Clear Sky Science · it
Applicare l'intelligenza artificiale spiegabile per interpretare modelli di apprendimento supervisionato ensemble per una rilevazione robusta delle frodi con carta di credito
Perché controlli antifrode più intelligenti sono importanti per te
Ogni volta che posi la carta o fai acquisti online, sistemi invisibili decidono in una frazione di secondo se il pagamento è sicuro. Se sono troppo severi, la carta viene rifiutata al supermercato. Se sono troppo permissivi, un criminale può svuotare il conto. Questo studio esamina come costruire rilevatori di frodi che non siano solo accurati ma che possano anche spiegare le loro decisioni, fornendo alle banche strumenti efficaci e affidabili.
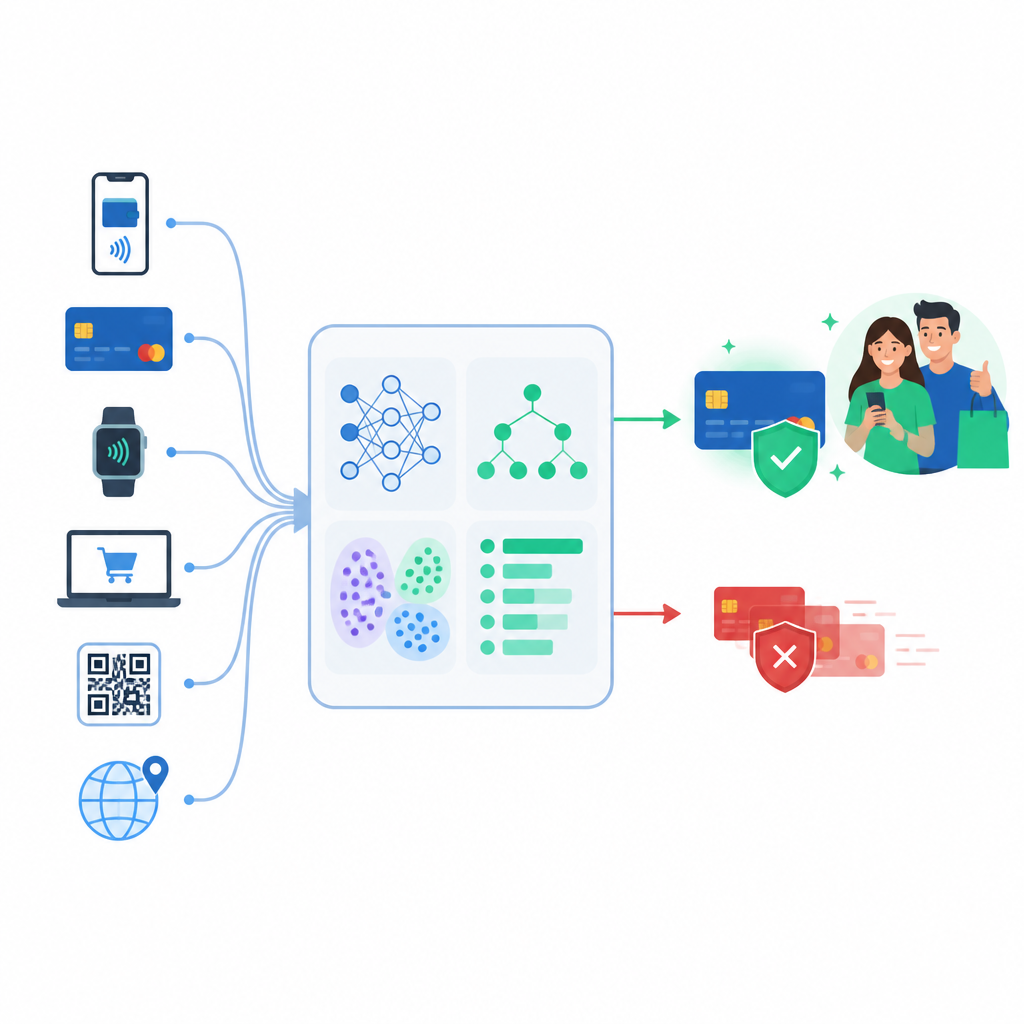
Da regole semplici all'apprendimento dai dati
I vecchi sistemi antifrode si basavano soprattutto su regole fisse, come bloccare qualsiasi acquisto sopra una certa somma o in un paese lontano. I criminali hanno rapidamente imparato a aggirare quei limiti. Gli autori invece esplorano il machine learning supervisionato, dove i modelli vengono addestrati su transazioni passate etichettate come genuine o fraudolente. Confrontano quattro approcci diffusi che vanno da formule lineari semplici a ensemble basati su alberi più flessibili, capaci di cogliere schemi sottili nel comportamento di spesa.
Testare su molti tipi di utilizzo della carta
Per assicurarsi che i risultati non siano legati a un dataset particolare, i ricercatori valutano i quattro modelli su tre raccolte di pagamenti con carta molto diverse. Una è un noto dataset europeo con solo una piccolissima frazione di casi di frode. Un'altra include dettagli più ricchi come posizione, informazioni sul commerciante e dati del cliente. Una terza, molto più ampia e sintetica proveniente dall'industria, contiene decine di milioni di transazioni. Su tutti, metodi ensemble come Random Forest, XGBoost e LightGBM individuano di solito comportamenti sospetti molto meglio del modello di base più semplice.
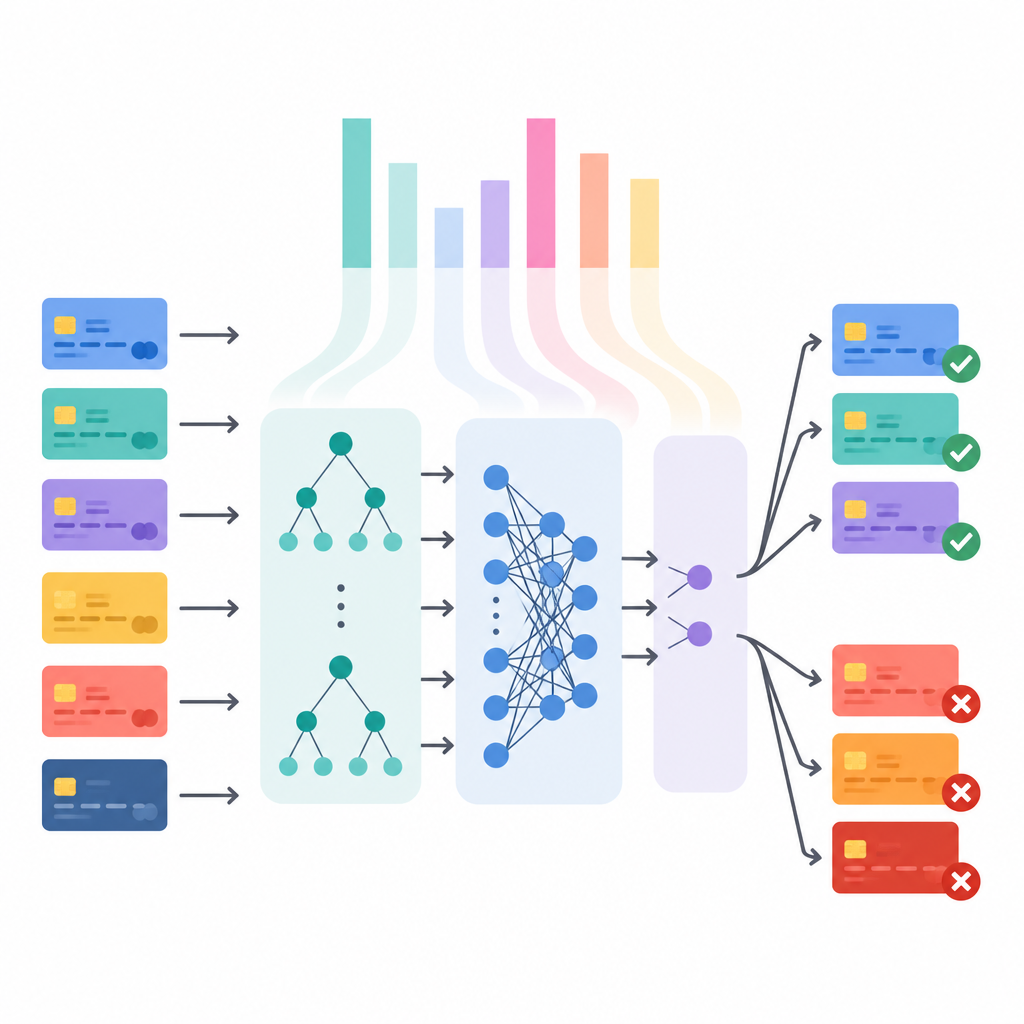
Aprire la scatola nera delle decisioni del modello
Un'alta accuratezza da sola non basta per banche o regolatori, che richiedono sempre più spesso di sapere perché una certa transazione è stata bloccata. Lo studio collega quindi la qualità delle predizioni alla chiarezza usando un metodo chiamato SHAP, che assegna a ciascuna caratteristica di input un contributo verso la decisione finale. Per interi dataset, queste spiegazioni rivelano quali indizi tendono a segnalare frode, come particolari categorie di commerciante, tempistiche insolite degli acquisti o schemi di piccoli addebiti di prova seguiti da importi più grandi. Per singole transazioni, mostrano come dettagli specifici hanno spinto il modello verso “frode” o “legittimo”, offrendo agli analisti un punto di partenza chiaro per la revisione.
Bilanciare frodi mancate e falsi allarmi
Poiché gli acquisti fraudolenti sono così rari, è facile che un modello sembri accurato semplicemente classificando quasi tutto come sicuro. Gli autori approfondiscono questo squilibrio esaminando precisione, richiamo e punteggi correlati, prestando particolare attenzione alla classe delle frodi. Riscontrano che alcuni modelli, come la regressione logistica, possono catturare molte frodi ma a prezzo di un numero enorme di falsi allarmi, mentre altri, come XGBoost, offrono un compromesso migliore tra intercettare transazioni dannose e lasciare indisturbati i clienti genuini. Mostrano anche come spostare la soglia decisionale permetta alle banche di regolare questo trade-off in base alla propria propensione al rischio e ai costi finanziari degli errori.
Portare strumenti antifrode spiegabili nel mondo reale
Infine, l'articolo delinea come tali sistemi potrebbero essere implementati in pratica. Gli autori suggeriscono una configurazione in due fasi in cui un modello rapido e orientato al richiamo segnala prima i pagamenti sospetti, e un modello più preciso con spiegazioni integrate poi classifica e giustifica quegli avvisi per gli investigatori umani. Discutono esigenze tecniche come bassi tempi di risposta, servizi cloud scalabili e monitoraggio per tattiche di frode in evoluzione, oltre ai requisiti legali perché i clienti ricevano motivazioni comprensibili quando i sistemi automatizzati li riguardano.
Cosa significa per gli utenti di tutti i giorni
In termini semplici, lo studio mostra che il machine learning moderno può rendere i controlli antifrode sia più efficaci sia più trasparenti. I modelli ensemble basati su alberi, in particolare XGBoost e LightGBM, tendono a offrire il miglior equilibrio tra potenza di rilevamento e ragionamento comprensibile su più dataset realistici. Abbinando questi modelli a strumenti di spiegazione e a un'attenta taratura dei costi degli errori, le banche possono progettare sistemi antifrode che proteggono meglio il tuo denaro riducendo rifiuti frustranti e rispettando rigidi standard normativi.
Citazione: Awad, S.S., Hamza, A.A., Sobh, M.A. et al. Applying explainable artificial intelligence to interpret supervised ensemble learning models for robust credit card fraud detection. Sci Rep 16, 15220 (2026). https://doi.org/10.1038/s41598-026-49939-5
Parole chiave: frode con carta di credito, IA spiegabile, machine learning, modelli ensemble, sicurezza finanziaria