Clear Sky Science · nl
End-to-end pipeline voor geautomatiseerde hartfalen-diagnose met klinische aantekeningen met behulp van SNOMED-CT
Waarom slimmer lezen van medische aantekeningen ertoe doet
Hartfalen komt veel voor, is dodelijk en wordt vaak te laat gediagnosticeerd. Veel vroegtijdige waarschuwingssignalen over een patiënt bevinden zich echter in de vrije-tekstaantekeningen van artsen in plaats van in nette selectievakjes of laboratoriumtabellen. Deze studie laat zien hoe kunstmatige intelligentie die rommelige aantekeningen—geschreven in het Duits—en routinematige ziekenhuisgegevens kan omzetten in een gestructureerd beeld van elke patiënt, en dat beeld vervolgens kan gebruiken om artsen te helpen beslissen wie wel en geen hartfalen heeft.
Van verspreide woorden naar georganiseerde informatie
Aantekeningen van artsen zijn rijk maar chaotisch: ze bevatten verkorte notaties, afkortingen en verschillende manieren om hetzelfde uit te drukken. De auteurs bouwden een end-to-end digitale pijplijn die begint bij deze ruwe aantekeningen plus standaard elektronische patiëntendossiergegevens (EHR) voor 846 ziekenhuispatiënten met en zonder hartfalen. Eerst breidt het systeem automatisch afkortingen uit op basis van de omringende zin, zodat een korte code als “HT” correct wordt geïnterpreteerd als “hypertensie” in plaats van bijvoorbeeld “head trauma”. Dit gebeurt op een "zero-shot" manier, waarbij grote taalmodellen en voorbeeldzinnen worden gebruikt in plaats van handmatig gelabelde trainingsdata voor elke afkorting.
De taalbarrière oversteken en koppelen aan een medisch kaart
Aangezien veel bestaande tools en referentieterminologieën Engels-gebaseerd zijn, vertaalt de volgende stap Duitse klinische aantekeningen naar het Engels. Na vertaling doorzoekt de pijplijn medisch betekenisvolle zinsdelen en koppelt deze aan concepten in SNOMED‑CT, een grote hiërarchisch georganiseerde “kaart” van ziekten, bevindingen en procedures, evenals aan de brede UMLS-terminologie. In plaats van alleen exacte string-matches gebruikt het systeem semantische gelijkenis: het embedt zowel de fragmenten uit de aantekeningen als alle kandidaat-conceptbeschrijvingen in een getalsruimte en haalt de dichtstbijzijnde matches op. Een tweefasig proces—eerst ruime verzameling van kandidaten, daarna striktere filtering en gebruik van contextvoorbeelden—vindt een balans tussen hoge dekking en precisie, en kan in de loop van de tijd verfijnd worden met feedback uit echte data en van clinici.
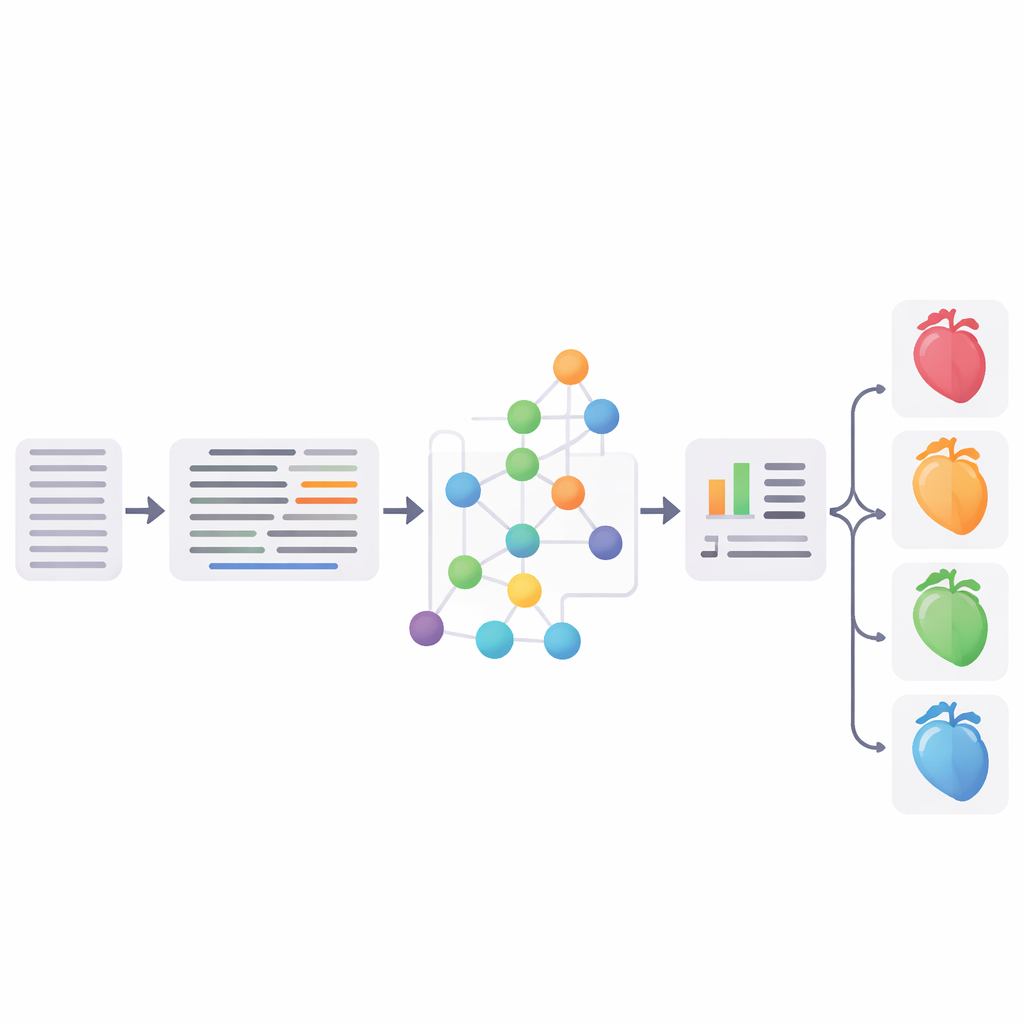
De pijplijn op de proef stellen
De onderzoekers evalueerden elke belangrijke stap grondig. Op veelgebruikte Engelse testsets bereikte hun uitbreiding van afkortingen tot 96,1% totale nauwkeurigheid, waarmee ze eerdere methoden evenaarden of overtroffen. Hun entity-linking aanpak behaalde concurrerende scores in vergelijking met de gevestigde MedCAT-toolkit, en een beoordeling door drie cardiologen die koppelingen op Duitse dossiers bekeken, oordeelde dat ongeveer driekwart van de koppelingen volledige overeenkomsten waren. Ten slotte combineerde het team de gestandaardiseerde SNOMED‑CT-concepten met gestructureerde EHR-informatie (zoals leeftijd, laboratoriumwaarden en diagnoses) en trainde een support vector machine-classifier om patiënten in vier groepen in te delen: geen hartfalen en drie hoofdsubtypen van hartfalen. De beste versie behaalde een F1-score van 65,3%, wat in wezen overeenkomt met een sterke neurale referentie gebaseerd op een fijn afgesteld Duits medisch BERT-model.
Wat het systeem goed doet — en waar het moeite mee heeft
De classifier was bijzonder goed in het herkennen van patiënten zonder hartfalen (ongeveer 86% nauwkeurigheid) en van patiënten met duidelijk verminderde pompfunctie. Hij presteerde minder goed op de “midden”-groep met licht verminderde functie, die ook voor menselijke artsen moeilijk is en vaak klinisch overlapt met andere vormen. De aanpak van de auteurs heeft verschillende voordelen: het kan werken zelfs wanneer trainingsdata schaars zijn, het is transparanter dan black-box neurale tekstmodellen omdat voorspellingen gekoppeld zijn aan expliciete medische concepten, en het helpt Duitse aantekeningen interoperabel te maken met internationale standaarden. Tegelijkertijd benadrukt de studie resterende uitdagingen, waaronder incidentele foutieve koppelingen tussen vergelijkbare concepten, de moeilijkheid om nuances zoals ernst van symptomen vast te leggen, en de mogelijkheid dat ontslagbrieven al laatstadium-signalen bevatten die de taak makkelijker maken dan echte vroegdetectie.
Wat dit betekent voor patiënten en artsen
In gewone taal toont dit werk aan dat computers kunnen leren complexe klinische aantekeningen zodanig te lezen en te organiseren dat ze kunnen helpen bij de diagnose van hartfalen op een niveau vergelijkbaar met state-of-the-art neurale netwerken, terwijl ze tegelijk beter interpreteerbaar en gemakkelijker aanpasbaar aan nieuwe ziekenhuizen en talen blijven. Door ongestructureerde tekst om te zetten in gestandaardiseerde bouwstenen op een gedeelde medische kaart, effent de pijplijn de weg voor besluitondersteunende tools die risicopatiënten eerder kunnen signaleren, helpen gemiste of vertraagde diagnoses te voorkomen en meer gepersonaliseerde zorg te ondersteunen—eerst voor hartfalen en uiteindelijk voor vele andere ziekten.
Bronvermelding: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Trefwoorden: hartfalen-diagnose, klinische aantekeningen, SNOMED CT, medische tekstanalyse, klinische besluitvorming