Clear Sky Science · sv
Främja medicinsk AI genom benchmarking och tävling för specialitetsprioritering
Varför smartare första stopp i vården spelar roll
När människor mår dåligt är deras första fråga ofta enkel: ”Vart ska jag gå?” Att välja fel mottagning eller avdelning kan dock kosta värdefull tid och belasta redan trånga sjukhus. Denna artikel undersöker hur avancerad artificiell intelligens (AI) kan hjälpa till att leda patienter till rätt medicinska specialitet mer pålitligt, med hjälp av verkliga samtal mellan patienter och vårdgivare. Genom att omvandla denna röriga, vardagliga dialog till en rigorös testmiljö och en offentlig tävling visar författarna hur noggrann utvärdering kan driva AI-triage från lovande demonstrationer mot säkrare verktyg som en dag kan ligga bakom sjukhuswebbplatser, telefonappar och registreringsdiskar.
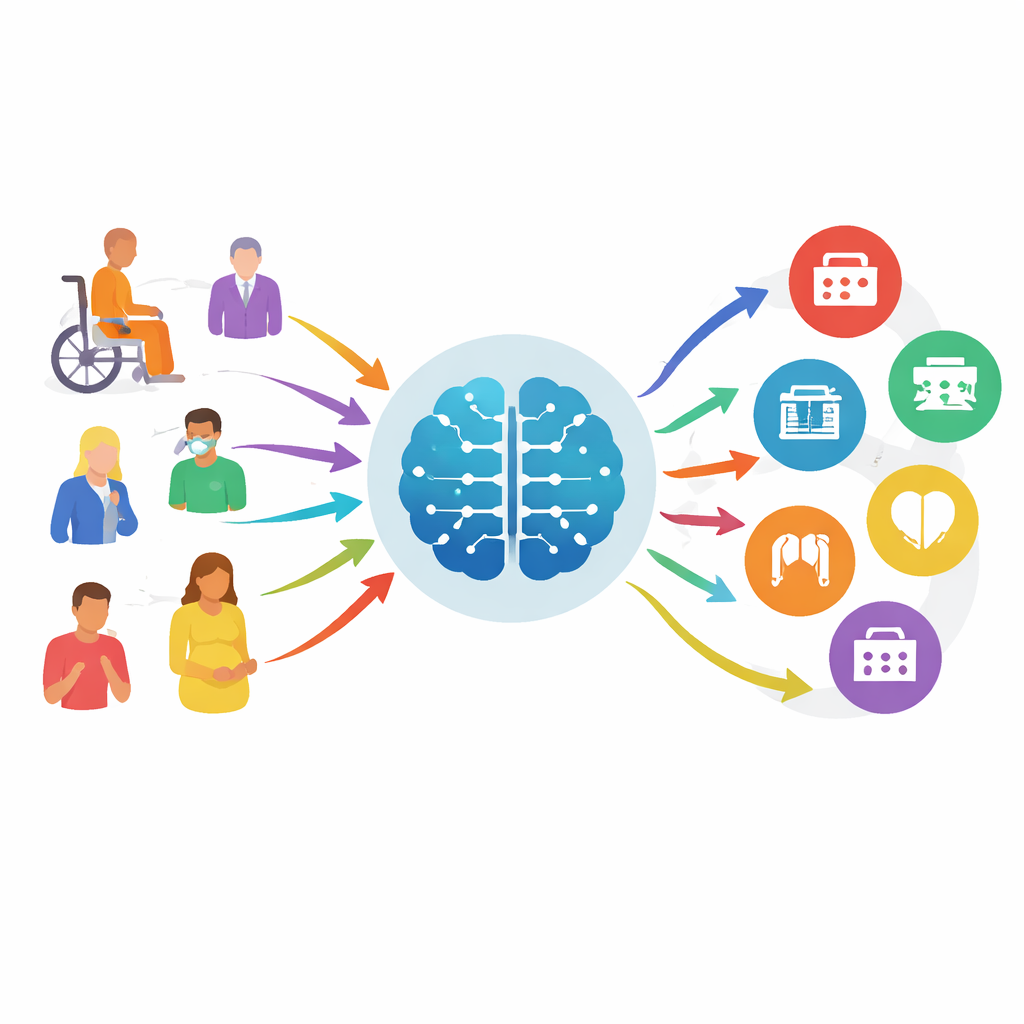
Från gissning till vägledda benchmarks
Dagens symtomkontroller på nätet fungerar ofta dåligt, missar allvarliga problem och ger vaga rekommendationer. Samtidigt blir nya stora språkmodeller—samma typ av AI som driver moderna chattbotar—bättre på att förstå naturligt språk och medicinsk kontext. För att undersöka om dessa modeller säkert kan hjälpa med ”specialitetstriage” (att avgöra vilken avdelning en patient bör träffa, inte vilken sjukdom de har) byggde forskarna MedTriage, ett stort benchmark skapat av verkliga, avidentifierade journaler över fem huvudområden: allmänmedicin, pediatrik, obstetrik och gynekologi, tandvård och traditionell kinesisk medicin. MedTriage innehåller tre slags input som speglar verkligheten: korta receptionlika klagomål med ålder och kön, rikare kliniska anteckningar skrivna av läkare samt flerstegs patient–bot-chattloggar från onlinetjänster för vägledning.
Att göra sjukhusdata till en rättvis tävling
Med detta benchmark lanserade teamet en nationell tävling kallad MedBench och bjöd in sjukhus, forskningslaboratorier och företag att skicka in sina bästa triagemodeller. Alla lag var tvungna att paketera sina system på samma sätt och använda standardiserade testset som var dolda för deltagarna. Det säkerställde att modellerna jämfördes rättvist och inte bara kunde memorera svaren. Resultaten avslöjade stora luckor: vissa modeller höll jämnt när de gick från valideringsdata till osedda testfall, medan andra sjönk kraftigt, vilket underströk risken med system som ser bra ut internt men misslyckas när de konfronteras med nya patientpopulationer eller olika sjukhusrutiner.
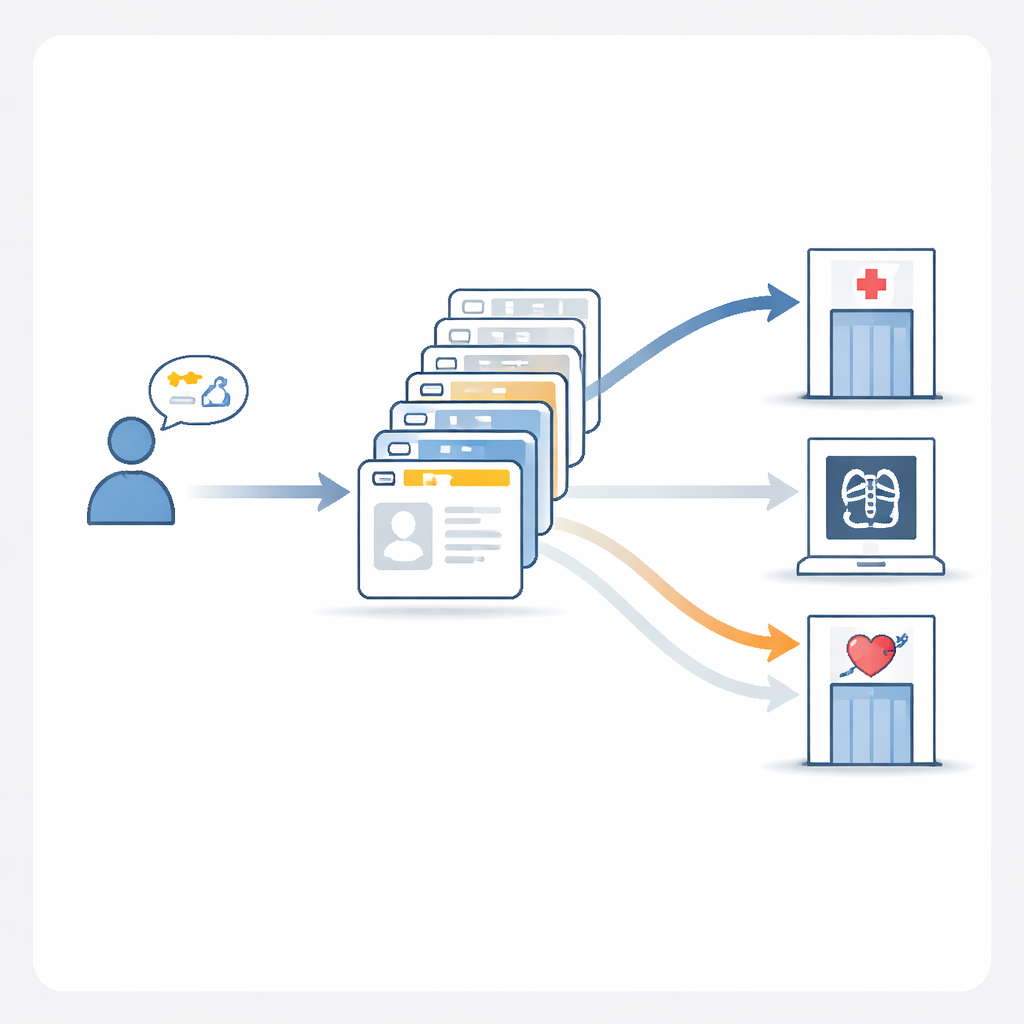
Vad som fungerar bäst inne i AI:n
Efter att ha granskat tävlingsresultaten byggde författarna en egen referensmodell, MedGPT-Guide, för att systematiskt testa vad som faktiskt förbättrar triagenoggrannheten. De fann att det att be AI:n ”förklara sitt resonemang” steg för steg hjälpte något, men de största förbättringarna kom från noggrant utvalda exempel. MedGPT-Guide visar modellen tjugo tidigare fall—tio som är mycket lika den nya patienten och tio slumpmässigt valda—och använder sedan en ensemble-strategi som jämför flera körningar med omkastade avdelningslistor. Detta recept, ”10 relevanta + 10 slumpmässiga + ensemble”, pressade exakt-matchningsnoggrannheten nära 80 %, betydligt bättre än populära allmänna modeller. I praktiken innebär det att systemet mycket oftare rekommenderar den fullständiga, korrekta uppsättningen av avdelningar för en patient vars vård kan involvera mer än en specialitet.
Luckor, skyddsåtgärder och verkliga begränsningar
Trots denna framgång betonar artikeln att AI-triage inte är redo att köras utan övervakning. Detaljerade felanalyser visar att olika modeller gör olika typer av misstag: vissa överrekommenderar många avdelningar, andra missar viktiga sådana. Bias är en återkommande oro; till exempel kan modeller överförslå vissa tjänster för barn samtidigt som de knappast gör det för äldre, vilket kan förvärra befintliga ojämlikheter. Integritet är en annan stor utmaning, eftersom triagesystem lär sig från känsliga vårdsamtal som måste skyddas enligt lagar som HIPAA, GDPR och Kinas PIPL. Slutligen skiljer sig regler och sjukhusrutiner kraftigt mellan regioner, vilket gör det svårt att rulla ut ett enda system överallt utan noggrann lokal anpassning och tillsyn.
Hur detta arbete för vården framåt
I slutändan är studiens huvudbudskap mindre om en enskild vinnarmodell och mer om att bygga rätt testbädd. Genom att släppa MedTriage och genomföra en öppen tävling visar författarna att ”utvärderingsdriven träning” kan stadigt förbättra AI-vägledning samtidigt som säkerhets- och rättvisefrågor belyses och måste åtgärdas. De föreställer sig AI-system som arbetar tillsammans med, inte istället för, vårdpersonal: breda språkmodeller skulle kunna hantera tidig patientmottagning och styrning, medan högspecialiserade verktyg fokuserar på snävare diagnostiska uppgifter. För patienter är det yttersta löftet enkelt—ett smidigare, mer exakt första steg in i vårdsystemet—förutsatt att framtida arbete håller noggrannhet, rättvisa, integritet och ansvarstagande i centrum för utformningen.
Citering: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
Nyckelord: medicinsk triage-AI, stora språkmodeller, kliniskt beslutsstöd, benchmarking inom vården, patientstyrning