Clear Sky Science · pt
Pipeline de ponta a ponta para diagnóstico automatizado de insuficiência cardíaca a partir de anotações clínicas usando SNOMED-CT
Por que uma leitura mais inteligente das anotações médicas importa
A insuficiência cardíaca é comum, letal e frequentemente diagnosticada tardiamente. No entanto, grande parte das informações de alerta precoces sobre um paciente está enterrada nas anotações em texto livre dos médicos, em vez de em caixas de seleção ou tabelas de exames organizadas. Este estudo mostra como a inteligência artificial pode transformar essas anotações confusas — escritas em alemão — e dados hospitalares de rotina em uma visão estruturada de cada paciente e, em seguida, usar essa visão para ajudar os médicos a decidir quem tem ou não insuficiência cardíaca.
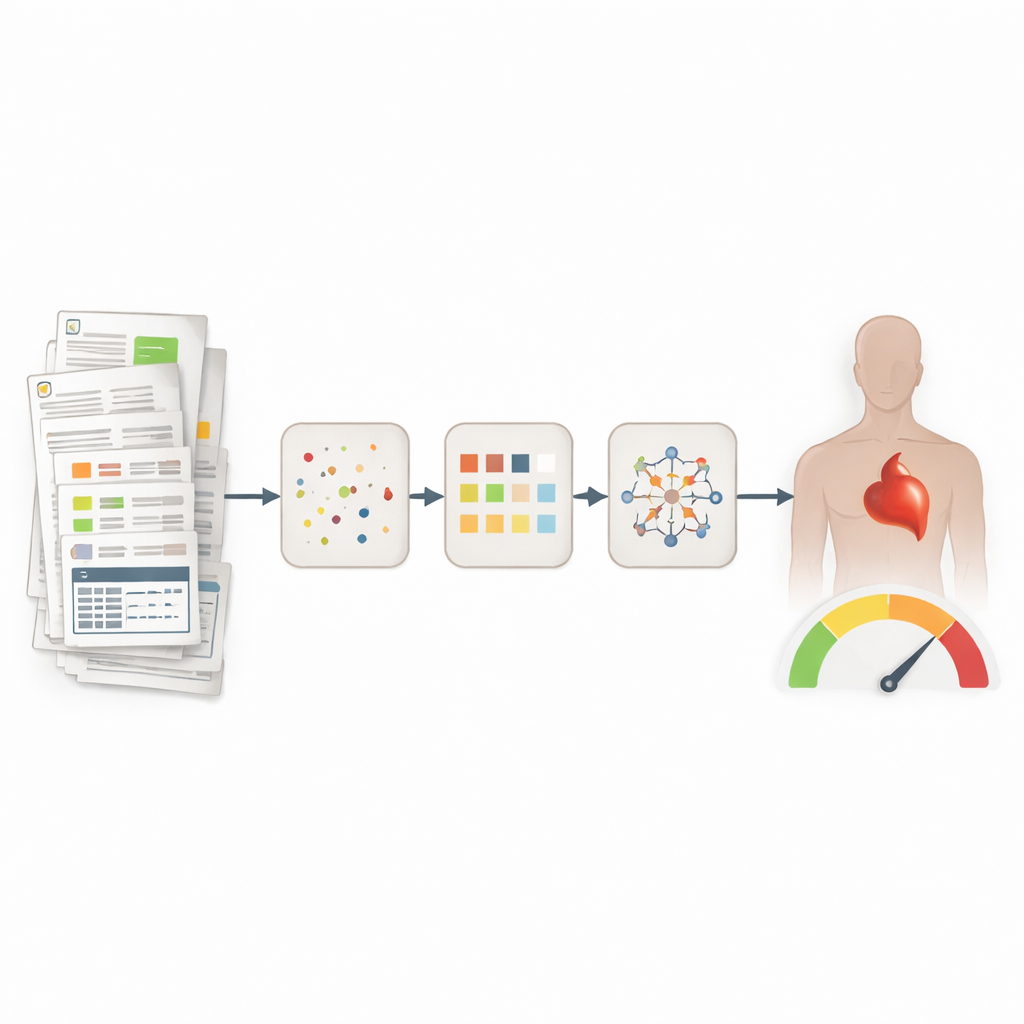
De palavras dispersas a informações organizadas
As anotações dos médicos são ricas, mas caóticas: contêm jargão, abreviações e diferentes formas de expressar a mesma coisa. Os autores construíram um pipeline digital de ponta a ponta que parte dessas anotações brutas, além de dados padrão de prontuário eletrônico (EHR), para 846 pacientes hospitalizados com e sem insuficiência cardíaca. Primeiro, o sistema expande automaticamente abreviações com base na frase ao redor, de modo que um código curto como “HT” seja interpretado corretamente como “hipertensão” em vez de, por exemplo, “trauma craniano”. Isso é feito de maneira “zero-shot”, apoiando‑se em grandes modelos de linguagem e frases de exemplo, em vez de depender de dados anotados manualmente para cada abreviação.
Ultrapassando a barreira linguística e vinculando a um mapa médico
Como muitas ferramentas e terminologias de referência existentes são baseadas em inglês, o próximo passo traduz as notas clínicas em alemão para o inglês. Após a tradução, o pipeline busca frases com significado médico e as vincula a conceitos do SNOMED‑CT, um grande “mapa” hierarquicamente organizado de doenças, achados e procedimentos, além de ligá‑las à ampla terminologia UMLS. Em vez de apenas combinar strings exatas, o sistema usa similaridade semântica: incorpora tanto os fragmentos das notas quanto todas as descrições candidatas de conceitos em um espaço numérico e recupera as correspondências mais próximas. Um processo em duas etapas — primeiro a coleta generosa de candidatos e depois um filtro mais rigoroso e uso de exemplos de contexto — equilibra alta cobertura com precisão, e pode ser refinado ao longo do tempo usando feedback de dados reais e de clínicos.
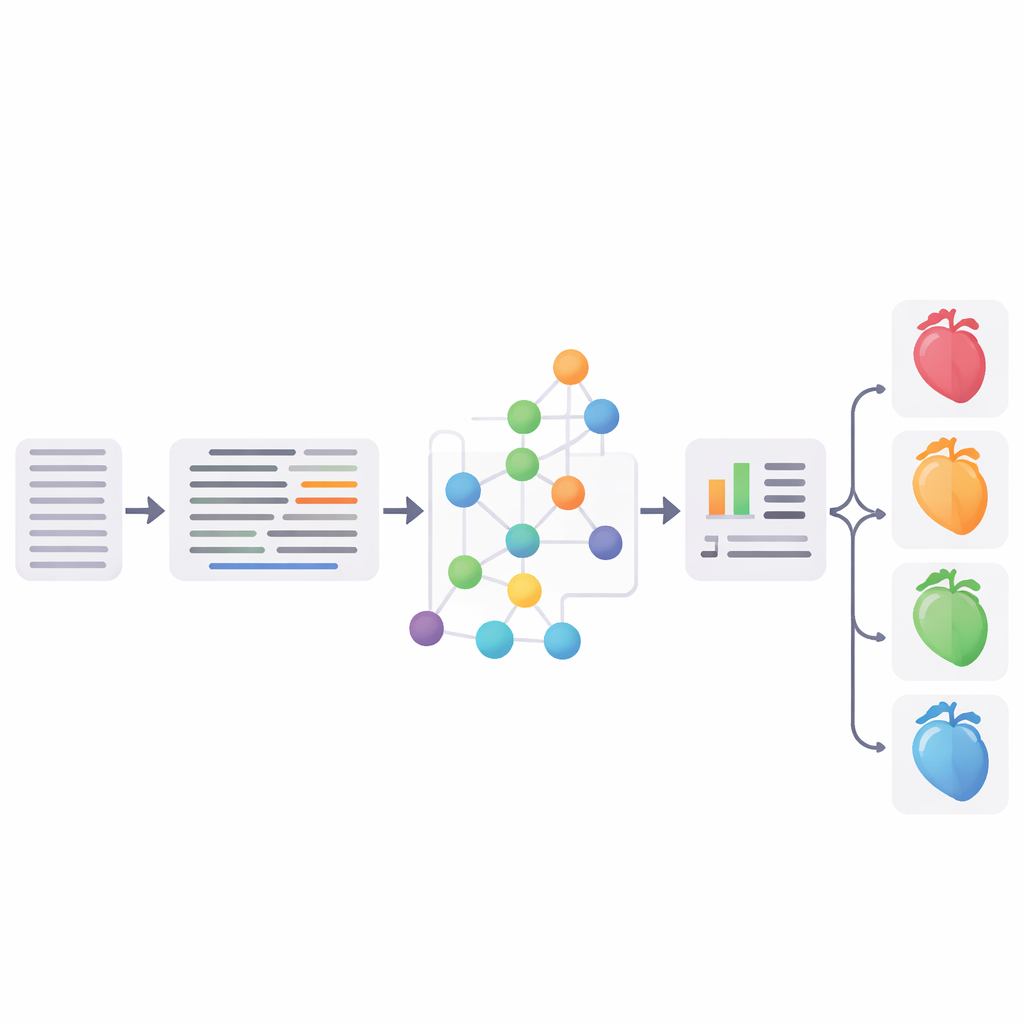
Testando o pipeline
Os pesquisadores avaliaram rigorosamente cada etapa principal. Em conjuntos de teste amplamente usados em inglês, a expansão de abreviações alcançou até 96,1% de acurácia total, rivalizando ou superando métodos anteriores. A abordagem de vinculação de entidades obteve scores competitivos em comparação com a ferramenta estabelecida MedCAT, e uma avaliação de três cardiologistas que revisaram os vínculos em prontuários em alemão considerou cerca de três quartos deles correspondências completas. Finalmente, a equipe combinou os conceitos padronizados do SNOMED‑CT com informações estruturadas do EHR (como idade, valores laboratoriais e diagnósticos) e treinou um classificador de vetor de suporte para separar os pacientes em quatro grupos: sem insuficiência cardíaca e três subtipos principais de insuficiência cardíaca. A melhor versão alcançou uma pontuação F1 de 65,3%, essencialmente igualando uma forte linha de base neural baseada em um modelo BERT médico em alemão ajustado finamente.
O que o sistema acerta — e onde ele tem dificuldades
O classificador foi particularmente bom em reconhecer pacientes sem insuficiência cardíaca (cerca de 86% de acurácia) e aqueles com função de ejeção claramente reduzida. Teve desempenho inferior no grupo “intermediário” com função levemente reduzida, que também é difícil para médicos humanos e frequentemente se sobrepõe clinicamente a outras formas. A abordagem dos autores tem várias vantagens: pode funcionar mesmo quando dados de treinamento são escassos, é mais transparente do que modelos neurais caixa‑preta porque as previsões estão ligadas a conceitos médicos explícitos, e ajuda a tornar notas em alemão interoperáveis com padrões internacionais. Ao mesmo tempo, o estudo destaca desafios remanescentes, incluindo vínculos errôneos ocasionais entre conceitos semelhantes, a dificuldade de capturar nuances como a gravidade dos sintomas e a possibilidade de que resumos de alta já contenham indícios em estágio avançado que tornem a tarefa mais fácil do que a detecção verdadeiramente precoce.
O que isso significa para pacientes e médicos
Em termos práticos, este trabalho demonstra que computadores podem aprender a ler e organizar anotações clínicas complexas de modo suficiente para auxiliar no diagnóstico de insuficiência cardíaca em um nível comparável ao de redes neurais de ponta, permanecendo mais interpretáveis e mais fáceis de adaptar a novos hospitais e idiomas. Ao transformar texto não estruturado em blocos padronizados sobre um mapa médico compartilhado, o pipeline abre caminho para ferramentas de suporte à decisão que podem sinalizar pacientes em risco mais cedo, ajudar a evitar diagnósticos perdidos ou tardios e apoiar um cuidado mais personalizado — primeiro para insuficiência cardíaca e, em última instância, para muitas outras doenças.
Citação: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Palavras-chave: diagnóstico de insuficiência cardíaca, anotações clínicas, SNOMED CT, mineração de texto médico, suporte à decisão clínica