Clear Sky Science · pl
Kompletny pipeline do automatycznej diagnozy niewydolności serca na podstawie notatek klinicznych z użyciem SNOMED‑CT
Dlaczego inteligentniejsze czytanie notatek medycznych ma znaczenie
Niewydolność serca jest powszechna, śmiertelna i często rozpoznawana zbyt późno. Tymczasem wiele wczesnych objawów pacjenta bywa ukrytych w wolnotekstowych notatkach lekarzy, a nie w uporządkowanych polach czy tabelach laboratoryjnych. Badanie to pokazuje, jak sztuczna inteligencja może przekształcić te nieuporządkowane notatki — napisane po niemiecku — oraz rutynowe dane szpitalne w ustrukturyzowany obraz każdego pacjenta, a następnie wykorzystać go, aby pomóc lekarzom zdecydować, kto ma, a kto nie ma niewydolności serca.
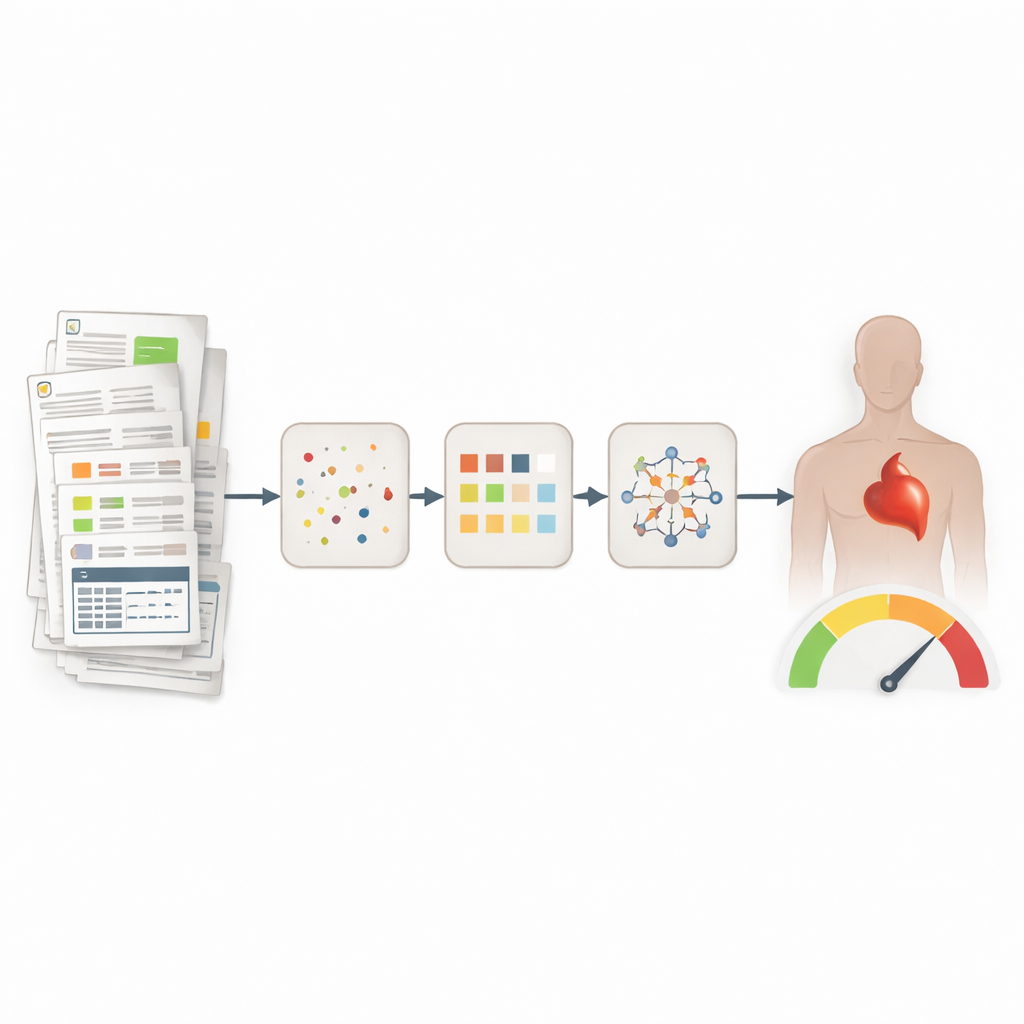
Z rozrzuconych słów do uporządkowanej informacji
Notatki lekarzy są bogate, lecz chaotyczne: zawierają skróty, akronimy i różne sposoby wyrażania tej samej informacji. Autorzy zbudowali kompletny cyfrowy pipeline, który zaczyna się od surowych notatek oraz standardowych danych z elektronicznej dokumentacji medycznej (EHR) dla 846 pacjentów szpitalnych z niewydolnością serca i bez niej. Najpierw system automatycznie rozwija skróty na podstawie kontekstu zdania, tak że krótki kod jak „HT” jest interpretowany poprawnie jako „nadciśnienie” a nie, na przykład, „uraz głowy”. Robi to w trybie „zero‑shot”, opierając się na dużych modelach językowych i przykładowych zdaniach, zamiast na ręcznie oznaczonych danych treningowych dla każdego skrótu.
Pokonywanie bariery językowej i łączenie z medyczną mapą
Ponieważ wiele dostępnych narzędzi i terminologii odniesienia jest opartych na języku angielskim, kolejny krok polega na przetłumaczeniu niemieckich notatek klinicznych na angielski. Po tłumaczeniu pipeline wyszukuje medycznie istotne frazy i łączy je z pojęciami w SNOMED‑CT — dużej, hierarchicznie zorganizowanej „mapie” chorób, objawów i procedur — oraz z szeroką terminologią UMLS. Zamiast prostego dopasowania łańcuchów znaków, system używa podobieństwa semantycznego: reprezentuje fragmenty notatek i opisy kandydatów na pojęcia w przestrzeni numerycznej i pobiera najbliższe dopasowania. Dwustopniowy proces — najpierw hojne gromadzenie kandydatów, potem surowsze filtrowanie i użycie przykładów kontekstowych — godzi dużą czułość z precyzją i może być udoskonalany z czasem dzięki informacjom zwrotnym z rzeczywistych danych i od klinicystów.
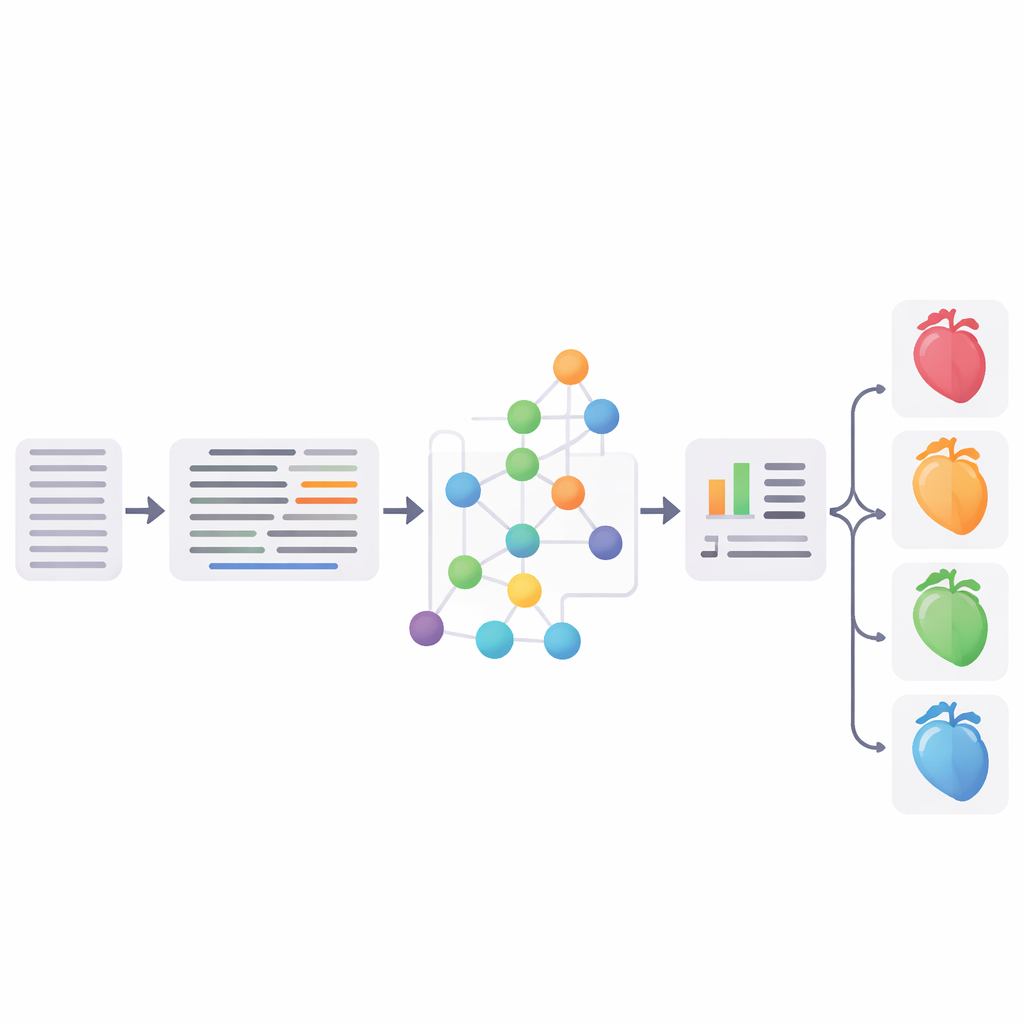
Testowanie pipeline’u
Naukowcy rygorystycznie ocenili każdy kluczowy etap. Na powszechnie używanych zestawach testowych w języku angielskim ich rozwijanie skrótów osiągnęło do 96,1% dokładności ogólnej, dorównując lub przewyższając wcześniejsze metody. Podejście do wiązania encji z pojęciami uzyskało konkurencyjne wyniki w porównaniu z ustalonym narzędziem MedCAT, a ankieta trzech kardiologów, którzy oceniali powiązania w niemieckich zapisach, uznała około trzy czwarte z nich za kompletne dopasowania. Wreszcie zespół połączył znormalizowane pojęcia SNOMED‑CT ze strukturalnymi danymi EHR (takimi jak wiek, wartości laboratoriów i rozpoznania) i wytrenował klasyfikator typu support vector machine do podziału pacjentów na cztery grupy: brak niewydolności serca oraz trzy główne podtypy niewydolności. Najlepsza wersja osiągnęła miarę F1 na poziomie 65,3%, co w zasadzie równoważyło silną sieciową bazę opartą na dostrojonym niemieckim medycznym modelu BERT.
Co system robi dobrze — i gdzie ma problemy
Klasyfikator szczególnie dobrze rozpoznawał pacjentów bez niewydolności serca (około 86% dokładności) oraz tych z wyraźnie obniżoną funkcją wyrzutową. Słabiej radził sobie z grupą „pośrednią” o łagodnie zmniejszonej funkcji, która także stanowi wyzwanie dla lekarzy i często klinicznie nakłada się na inne formy. Podejście autorów ma kilka zalet: działa nawet przy ograniczonych danych treningowych, jest bardziej przejrzyste niż „czarne skrzynki” sieci neuronowych, ponieważ przewidywania wiążą się z konkretnymi pojęciami medycznymi, i ułatwia interoperacyjność niemieckich notatek ze światowymi standardami. Jednocześnie praca uwypukla pozostające wyzwania, w tym sporadyczne błędne powiązania między podobnymi pojęciami, trudność uchwycenia niuansów takich jak nasilenie objawów oraz możliwość, że streszczenia wypisu mogą już zawierać późne wskazówki, które upraszczają zadanie w porównaniu z rzeczywistym wczesnym wykrywaniem.
Co to oznacza dla pacjentów i lekarzy
Mówiąc prosto, praca ta pokazuje, że komputery potrafią nauczyć się czytać i porządkować złożone notatki kliniczne na tyle dobrze, by wspierać diagnozowanie niewydolności serca na poziomie porównywalnym z najnowocześniejszymi sieciami neuronowymi, pozostając przy tym bardziej interpretowalnymi i łatwiejszymi do adaptacji w nowych szpitalach i językach. Przekształcając nieustrukturyzowany tekst w znormalizowane elementy na wspólnej medycznej mapie, pipeline toruje drogę narzędziom wspomagania decyzji, które mogą wcześniej wskazywać pacjentów zagrożonych, pomagać unikać przeoczonych lub opóźnionych rozpoznań oraz wspierać bardziej spersonalizowaną opiekę — najpierw w niewydolności serca, a ostatecznie w wielu innych chorobach.
Cytowanie: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Słowa kluczowe: diagnozowanie niewydolności serca, notatki kliniczne, SNOMED CT, eksploracja tekstu medycznego, wspomaganie decyzji klinicznych