Clear Sky Science · de
Fortschritte in der medizinischen KI durch Benchmarking und Wettbewerbe für die Fachtriaiage
Warum klügere Erstentscheidungen in der Versorgung wichtig sind
Wenn Menschen sich unwohl fühlen, ist ihre erste Frage oft einfach: „Wohin soll ich gehen?“ Die Wahl der falschen Klinik oder Abteilung kann jedoch wertvolle Zeit kosten und überlastete Krankenhäuser zusätzlich belasten. Dieses Papier untersucht, wie moderne künstliche Intelligenz (KI) Patienten verlässlicher zur richtigen Fachrichtung leiten kann, basierend auf echten Gesprächen zwischen Patientinnen, Patienten und Ärztinnen und Ärzten. Indem diese unstrukturierte Alltagskommunikation in ein rigoroses Testfeld und einen öffentlichen Wettbewerb überführt wird, zeigen die Autorinnen und Autoren, wie sorgfältige Evaluation die KI-Triage von vielversprechenden Demonstrationen zu sichereren Werkzeugen weiterentwickeln kann, die eines Tages hinter Krankenhaus-Websites, Telefon-Apps und Anmeldetresen stehen könnten.
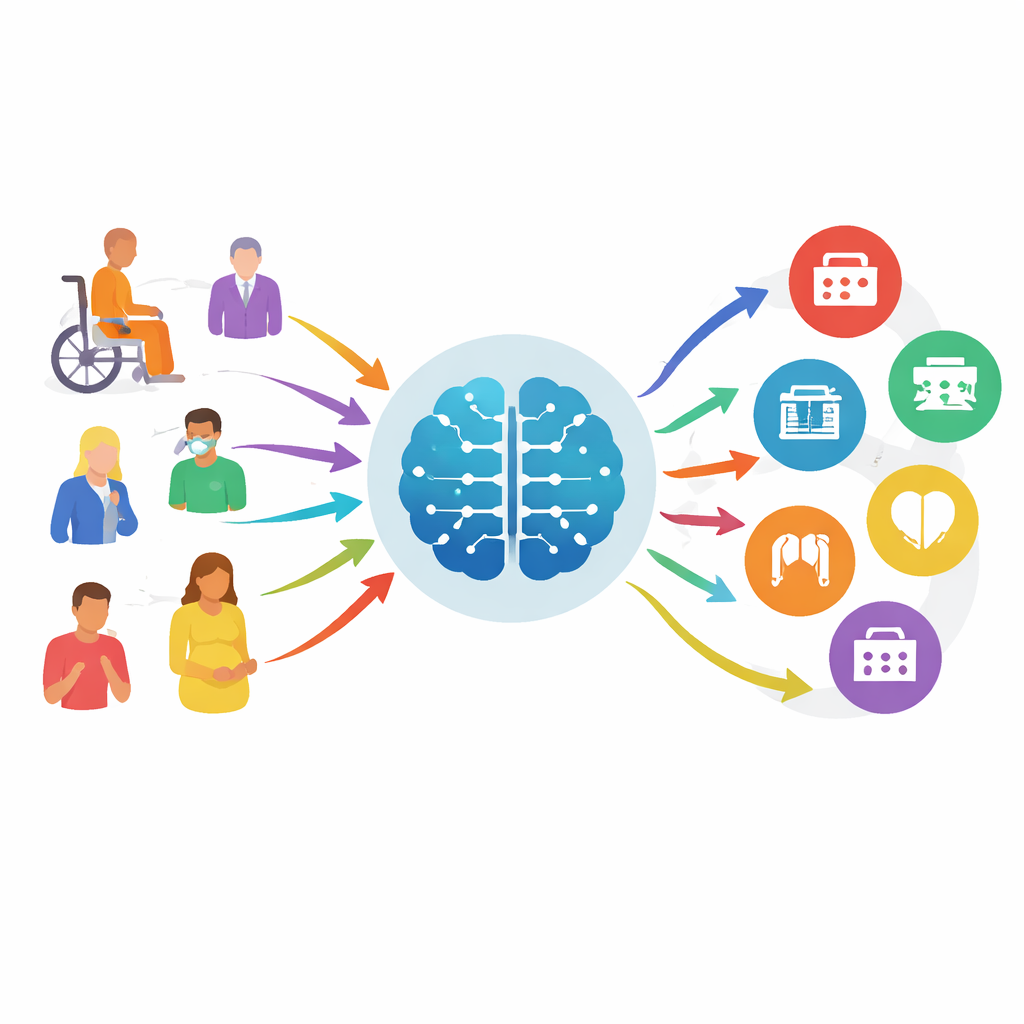
Von Vermutungen zu geführten Benchmarks
Heutige Online-Symptom-Checker schneiden oft schlecht ab, übersehen schwere Probleme und geben vage Ratschläge. Gleichzeitig werden neue große Sprachmodelle — die gleiche Art von KI, die moderne Chatbots antreibt — besser im Verstehen natürlicher Sprache und medizinischer Kontexte. Um zu prüfen, ob diese Modelle sicher bei der „Fachtriaiage“ helfen können (also zu entscheiden, welche Abteilung eine Patientin oder ein Patient aufsuchen sollte, nicht welche Krankheit vorliegt), bauten die Forschenden MedTriage auf, ein großes Benchmark aus echten, anonymisierten Fällen in fünf Hauptbereichen: Allgemeinmedizin, Pädiatrie, Gynäkologie und Geburtshilfe, Zahnmedizin und Traditionelle Chinesische Medizin. MedTriage enthält drei Eingabearten, die den Alltag widerspiegeln: kurze, an der Anmeldung orientierte Beschwerden plus Alter und Geschlecht, ausführlichere ärztliche Notizen und mehrtürige Chatprotokolle zwischen Patient und Bot aus Online-Beratungsangeboten.
Krankenhausdaten in einen fairen Wettbewerb verwandeln
Auf Basis dieses Benchmarks startete das Team einen landesweiten Wettbewerb namens MedBench und lud Krankenhäuser, Forschungslabore und Unternehmen ein, ihre besten Triage-Modelle einzureichen. Alle Teams mussten ihre Systeme einheitlich verpacken und standardisierte Testsets verwenden, die den Teilnehmenden verborgen blieben. So wurde sichergestellt, dass die Modelle fair verglichen werden und nicht einfach Antworten auswendig lernen konnten. Die Ergebnisse zeigten große Lücken: Einige Modelle behaupteten sich gut beim Übergang von Validierungsdaten zu unbekannten Testfällen, während andere stark einbrachen — ein Hinweis auf das Risiko, Systeme zu entwickeln, die intern gut aussehen, aber bei neuen Patientengruppen oder anderen Krankenhausgewohnheiten versagen.
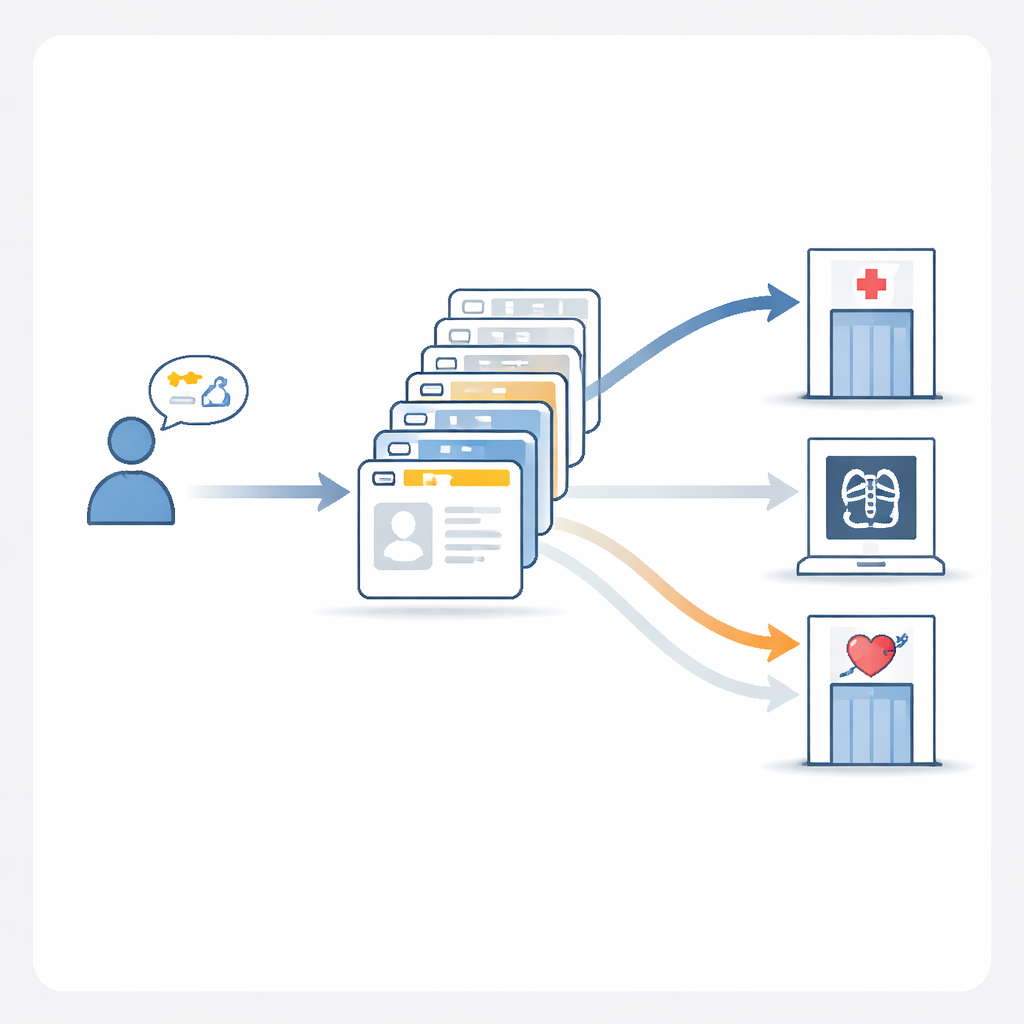
Was im Inneren der KI am besten funktioniert
Nach der Auswertung der Wettbewerbsergebnisse bauten die Autorinnen und Autoren ein eigenes Referenzmodell, MedGPT-Guide, um systematisch zu testen, was die Triagegenauigkeit tatsächlich verbessert. Sie fanden heraus, dass allein die Aufforderung an die KI, ihre Gründe Schritt für Schritt zu erklären, etwas half. Die größten Verbesserungen ergaben sich jedoch durch sorgfältig ausgewählte Beispiele. MedGPT-Guide zeigt dem Modell zwanzig vergangene Fälle — zehn, die dem neuen Patienten sehr ähnlich sind, und zehn zufällig ausgewählte — und verwendet dann eine Ensemble-Strategie, die mehrere Läufe mit zufällig durchmischten Abteilungstabellen vergleicht. Dieses „10 relevante + 10 zufällige + Ensemble“-Rezept brachte die exakte Trefferquote auf fast 80 %, deutlich besser als bei gängigen allgemeinen Modellen. In der Praxis bedeutet das, dass das System deutlich wahrscheinlicher die vollständige, korrekte Menge an Abteilungen empfiehlt, wenn die Versorgung einer Patientin oder eines Patienten mehrere Fachrichtungen erfordern könnte.
Lücken, Schutzmaßnahmen und reale Grenzen
Trotz dieser Fortschritte betont das Papier, dass KI-Triage nicht reif ist, um unbeaufsichtigt eingesetzt zu werden. Detaillierte Fehleranalysen zeigen, dass verschiedene Modelle unterschiedliche Fehlerarten machen: Einige empfehlen zu viele Abteilungen, andere übersehen wichtige. Bias bleibt ein wiederkehrendes Problem; beispielsweise könnten Modelle bestimmte Leistungen bei Kindern übermäßig vorschlagen, während sie ältere Erwachsene kaum berücksichtigen, was bestehende Ungleichheiten verschärfen könnte. Datenschutz ist eine weitere große Herausforderung, da Triage-Systeme aus sensiblen Gesundheitsgesprächen lernen, die nach Gesetzen wie HIPAA, DSGVO und Chinas PIPL geschützt werden müssen. Schließlich unterscheiden sich Vorschriften und klinische Arbeitsabläufe stark zwischen Regionen, sodass es schwierig ist, ein einzelnes System überall ohne sorgfältige lokale Anpassung und Aufsicht einzuführen.
Wie diese Arbeit die Versorgung voranbringt
Die zentrale Botschaft der Studie ist weniger ein einziges Siegermodell als vielmehr die Bedeutung, die richtige Testumgebung zu schaffen. Durch die Veröffentlichung von MedTriage und die Durchführung eines offenen Wettbewerbs zeigen die Autorinnen und Autoren, dass „evaluationsgetriebenes Training“ die KI-gesteuerte Orientierung schrittweise verbessern kann, während es zugleich Sicherheits- und Gerechtigkeitsprobleme offenlegt, die behoben werden müssen. Sie sehen KI-Systeme, die neben — nicht anstelle von — Klinikpersonal arbeiten: Breite Sprachmodelle könnten die frühe Erfassung und Weiterleitung von Patientinnen und Patienten übernehmen, während hochspezialisierte Werkzeuge sich auf enge diagnostische Aufgaben konzentrieren. Für Patientinnen und Patienten ist das letztlich ein einfaches Versprechen — ein reibungsloserer, genaueren erster Schritt ins Gesundheitssystem — vorausgesetzt, künftige Arbeit stellt Genauigkeit, Gleichheit, Datenschutz und Rechenschaftspflicht in den Mittelpunkt des Designs.
Zitation: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
Schlüsselwörter: medizinische Triage-KI, große Sprachmodelle, klinische Entscheidungsunterstützung, Benchmarking im Gesundheitswesen, Patientenweiterleitung