Clear Sky Science · de
End-to-End‑Pipeline zur automatisierten Herzinsuffizienz‑Diagnose aus klinischen Notizen mithilfe von SNOMED‑CT
Warum ein klügeres Lesen medizinischer Notizen wichtig ist
Herzinsuffizienz ist weit verbreitet, tödlich und wird häufig zu spät diagnostiziert. Viele Frühwarnzeichen sind jedoch in den frei formulierten Arztnotizen verborgen und nicht in übersichtlichen Checkboxen oder Laborwerttabellen zu finden. Diese Studie zeigt, wie künstliche Intelligenz diese unordentlichen Notizen – in deutscher Sprache verfasst – zusammen mit routinemäßigen Krankenhausdaten in eine strukturierte Sicht auf jeden Patienten überführt und wie diese Sicht Ärzte dabei unterstützt zu entscheiden, wer eine Herzinsuffizienz hat und wer nicht.
Von verstreuten Worten zu organisierten Informationen
Arztnotizen sind reichhaltig, aber chaotisch: sie enthalten Kurzformen, Abkürzungen und verschiedene Formulierungen für dasselbe. Die Autoren entwickelten eine End‑to‑End‑Digitalkette, die bei diesen Rohnotizen plus standardisierten elektronischen Gesundheitsdaten (EHR) von 846 Krankenhauspatienten mit und ohne Herzinsuffizienz ansetzt. Zuerst erweitert das System automatisch Abkürzungen kontextabhängig, sodass ein kurzer Code wie „HT“ korrekt als „Hypertonie“ interpretiert wird und nicht etwa als „head trauma“. Dies geschieht in einer „Zero‑Shot“-Weise, also unter Nutzung großer Sprachmodelle und Beispielsätzen statt handbeschrifteter Trainingsdaten für jede einzelne Abkürzung.
Die Sprachbarriere überwinden und auf eine medizinische Karte verlinken
Da viele vorhandene Werkzeuge und Referenzterminologien auf Englisch basieren, übersetzt der nächste Schritt die deutschen klinischen Notizen ins Englische. Nach der Übersetzung durchsucht die Pipeline medizinisch aussagekräftige Phrasen und verknüpft sie mit Konzepten in SNOMED‑CT, einer großen, hierarchisch organisierten „Landkarte“ von Krankheiten, Befunden und Verfahren, sowie mit der umfassenden UMLS‑Terminologie. Statt nur exakte Zeichenketten abzugleichen, verwendet das System semantische Ähnlichkeit: Es bettet sowohl Textfragmente aus den Notizen als auch alle Kandidaten‑Konzeptbeschreibungen in einen numerischen Raum ein und holt die nächsten Treffer. Ein zweistufiger Prozess – zunächst großzügige Kandidatensammlung, dann striktere Filterung und Nutzung von Kontextbeispielen – balanciert hohe Abdeckung mit Präzision und lässt sich im Laufe der Zeit durch Feedback aus realen Daten und von Klinikern verfeinern.
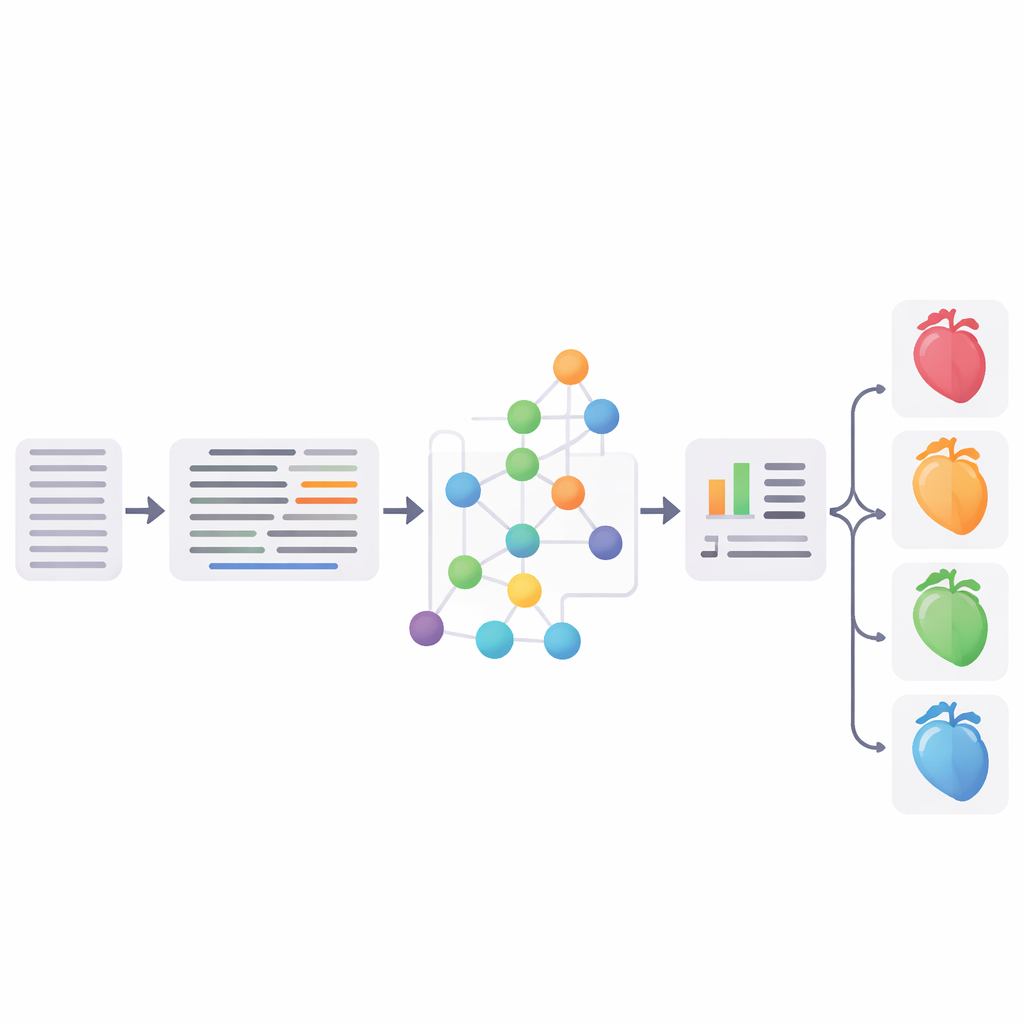
Die Pipeline auf die Probe gestellt
Die Forschenden evaluierten jeden wichtigen Schritt gründlich. Auf weit verbreiteten englischen Testsets erreichte ihre Abkürzungserweiterung bis zu 96,1 % Gesamtgenauigkeit und konnte frühere Methoden erreichen oder übertreffen. Ihr Entity‑Linking‑Ansatz erzielte konkurrierende Werte im Vergleich zum etablierten MedCAT‑Toolkit, und eine Begutachtung durch drei Kardiologen, die Verknüpfungen in deutschen Datensätzen prüften, bewertete etwa drei Viertel davon als vollständige Übereinstimmungen. Schließlich kombinierten die Autoren die standardisierten SNOMED‑CT‑Konzepte mit strukturierten EHR‑Informationen (z. B. Alter, Laborwerte und Diagnosen) und trainierten einen Support‑Vector‑Machine‑Klassifikator, der Patienten in vier Gruppen einteilte: keine Herzinsuffizienz und drei Hauptuntertypen der Herzinsuffizienz. Die beste Version erreichte eine F1‑Score von 65,3 % und entsprach damit im Wesentlichen einem starken neuronalen Baseline‑Modell, das auf einem feinabgestimmten deutschen medizinischen BERT basierte.
Was das System gut kann – und wo es Schwierigkeiten hat
Der Klassifikator war besonders gut darin, Patienten ohne Herzinsuffizienz zu erkennen (etwa 86 % Genauigkeit) sowie solche mit deutlich eingeschränkter Pumpfunktion. Weniger gut funktionierte die Einordnung der „Zwischen“-Gruppe mit leicht verminderter Funktion, die auch für Ärztinnen und Ärzte schwierig ist und klinisch oft mit anderen Formen überlappt. Der Ansatz der Autoren bietet mehrere Vorteile: Er funktioniert auch bei knappen Trainingsdaten, er ist transparenter als Black‑Box‑neuronale Textmodelle, weil Vorhersagen an explizite medizinische Konzepte gebunden sind, und er erleichtert die Interoperabilität deutscher Notizen mit internationalen Standards. Gleichzeitig zeigt die Studie verbleibende Herausforderungen auf, darunter gelegentliche Fehlverknüpfungen ähnlicher Konzepte, die Schwierigkeit, Nuancen wie Symptomschwere zu erfassen, und die Möglichkeit, dass Entlassungsberichte bereits Spätstadien‑Hinweise enthalten, die die Aufgabe leichter erscheinen lassen als eine wirklich frühe Erkennung.
Was das für Patientinnen, Patienten und Ärztinnen und Ärzte bedeutet
Einfach gesagt demonstriert diese Arbeit, dass Computer klinische Notizen so gut lesen und organisieren können, dass sie bei der Diagnose von Herzinsuffizienz mit modernen neuronalen Netzwerken vergleichbar unterstützen, dabei jedoch besser interpretierbar und einfacher an neue Krankenhäuser und Sprachen anzupassen sind. Indem unstrukturierter Text in standardisierte Bausteine auf einer gemeinsamen medizinischen Karte überführt wird, ebnet die Pipeline den Weg für Entscheidungsunterstützungstools, die gefährdete Patientinnen und Patienten früher markieren, verpasste oder verzögerte Diagnosen verhindern und eine individuellere Versorgung unterstützen können – zuerst bei Herzinsuffizienz und schließlich bei vielen weiteren Erkrankungen.
Zitation: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Schlüsselwörter: Herzinsuffizienz‑Diagnose, klinische Notizen, SNOMED CT, medizinische Textanalyse, klinische Entscheidungsunterstützung