Clear Sky Science · zh
使用SNOMED-CT和临床笔记的端到端自动化心力衰竭诊断流程
为何更聪明地阅读病历很重要
心力衰竭常见且致命,且常常被诊断得太晚。然而,关于患者的许多早期预警信息并不在整齐的勾选框或化验表中,而是埋藏在医生的自由文本笔记里。该研究展示了人工智能如何将这些写在德语中的凌乱笔记与常规医院数据一起,转化为每位患者的结构化视图,并利用该视图帮助医生判断谁有或没有心力衰竭。
从零散文字到有序信息
医生的笔记信息丰富但混乱:包含速记、缩写以及不同的表达方式。作者构建了一个端到端的数字化流程,起点是这些原始笔记加上846名住院患者(有心力衰竭和无心力衰竭)的标准电子病历(EHR)数据。首先,系统基于上下文自动扩展缩写,使“HT”这样的简短代码能被正确解释为“高血压”,而不是例如“头部外伤”。它以“零样本”(zero-shot)方式完成此任务,依赖大语言模型和示例句子,而不是为每个缩写手工标注训练数据。
跨越语言障碍并链接到医学地图
由于许多现有工具和参考术语以英语为基础,下一步将德语临床笔记翻译成英语。翻译之后,流程在文本中搜索有医学意义的短语并将其链接到SNOMED‑CT——一个大型的、分层组织的疾病、体征和操作“地图”,以及更广泛的UMLS术语库。系统并非只做精确字符串匹配,而是使用语义相似度:将笔记片段和所有候选概念描述嵌入到数值空间中,检索最接近的匹配。两阶段流程——先宽松地收集候选项,然后更严格地过滤并利用上下文示例——在高覆盖率与高精确度之间取得平衡,并可根据真实数据和临床医生的反馈不断改进。
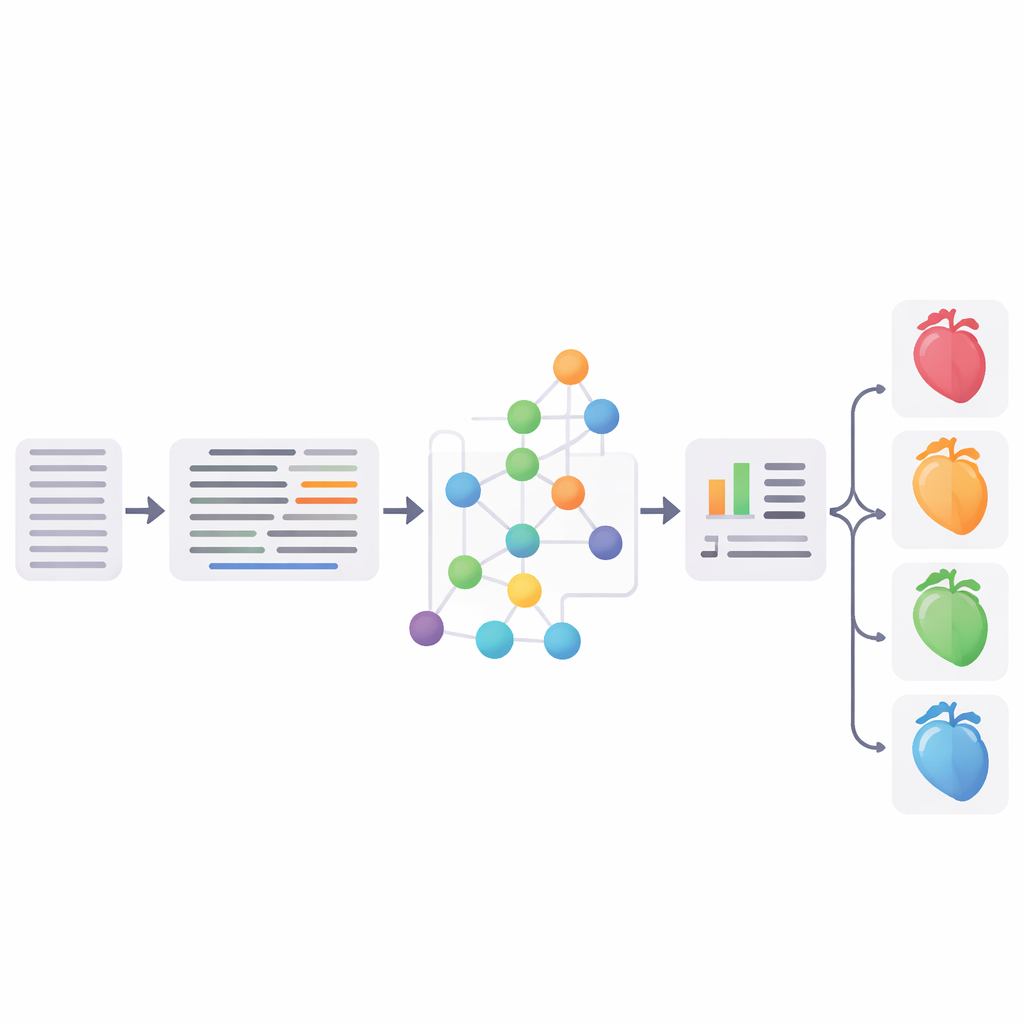
将流程投入测试
研究人员对每个主要步骤进行了严格评估。在广泛使用的英文测试集上,他们的缩写扩展总准确率最高达到96.1%,可与或超过早期方法。其实体链接方法在得分上与已建立的MedCAT工具包具有竞争力,对德语记录上链接的三位心脏病学家的评审显示约四分之三被判断为完全匹配。最后,团队将标准化的SNOMED‑CT概念与结构化EHR信息(如年龄、化验值和诊断)结合,训练了支持向量机分类器,将患者分为四类:无心力衰竭和三种主要的心力衰竭亚型。最佳版本达到65.3%的F1分数,在本质上与基于微调德语医学BERT模型的强神经基线相当。
系统做得好之处与薄弱环节
分类器在识别无心力衰竭患者(约86%准确率)以及明确泵功能下降的患者方面表现尤其出色。对功能轻度下降的“中间”组表现较差,这一组对医生来说也难以判断,且常与其他形式在临床上重叠。作者的方法有若干优点:即使训练数据稀缺也能工作;比黑盒神经文本模型更具可解释性,因为预测与明确的医学概念相连;并有助于使德语笔记与国际标准互操作。与此同时,研究也指出了剩余的挑战,包括相似概念之间偶发的错误链接、捕捉症状严重程度等细微差别的困难,以及出院小结可能已经包含晚期线索,使得任务比真正的早期检测更容易。
这对患者和医生意味着什么
通俗地说,这项工作表明计算机能够学习阅读并组织复杂的临床笔记,足以在诊断心力衰竭方面辅助工作,达到与最前沿神经网络相当的水平,同时更易解释并更容易适应新的医院和语言。通过将非结构化文本转化为共享医学地图上的标准化构件,该流程为能够更早标记高危患者、帮助避免漏诊或延误诊断并支持更个性化护理的决策支持工具铺平了道路——首先用于心力衰竭,最终可推广到许多其他疾病。
引用: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
关键词: 心力衰竭诊断, 临床笔记, SNOMED CT, 医学文本挖掘, 临床决策支持