Clear Sky Science · nl
Toepassen van verklaarbare kunstmatige intelligentie om begeleide ensemble-leermodellen te interpreteren voor robuuste detectie van creditcardfraude
Waarom slimere fraudekontroles belangrijk voor u zijn
Elke keer dat u uw kaart tikt of online winkelt, beslissen onzichtbare systemen in een fractie van een seconde of de betaling veilig is. Zijn ze te streng, dan wordt uw kaart bijvoorbeeld geweigerd in de supermarkt. Zijn ze te soepel, dan kan een crimineel uw rekening leegmaken. Deze studie onderzoekt hoe fraudedetectoren kunnen worden gebouwd die niet alleen nauwkeurig zijn, maar ook hun beslissingen kunnen toelichten, zodat banken instrumenten krijgen die zowel effectief als betrouwbaar zijn.
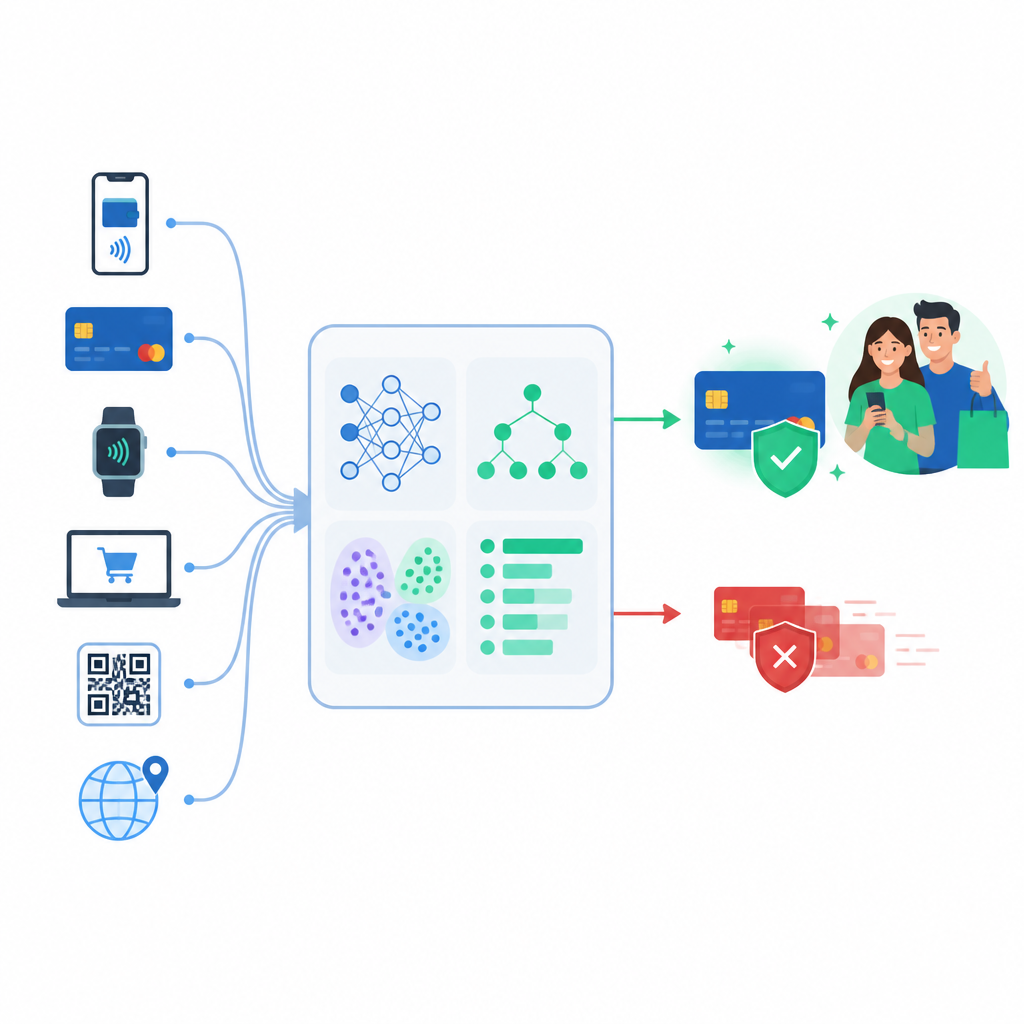
Van simpele regels naar leren van data
Oudere fraudesystemen leunden vooral op vaste regels, zoals het blokkeren van elke aankoop boven een bepaald bedrag of in een ver land. Misdadigers leerden snel deze beperkingen te omzeilen. De auteurs onderzoeken in plaats daarvan supervised machine learning, waarbij modellen worden getraind op eerdere transacties die als echt of frauduleus zijn gelabeld. Ze vergelijken vier gangbare benaderingen die variëren van eenvoudige lineaire formules tot flexibelere boomgebaseerde ensembles die subtiele patronen in bestedingsgedrag kunnen vastleggen.
Testen over veel soorten kaartgebruik
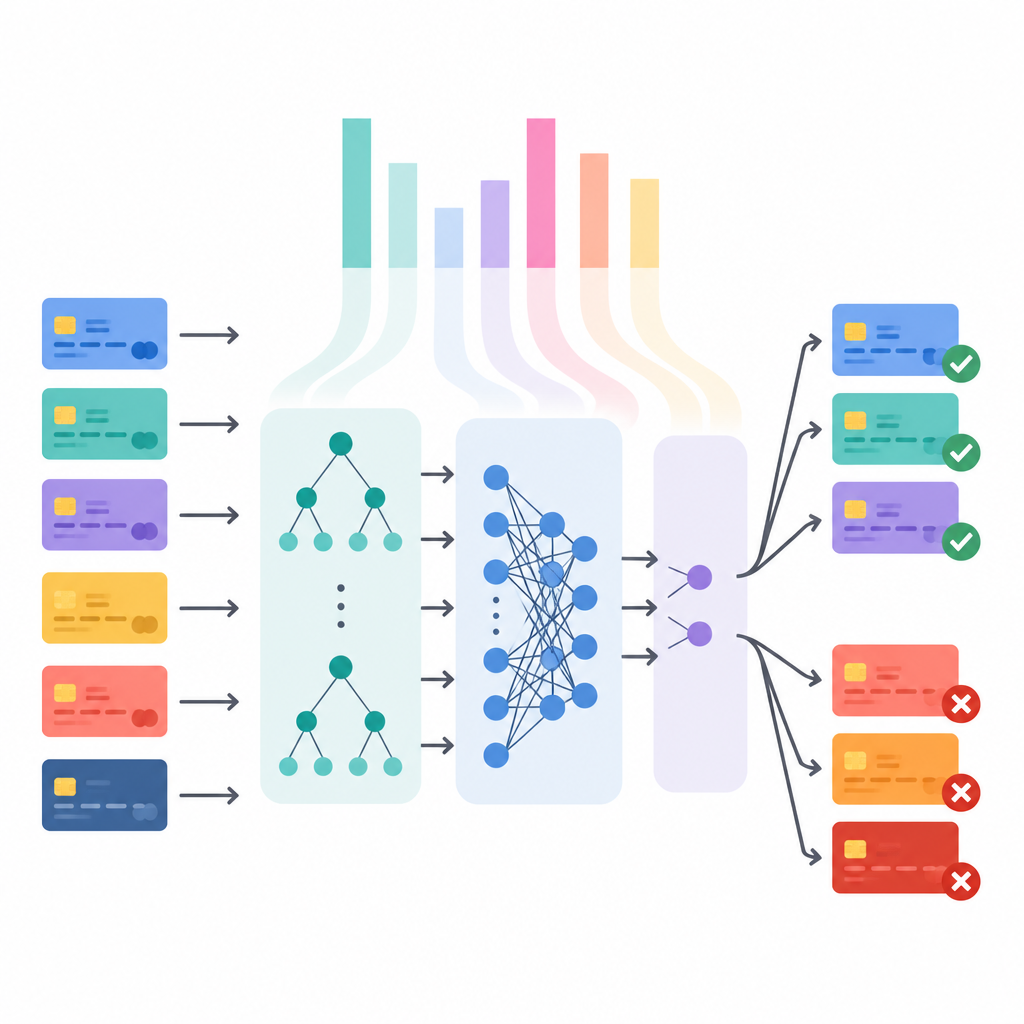
Om zeker te zijn dat hun conclusies niet aan één bijzonder dataset gebonden zijn, beoordelen de onderzoekers de vier modellen op drie zeer verschillende verzamelingen kaartbetalingen. Eén is een bekende Europese dataset met slechts een klein aandeel fraudegevallen. Een andere bevat rijkere details zoals locatie, informatie over de handelaar en klantgegevens. Een derde, veel grotere synthetische set uit de industrie bevat tientallen miljoenen transacties. In al deze datasets signaleren ensemblemethoden zoals Random Forest, XGBoost en LightGBM verdacht gedrag meestal veel beter dan het eenvoudigere basismodel.
De zwarte doos van modelbeslissingen openen
Hoge nauwkeurigheid alleen is niet genoeg voor banken of toezichthouders, die steeds vaker willen weten waarom een bepaalde transactie is geblokkeerd. Daarom koppelt de studie voorspellingskwaliteit aan duidelijkheid met een methode genaamd SHAP, die elke invoerkenmerk een bijdrage toekent aan de eindbeslissing. Voor volledige datasets onthullen deze verklaringen welke aanwijzingen gewoonlijk op fraude duiden, zoals bepaalde winkelcategorieën, ongebruikelijke tijdstippen van aankopen of patronen van kleine testkosten gevolgd door grotere aankopen. Voor individuele betalingen laten ze zien welke specifieke details het model richting ‘fraude’ of ‘legitiem’ duwden, wat analisten een duidelijk startpunt geeft voor beoordeling.
Balanceren tussen gemiste fraude en valse alarmen
Aangezien frauduleuze aankopen zo zeldzaam zijn, kan een model gemakkelijk als nauwkeurig lijken door bijna alles als veilig te bestempelen. De auteurs gaan die onbalans te lijf door te kijken naar precision, recall en aanverwante scores, met speciale aandacht voor de fraudeklasse zelf. Ze vinden dat sommige modellen, zoals logistische regressie, veel fraude kunnen opsporen maar dat vaak ten koste van enorme aantallen valse meldingen gaat, terwijl andere modellen, zoals XGBoost, een betere compromis bieden tussen het vangen van slechte transacties en het ongemoeid laten van echte klanten. Ze tonen ook aan hoe het verschuiven van de beslissingsdrempel banken in staat stelt deze afweging af te stemmen op hun eigen risicovoorkeur en de financiële kosten van fouten.
Verklaarbare fraudetools in de praktijk brengen
Tot slot schetst het artikel hoe zulke systemen in de praktijk kunnen worden ingezet. De auteurs suggereren een tweestapsopzet waarbij eerst een snel, op recall gericht model verdachte betalingen markeert, en een preciezer model met ingebouwde verklaringen die waarschuwingen vervolgens rangschikt en onderbouwt voor menselijke onderzoekers. Ze bespreken technische vereisten zoals lage responstijden, schaalbare clouddiensten en monitoring voor veranderende fraudepraktijken, evenals juridische vereisten dat klanten begrijpelijke redenen krijgen wanneer geautomatiseerde systemen hen raken.
Wat dit betekent voor alledaagse kaarthouders
In eenvoudige bewoordingen laat de studie zien dat moderne machine learning fraudecontroles zowel scherper als transparanter kan maken. Boomgebaseerde ensemblemodellen, met name XGBoost en LightGBM, geven doorgaans de beste mix van detectiekracht en begrijpelijke onderbouwing over meerdere realistische datasets. Door deze modellen te combineren met verklaringshulpmiddelen en zorgvuldige afstemming van foutkosten, kunnen banken fraudesystemen ontwerpen die uw geld beter beschermen, terwijl ze frustrerende onterechte weigeringen verminderen en voldoen aan strikte regelgeving.
Bronvermelding: Awad, S.S., Hamza, A.A., Sobh, M.A. et al. Applying explainable artificial intelligence to interpret supervised ensemble learning models for robust credit card fraud detection. Sci Rep 16, 15220 (2026). https://doi.org/10.1038/s41598-026-49939-5
Trefwoorden: creditcardfraude, verklaarbare AI, machine learning, ensemblemodellen, financiële veiligheid