Clear Sky Science · zh
将可解释的人工智能应用于解释监督集成学习模型以实现稳健的信用卡欺诈检测
为什么更智能的反欺诈检查与你息息相关
每次你刷卡或网购时,隐形系统都会在瞬间决定该笔支付是否安全。如果这些系统过于严格,你在杂货店结账时可能被拒付;如果它们过于宽松,犯罪分子就可能掏空你的账户。该研究探讨如何构建不仅准确而且能够解释其决策的欺诈检测器,为银行提供既有效又值得信赖的工具。
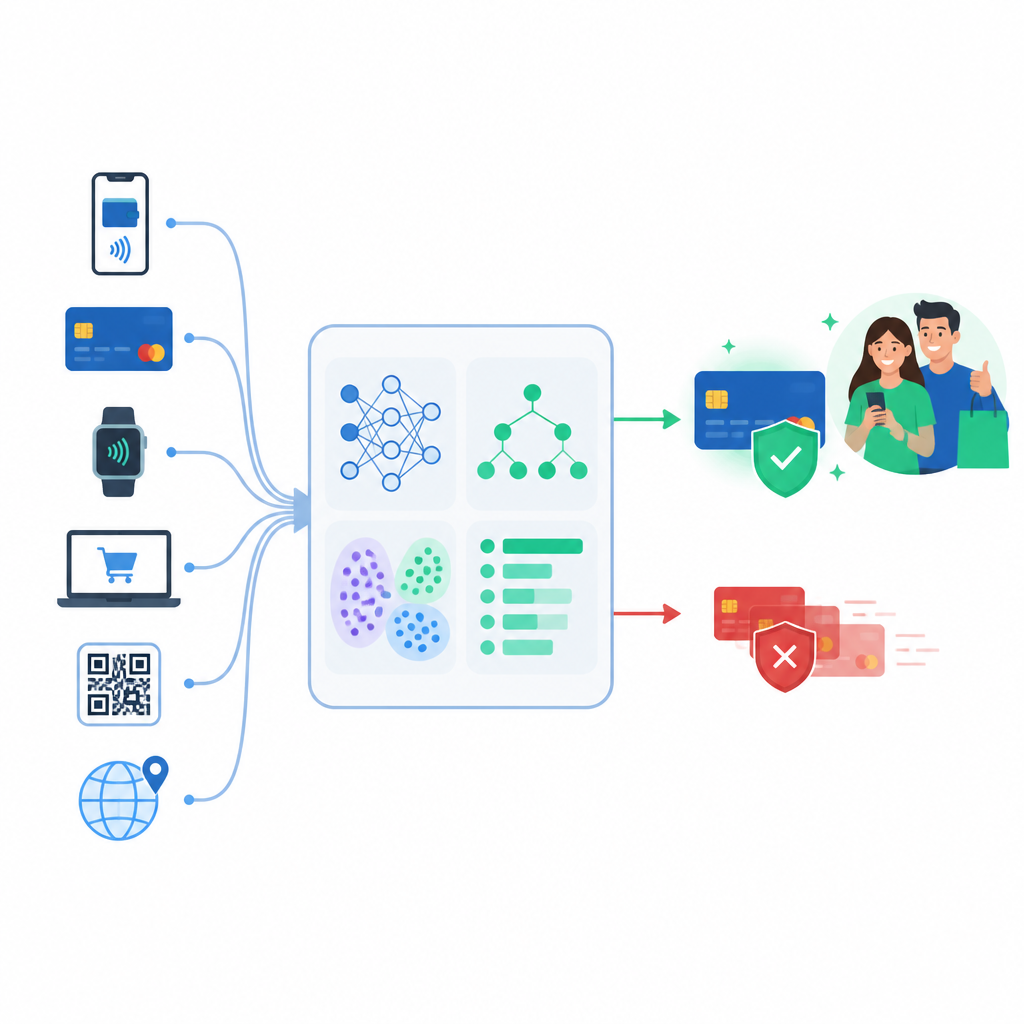
从简单规则到基于数据的学习
早期的欺诈系统主要依赖固定规则,例如阻止任何超过某一金额或在远方国家发生的消费。犯罪分子很快学会规避这些限制。作者转而研究监督式机器学习,在该方法中,模型以标注为“真实”或“欺诈”的历史交易进行训练。他们比较了四种流行方法,这些方法从简单的线性公式到更灵活的基于树的集成模型不等,后者能够捕捉消费行为中的微妙模式。
在多种用卡场景中进行测试
为了确保研究结论不依赖于某个特殊数据集,研究者在三种截然不同的刷卡交易集合上评估了这四种模型。一种是众所周知的欧洲数据集,其中欺诈案例仅占极小比例。另一种包含更丰富的细节,如地理位置、商家信息和客户数据。第三种是来自行业的更大规模的合成数据集,包含数千万笔交易。在所有这些数据上,诸如随机森林、XGBoost 和 LightGBM 等集成方法通常比更简单的基线模型更能发现可疑行为。
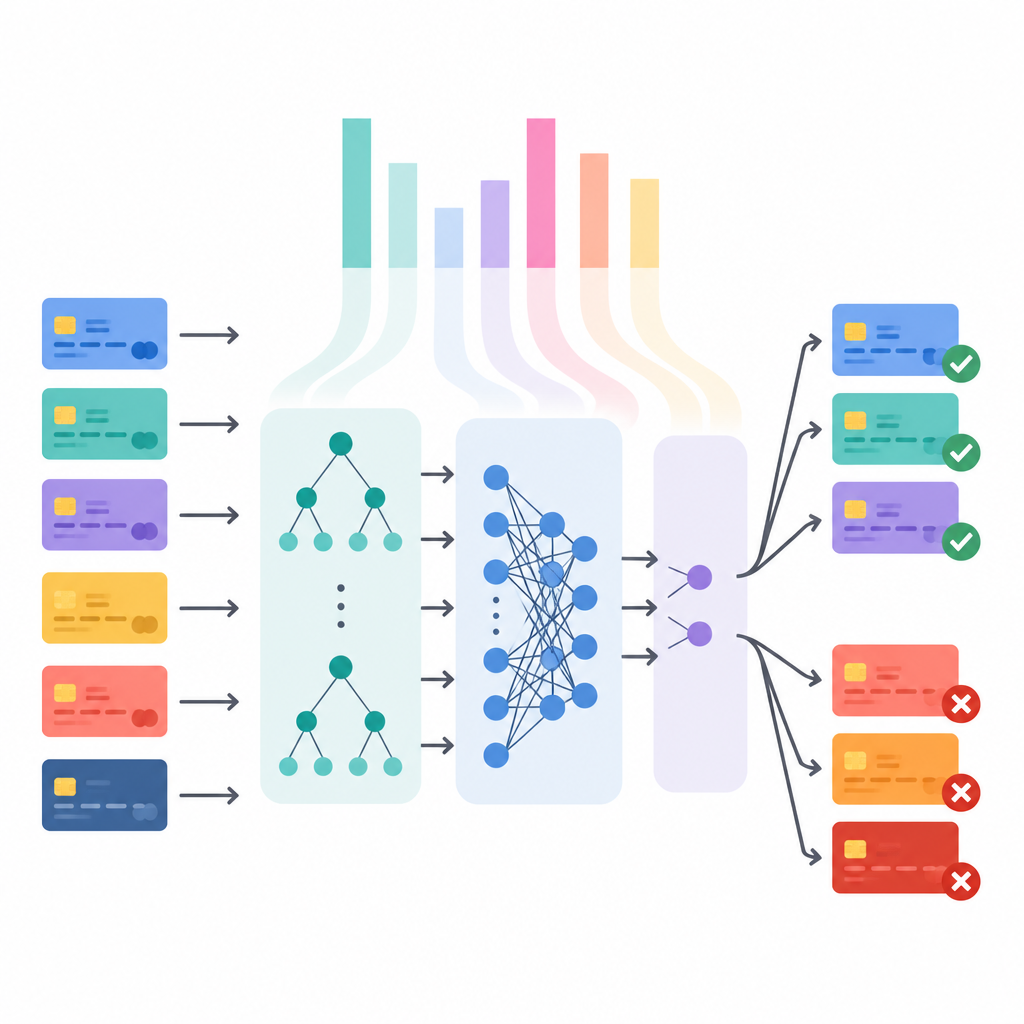
打开模型决策的黑箱
仅有高准确率不足以让银行或监管机构满意,他们越来越要求知道为何拦截某笔交易。因此,研究将预测质量与清晰度联系起来,采用了一种名为 SHAP 的方法,该方法为每个输入特征分配对最终决策的贡献度。对于整个数据集,这些解释揭示出哪些线索往往表明欺诈,例如特定的商家类别、异常的消费时间或先小额试探后跟随更大金额的模式。对于单笔交易,它们展示了哪些具体细节将模型推向“欺诈”或“合法”,为审查人员提供了明确的起点。
在漏判与误报之间取得平衡
由于欺诈性消费极为罕见,模型很容易通过将几乎所有交易判定为安全而显得准确。作者通过查看精确率、召回率及相关评分深入研究了这种不平衡,并特别关注欺诈类。他们发现某些模型(如逻辑回归)虽然能检测到许多欺诈,但会带来大量误报;而其他模型(如 XGBoost)在捕捉坏交易与不打扰真实客户之间提供了更好的折中。他们还展示了如何通过调整决策阈值,让银行按自身的风险偏好和错误成本来调整这种权衡。
将可解释的反欺诈工具带入现实世界
最后,论文概述了此类系统如何在实践中部署。作者建议采用两步设置:先由一个速度快、注重召回的模型标记可疑支付,然后由一个更精准且内置解释能力的模型对这些警报进行排序并提供理由,供人工调查员审核。他们讨论了低延迟响应、可扩展云服务和对不断变化的欺诈手法进行监控等技术需求,以及当自动化系统影响客户时需向其提供可理解理由的法律要求。
这对普通持卡人意味着什么
简言之,该研究表明现代机器学习可以使反欺诈检查既更敏锐又更透明。基于树的集成模型,尤其是 XGBoost 和 LightGBM,在多种现实数据集上通常在检测能力和可理解性之间给出最佳组合。通过将这些模型与解释工具配对并对错误成本进行谨慎调优,银行可以设计出更好地保护你的资金、减少令人沮丧的误拒并满足严格监管要求的欺诈系统。
引用: Awad, S.S., Hamza, A.A., Sobh, M.A. et al. Applying explainable artificial intelligence to interpret supervised ensemble learning models for robust credit card fraud detection. Sci Rep 16, 15220 (2026). https://doi.org/10.1038/s41598-026-49939-5
关键词: 信用卡欺诈, 可解释人工智能, 机器学习, 集成模型, 金融安全