Clear Sky Science · ar
تقدّم الذكاء الاصطناعي الطبي عبر المقاييس التقييمية والمنافسة لتحديد التخصص المناسب
لماذا تهم المحطات الأولى الأكثر ذكاءً في الرعاية
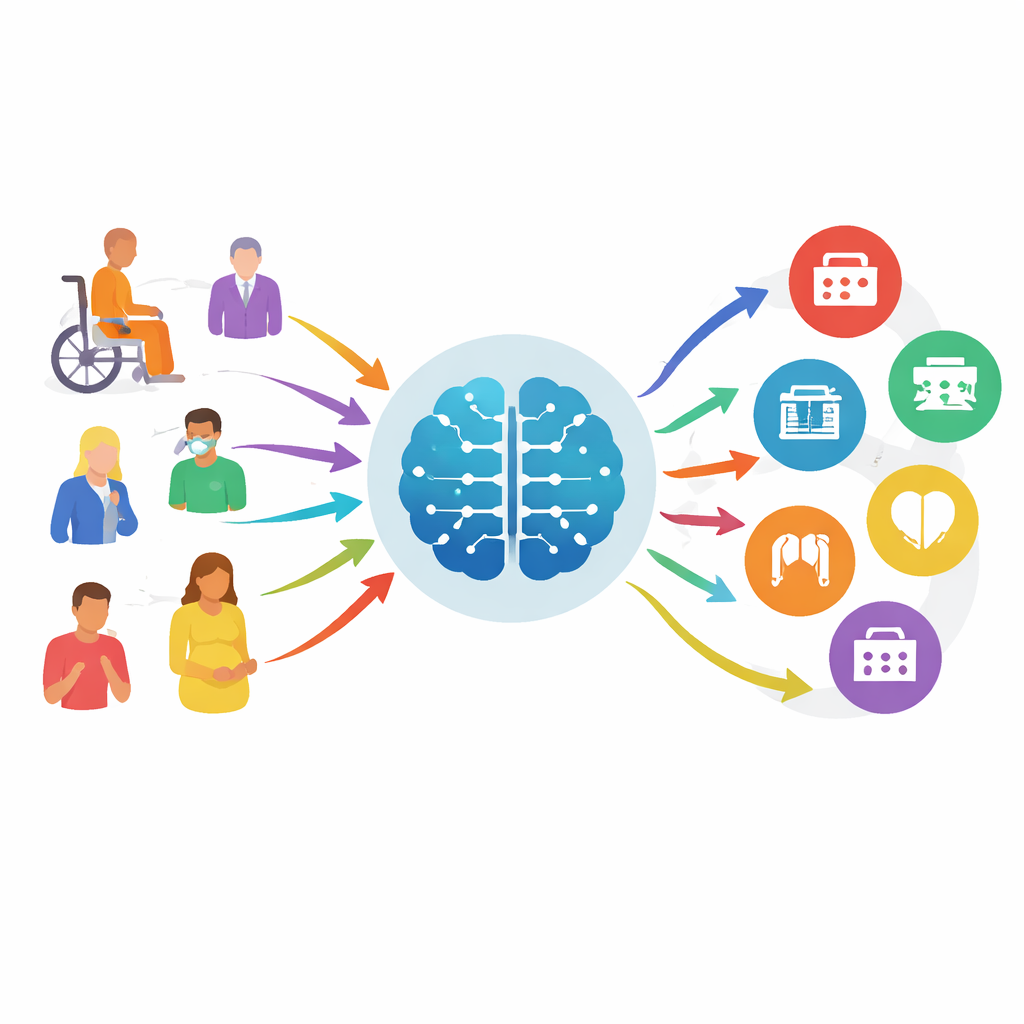
عندما يشعر الناس بالتوعك، يكون سؤالهم الأول غالبًا بسيطًا: «أين يجب أن أذهب؟» لكن اختيار العيادة أو القسم الخاطئ يمكن أن يهدر وقتًا ثمينًا ويزيد الضغط على المستشفيات المزدحمة. تستعرض هذه الورقة كيف يمكن للذكاء الاصطناعي المتقدّم أن يساعد في توجيه المرضى إلى التخصص الطبي المناسب بشكل أكثر موثوقية، باستخدام محادثات واقعية بين المرضى والمقدّمين الطبيين. من خلال تحويل هذا الحوار اليومي غير المنظم إلى بيئة اختبار منهجية ومنافسة عامة، يبيّن المؤلفون كيف أن التقييم الدقيق يمكن أن يدفع فرز المرضى بالذكاء الاصطناعي من عروض واعدة إلى أدوات أكثر أمانًا قد تجلس يومًا ما وراء المواقع الإلكترونية للمستشفيات وتطبيقات الهاتف وطاولات التسجيل.
من التخمين إلى مقاييس تقييم موجهة
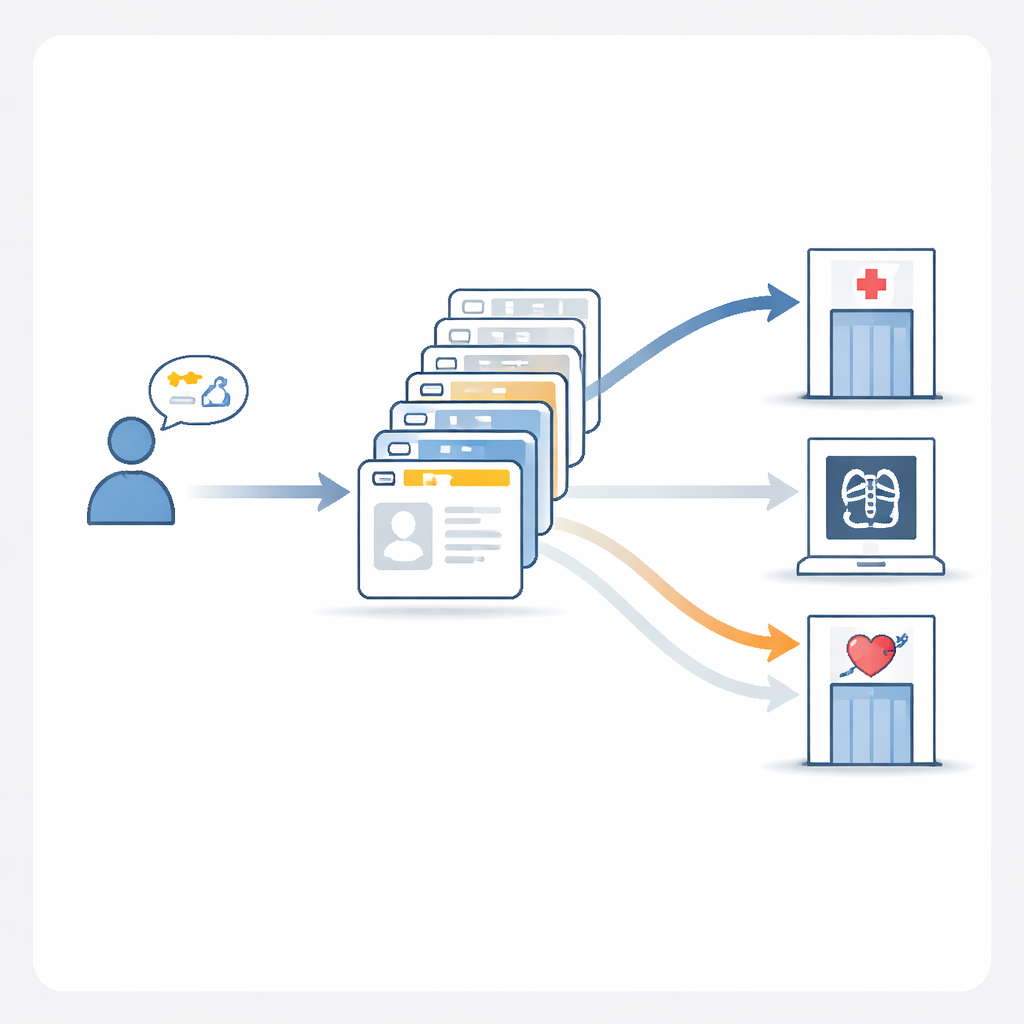
غالبًا ما تعمل خدمات فحص الأعراض عبر الإنترنت اليوم بشكل متدنٍ، فتغفل مشكلات خطيرة وتقدّم إرشادات غامضة. وفي الوقت نفسه، تتحسّن نماذج اللغة الكبيرة—نفس نوع الذكاء الاصطناعي وراء روبوتات الدردشة الحديثة—في فهم اللغة الطبيعية والسياق الطبي. للتحقق مما إذا كانت هذه النماذج قادرة على المساعدة بأمان في «تحديد التخصص» (تقرير أي قسم ينبغي أن يرى المريض، لا تشخيص المرض نفسه)، بنى الباحثون MedTriage، مقياسًا كبيرًا مشتقًا من سجلات حقيقية مُجهّلة عبر خمسة مجالات رئيسية: الطب العام، طب الأطفال، التوليد وأمراض النساء، طب الأسنان، والطب الصيني التقليدي. يتضمن MedTriage ثلاثة أنواع من المدخلات التي تعكس الواقع: شكاوى قصيرة على نمط مكتب الاستقبال مع العمر والجنس، وملاحظات سريرية أغنى كتبها الأطباء، وسجلات دردشة متعددة الجولات بين المريض والروبوت من أنظمة الإرشاد عبر الإنترنت.
تحويل بيانات المستشفيات إلى مسابقة عادلة
باستخدام هذا المقياس، أطلق الفريق مسابقة وطنية اسمها MedBench، دعا فيها المستشفيات والمختبرات البحثية والشركات لتقديم أفضل نماذج الترياج لديهم. كان على جميع الفرق تعبئة أنظمتها بنفس الطريقة، واستخدام مجموعات اختبار موحّدة كانت مخفيَّة عن المشاركين. ضمنت هذه الخطوة مقارنة عادلة للنماذج ومنعت حفظ الإجابات مسبقًا. كشفت النتائج عن فروق كبيرة: حافظت بعض النماذج على أدائها عند الانتقال من بيانات التحقق إلى حالات اختبار غير مرئية، في حين تراجع أداء أخرى بشكل حاد، ما يبرز مخاطر بناء أنظمة تبدو جيدة داخل المؤسسة لكنها تفشل عند تعرضها لسكان مرضى جدد أو عادات مستشفى مختلفة.
ما الذي يعمل أفضل داخل الذكاء الاصطناعي
بعد مراجعة نتائج المسابقة، أنشأ المؤلفون نموذجهم المرجعي الخاص، MedGPT-Guide، لاختبار منهجي لما يحسّن دقة الترياج بالفعل. وجدوا أن مطالبة الذكاء الاصطناعي ببساطة «شرح مبرراته» خطوة بخطوة حسّنت الأداء إلى حد ما، لكن أكبر المكاسب جاءت من أمثلة مختارة بعناية. يعرض MedGPT-Guide للنموذج عشرين حالة سابقة—عشر حالات مشابهة جدًا للمريض الجديد وعشر حالات منتقاة عشوائيًا—ثم يستخدم استراتيجية تجميع تقارن بين عدة تشغيلات مع قوائم أقسام معاد ترتيبها. دفعت هذه الوصفة «10 ذات صلة + 10 عشوائية + تجميع» دقة المطابقة التامة إلى قرب 80%، وهو تحسّن ملحوظ مقارنة بالنماذج العامة الشائعة. عمليًا، يعني هذا أن النظام أكثر احتمالًا لتوصية المجموعة الكاملة الصحيحة من الأقسام لمريض قد تتطلب رعايته أكثر من تخصص واحد.
الثغرات ووسائل الحماية والقيود الواقعية
رغم هذا التقدم، تؤكد الورقة أن الترياج بالذكاء الاصطناعي غير جاهز للعمل بدون إشراف. تظهر تحليلات الأخطاء التفصيلية أن النماذج المختلفة ترتكب أنواعًا مختلفة من الأخطاء: بعضها يوصي بإفراط بعدد كبير من الأقسام، بينما يفوّت آخرون أقسامًا مهمة. يشكل الانحياز مصدر قلق متكرر؛ على سبيل المثال، قد توصي النماذج بخدمات معينة للأطفال بكثرة بينما تقلّل من اقتراحها لكبار السن، ما قد يزيد من عدم المساواة القائمة. الخصوصية تحدٍ كبير آخر، لأن أنظمة الترياج تتعلم من محادثات صحية حساسة يجب حمايتها بموجب قوانين مثل HIPAA وGDPR وPIPL الصينية. أخيرًا، تختلف اللوائح وسير العمل داخل المستشفيات بشكل كبير عبر المناطق، مما يصعّب نشر نظام موحَّد في كل مكان دون تكييف محلي دقيق وإشراف.
كيف يدفع هذا العمل الرعاية إلى الأمام
في النهاية، الرسالة الرئيسية للدراسة أقل عن نموذج فائز واحد وأكثر عن بناء أرضية اختبار صحيحة. من خلال إصدار MedTriage وإدارة مسابقة مفتوحة، يبرهن المؤلفون أن «التدريب المدفوع بالتقييم» يمكن أن يحسّن إرشاد الذكاء الاصطناعي تدريجيًا مع كشف قضايا السلامة والإنصاف التي تحتاج إلى إصلاح. يتصورون أنظمة ذكاء اصطناعي تعمل جنبًا إلى جنب مع الأطباء، لا بدلاً منهم: يمكن لنماذج لغوية واسعة النطاق التعامل مع الاستقبال الأولي وتوجيه المرضى، بينما تركز الأدوات المتخصصة جدًا على مهام تشخيصية ضيقة. بالنسبة للمرضى، الوعد النهائي بسيط—خطوة أولى أكثر سلاسة ودقة في نظام الرعاية الصحية—شريطة أن تضع الأعمال المستقبلية الدقة والعدالة والخصوصية والمساءلة في مركز التصميم.
الاستشهاد: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
الكلمات المفتاحية: ذكاء اصطناعي لتحديد أولويات الرعاية الطبية, نماذج اللغة الكبيرة, دعم القرار السريري, قياس أداء الرعاية الصحية, توجيه المرضى