Clear Sky Science · sv
Heltäckande pipeline för automatisk hjärtsviktbedömning med kliniska anteckningar med SNOMED‑CT
Varför det spelar roll att läsa medicinska anteckningar bättre
Hjärtsvikt är vanligt, dödligt och ofta diagnostiserat för sent. Mycket av den tidiga varningsinformationen om en patient är dock begravd i läkares fritextanteckningar snarare än i prydliga kryssrutor eller laboratorietabeller. Denna studie visar hur artificiell intelligens kan omvandla de ostrukturerade anteckningarna—skrivna på tyska—och rutinmässiga sjukhusdata till en strukturerad bild av varje patient, och sedan använda den bilden för att hjälpa läkare avgöra vem som har hjärtsvikt och vem som inte har det.
Från spridda ord till organiserad information
Läkares anteckningar är informationsrika men kaotiska: de innehåller förkortningar, akronymer och olika sätt att uttrycka samma sak. Författarna byggde en end‑to‑end digital pipeline som börjar från dessa råanteckningar tillsammans med standarddata från elektroniska journaler (EHR) för 846 vårdpatienter med och utan hjärtsvikt. Först expanderar systemet automatiskt förkortningar utifrån den omgivande meningen, så att en kort kod som ”HT” tolkas korrekt som ”hypertoni” i stället för exempelvis ”huvudtrauma”. Detta görs på ett ”zero‑shot”-sätt genom att förlita sig på stora språkmodeller och exempelmeningar snarare än på handmärkta träningsdata för varje förkortning.
Att överbrygga språkbarriären och länka till en medicinsk karta
Eftersom många befintliga verktyg och referensterminologier är engelskspråkiga översätter nästa steg de tyska kliniska anteckningarna till engelska. Efter översättning söker pipelinen efter medicinskt meningsfulla fraser och länkar dem till begrepp i SNOMED‑CT, en stor, hierarkiskt organiserad ”karta” över sjukdomar, fynd och procedurer, samt till den bredare UMLS‑terminologin. I stället för att bara matcha exakta strängar använder systemet semantisk likhet: det bäddar in både anteckningsfragmenten och alla kandidatbegreppsbeskrivningar i ett numeriskt rum och hämtar de närmaste matcherna. En tvåstegsprocess—först generös insamling av kandidater, sedan striktare filtrering och användning av kontextexempel—balanserar hög täckning med precision och kan förfinas över tid med återkoppling från verkliga data och kliniker.
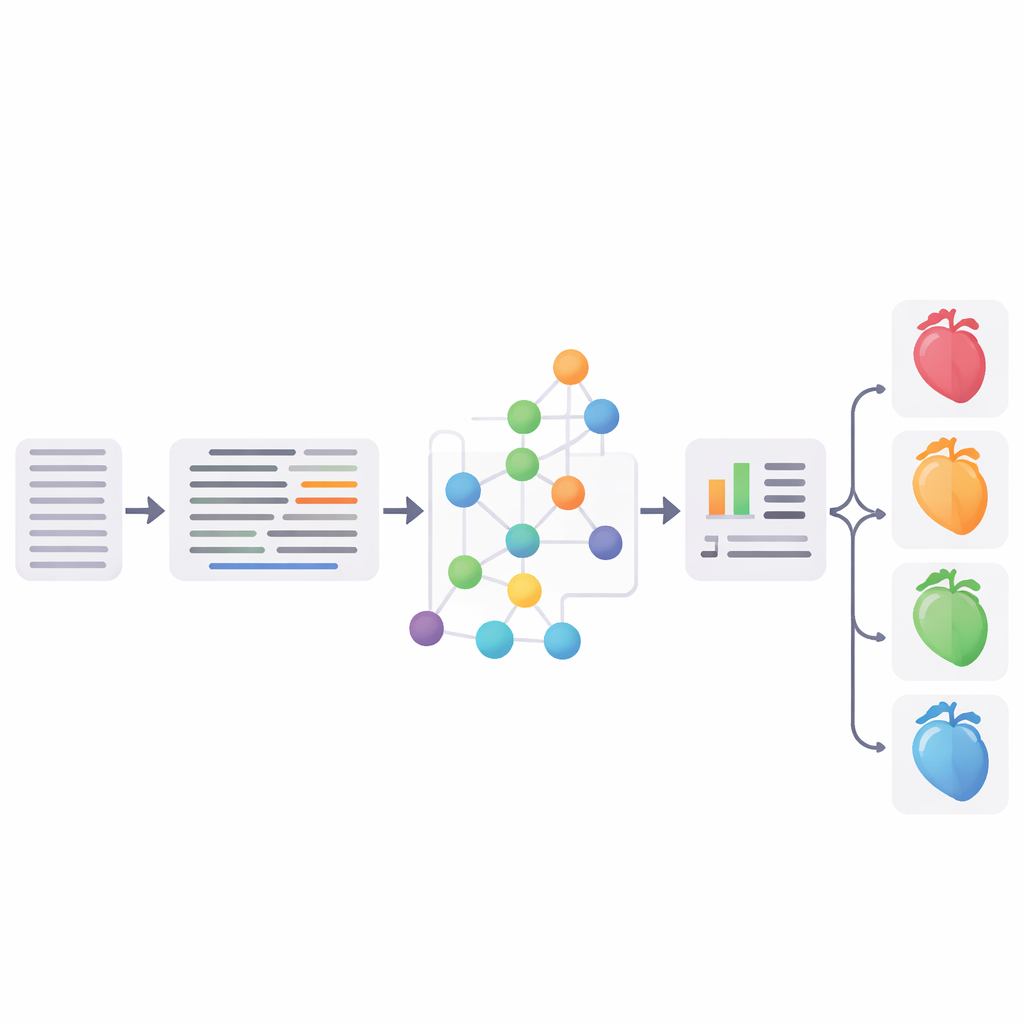
Sätta pipelinen på prov
Forskarna utvärderade varje huvudsteg noggrant. På allmänt använda engelska testuppsättningar nådde deras expansion av förkortningar upp till 96,1 % total noggrannhet, vilket konkurrerar med eller överträffar tidigare metoder. Deras entitetslänkningsmetod uppnådde konkurrenskraftiga poäng jämfört med den etablerade MedCAT‑verktygslådan, och en granskning av tre kardiologer som bedömde länkar på tyska journaler ansåg att ungefär tre fjärdedelar var fullständiga träffar. Slutligen kombinerade teamet de standardiserade SNOMED‑CT‑begreppen med strukturerad EHR‑information (såsom ålder, laboratorievärden och diagnoser) och tränade en supportvektormaskin‑klassificerare för att sortera patienter i fyra grupper: ingen hjärtsvikt och tre huvudsubtyper av hjärtsvikt. Den bästa versionen nådde ett F1‑mått på 65,3 %, vilket i praktiken matchade en stark neuralt baserad referensmodell baserad på en finkalibrerad tysk medicinsk BERT‑modell.
Vad systemet gör rätt—och var det har svårigheter
Klassificeraren var särskilt bra på att känna igen patienter utan hjärtsvikt (ungefär 86 % noggrannhet) och de med tydligt nedsatt pumpfunktion. Den presterade sämre på gruppen i ”mellanskiktet” med måttligt nedsatt funktion, vilket också är svårt för mänskliga läkare och ofta kliniskt överlappar med andra former. Författarnas angreppssätt har flera fördelar: det kan fungera även när träningsdata är knappa, det är mer transparent än svarta lådan‑neuronala textmodeller eftersom prediktionerna knyts till explicita medicinska begrepp, och det hjälper till att göra tyska anteckningar interoperabla med internationella standarder. Samtidigt belyser studien kvarstående utmaningar, inklusive sporadiska felaktiga länkar mellan liknande begrepp, svårigheten att fånga nyanser som symtomintensitet och möjligheten att epikriser redan innehåller sena ledtrådar som gör uppgiften lättare än verkligt tidig upptäckt.
Vad detta betyder för patienter och läkare
Enkelt uttryckt visar detta arbete att datorer kan lära sig läsa och organisera komplexa kliniska anteckningar tillräckligt väl för att assistera vid diagnostik av hjärtsvikt på en nivå jämförbar med toppmoderna neurala nätverk, samtidigt som de förblir mer tolkbara och lättare att anpassa till nya sjukhus och språk. Genom att omvandla ostrukturerad text till standardiserade byggstenar på en gemensam medicinsk karta banar pipelinen väg för beslutsstödsverktyg som kan flagga riskpatienter tidigare, hjälpa till att undvika missade eller fördröjda diagnoser och stödja mer individualiserad vård—först för hjärtsvikt, och slutligen för många andra sjukdomar.
Citering: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Nyckelord: hjärtsviktdiagnos, kliniska anteckningar, SNOMED CT, textutvinning inom medicin, kliniskt beslutsstöd