel dat AI-triage niet klaar is om onvertooid te opereren. Gedetailleerde foutanalyses laten zien dat verschillende modellen verschillende soorten fouten maken: sommige raden te veel afdelingen aan, andere missen belangrijke afdelingen. Vooringenomenheid is een terugkerende zorg; zo kunnen modellen bepaalde diensten voor kinderen oversuggesten terwijl ze voor ouderen nauwelijks worden voorgesteld, wat bestaande ongelijkheden kan verergeren. Privacy is een andere grote uitdaging, omdat triagesystemen leren van gevoelige gezondheidsgesprekken die beschermd moeten worden onder wetten zoals HIPAA, GDPR en China’s PIPL. Ten slotte verschillen regelgeving en ziekenhuiswerkstromen sterk tussen regio’s, waardoor het moeilijk is om één systeem overal te implementeren zonder zorgvuldige lokale aanpassing en toezicht.
Hoe dit werk de zorg vooruit helpt
Uiteindelijk is de belangrijkste boodschap van de studie minder een enkel winnend model en meer het bouwen van de juiste testomgeving. Door MedTriage vrij te geven en een open competitie te houden, tonen de auteurs aan dat “evaluatie-gestuurde training” AI-advies gestaag kan verbeteren, terwijl veiligheids- en eerlijkheidsproblemen aan het licht komen die moeten worden opgelost. Ze voor zich AI-systemen die samenwerken met—en niet in plaats van—zorgverleners: brede taalmodellen kunnen de vroege patiëntontvangst en routing afhandelen, terwijl sterk gespecialiseerde tools zich richten op smalle diagnostische taken. Voor patiënten is de uiteindelijke belofte eenvoudig: een soepelere, accuratere eerste stap in het zorgsysteem—mits toekomstig werk nauwlettend nauwkeurigheid, gelijkheid, privacy en verantwoording centraal stelt in het ontwerp.
Bronvermelding: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
Trefwoorden: medische triage AI, grote taalmodellen, klinische besluitondersteuning, benchmarking in de gezondheidszorg, patiëntenrouting