Clear Sky Science · en
Advancing medical AI through benchmarking and competition for specialty triage
Why smarter first stops in care matter
When people feel unwell, their first question is often simple: “Where should I go?” Yet choosing the wrong clinic or department can waste precious time and strain crowded hospitals. This paper explores how advanced artificial intelligence (AI) can help guide patients to the right medical specialty more reliably, using real conversations between patients and clinicians. By turning this messy, everyday dialogue into a rigorous test bed and public competition, the authors show how careful evaluation can push AI triage from promising demos toward safer tools that might one day sit behind hospital websites, phone apps, and registration desks.
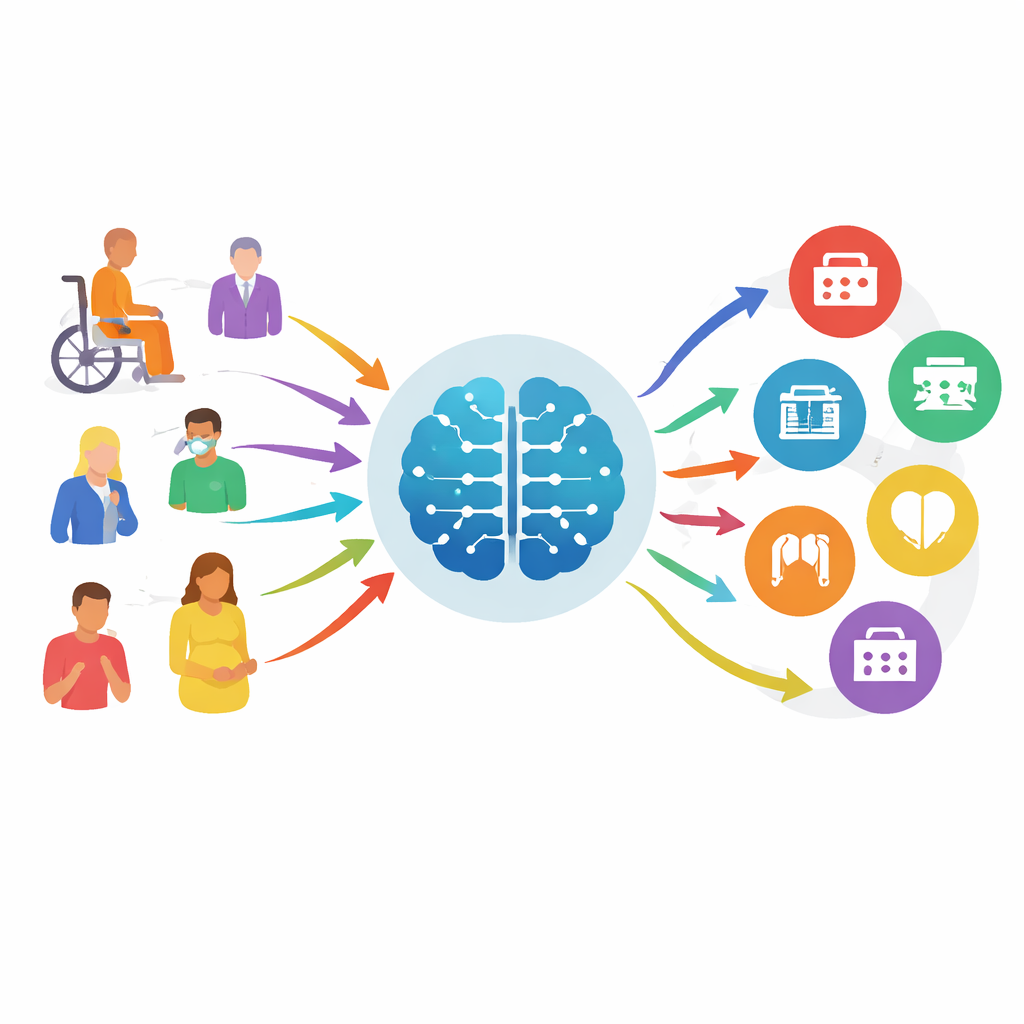
From guesswork to guided benchmarks
Today’s online symptom checkers often perform poorly, missing serious problems and offering vague guidance. At the same time, new large language models—the same kind of AI behind modern chatbots—are getting better at understanding natural language and medical context. To see whether these models can safely help with “specialty triage” (deciding which department a patient should see, not what disease they have), the researchers built MedTriage, a large benchmark made from real, anonymized records across five major areas: general medicine, pediatrics, obstetrics and gynecology, dentistry, and traditional Chinese medicine. MedTriage includes three kinds of input that mirror real life: short front-desk style complaints plus age and sex, richer clinical notes written by doctors, and multi-turn patient–bot chat logs from online guidance systems.
Turning hospital data into a fair contest
Using this benchmark, the team launched a nationwide competition called MedBench, inviting hospitals, research labs, and companies to submit their best triage models. All teams had to package their systems in the same way, using standardized test sets that were hidden from participants. This ensured that models were compared fairly and could not simply memorize the answers. The results revealed big gaps: some models held up well when moving from validation data to unseen test cases, while others fell sharply, highlighting the risk of building systems that look good in-house but fail when exposed to new patient populations or different hospital habits.
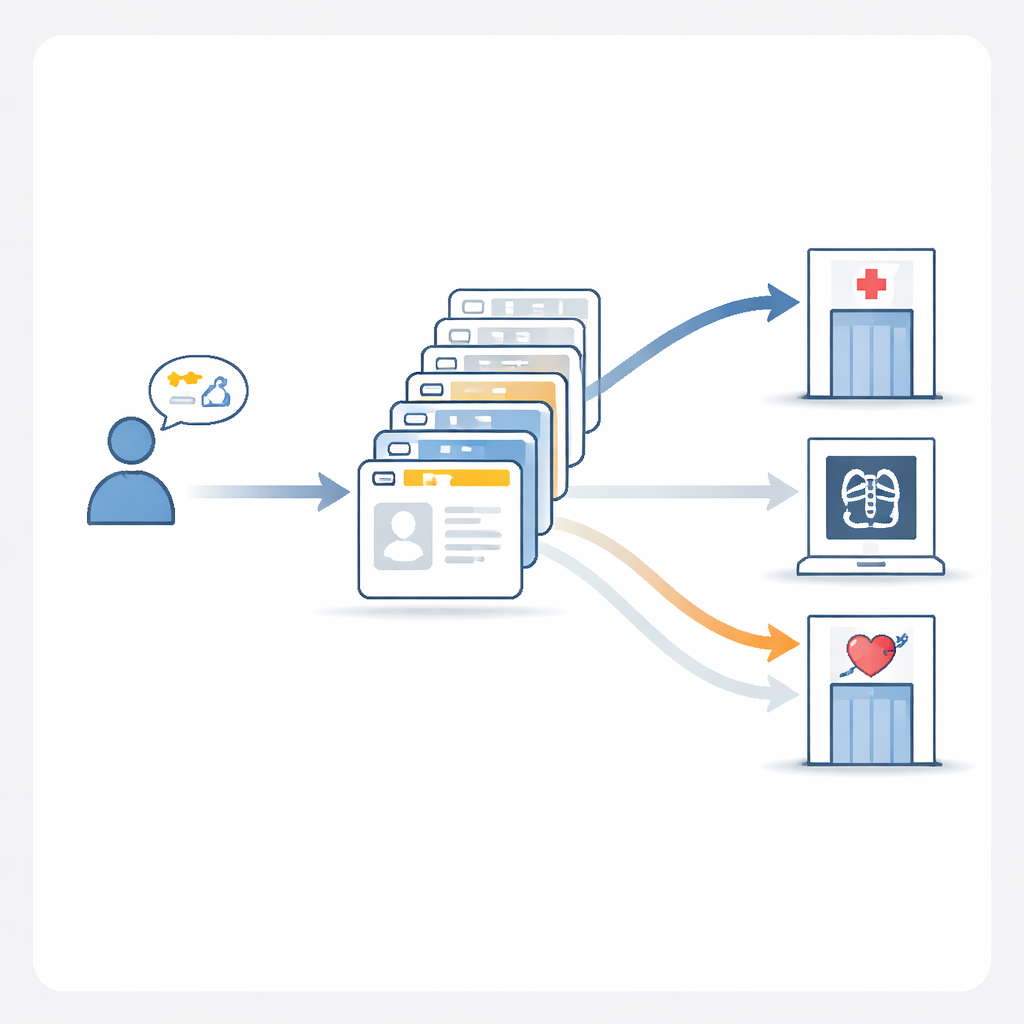
What works best inside the AI
After reviewing competition outcomes, the authors built their own reference model, MedGPT-Guide, to systematically test what actually improves triage accuracy. They found that simply asking the AI to “explain its reasoning” step by step helped somewhat, but the biggest gains came from carefully chosen examples. MedGPT-Guide shows the model twenty past cases—ten that are very similar to the new patient and ten randomly selected—then uses an ensemble strategy that compares multiple runs with shuffled department lists. This “10 relevant + 10 random + ensemble” recipe pushed exact-match accuracy close to 80%, markedly better than popular general-purpose models. In practice, this means the system is much more likely to recommend the full, correct set of departments for a patient whose care may involve more than one specialty.
Gaps, guardrails, and real-world limits
Despite this progress, the paper stresses that AI triage is not ready to run unsupervised. Detailed error analyses show that different models make different kinds of mistakes: some over-recommend many departments, others miss important ones. Bias is a recurring concern; for example, models may over-suggest certain services for children while barely doing so for older adults, potentially worsening existing inequalities. Privacy is another major challenge, because triage systems learn from sensitive health conversations that must be protected under laws like HIPAA, GDPR, and China’s PIPL. Finally, regulations and hospital workflows differ widely across regions, making it hard to deploy a single system everywhere without careful local adaptation and oversight.
How this work moves care forward
In the end, the study’s main message is less about a single winning model and more about building the right testing ground. By releasing MedTriage and running an open competition, the authors show that “evaluation-driven training” can steadily improve AI guidance while exposing safety and fairness issues that need to be fixed. They envision AI systems that work alongside, not instead of, clinicians: broad language models could handle early patient intake and routing, while highly specialized tools focus on narrow diagnostic tasks. For patients, the ultimate promise is simple—a smoother, more accurate first step into the health system—provided that future work keeps accuracy, equity, privacy, and accountability at the center of design.
Citation: Ding, C., Bian, M., Yuan, M. et al. Advancing medical AI through benchmarking and competition for specialty triage. npj Digit. Med. 9, 308 (2026). https://doi.org/10.1038/s41746-026-02433-8
Keywords: medical triage AI, large language models, clinical decision support, healthcare benchmarking, patient routing