Clear Sky Science · ru
Конечная конвейерная система для автоматизированной диагностики сердечной недостаточности по клиническим записям с использованием SNOMED‑CT
Почему важно умнее читать медицинские записи
Сердечная недостаточность распространена, смертельно опасна и часто диагностируется слишком поздно. При этом большая часть ранних предупреждающих признаков у пациента скрыта в свободнотекстовых записях врачей, а не в аккуратных флажках или таблицах с лабораторными данными. В этом исследовании показано, как искусственный интеллект может превратить эти неструктурированные заметки — написанные на немецком языке — и рутинные данные больницы в структурированное представление для каждого пациента, а затем использовать это представление, чтобы помочь врачам определить, есть ли у пациента сердечная недостаточность.
От разбросанных слов к упорядоченной информации
Записи врачей богаты по содержанию, но хаотичны: в них встречаются сокращения, аббревиатуры и разные варианты выражения одного и того же. Авторы построили сквозной цифровой конвейер, который начинается с этих исходных заметок в сочетании со стандартными данными из электронной медицинской карты (EHR) для 846 пациентов больницы с сердечной недостаточностью и без неё. Сначала система автоматически разворачивает аббревиатуры, учитывая окружающее предложение, так что короткий код типа «HT» интерпретируется правильно как «гипертония», а не, скажем, как «черепно‑мозговая травма». Она делает это в «ноль‑шотном» режиме, опираясь на большие языковые модели и примерные предложения, а не на вручную размеченные тренировочные данные для каждой аббревиатуры.
Преодоление языкового барьера и привязка к медицинской карте
Поскольку многие существующие инструменты и справочные терминологии ориентированы на английский, следующий шаг — перевод немецких клинических записей на английский. После перевода конвейер ищет медицински значимые фразы и связывает их с понятиями в SNOMED‑CT — большой иерархически организованной «карте» заболеваний, находок и процедур — а также с широкой терминологией UMLS. Вместо простого точного совпадения строк система использует семантическое сходство: фрагменты заметок и все описания кандидатных концепций отображаются в числовое пространство, и выбираются ближайшие соответствия. Двухэтапный процесс — сначала щедрый сбор кандидатов, затем более строгая фильтрация с использованием контекстных примеров — сочетает высокое покрытие и точность, и его можно уточнять со временем на основе обратной связи от реальных данных и клиницистов.
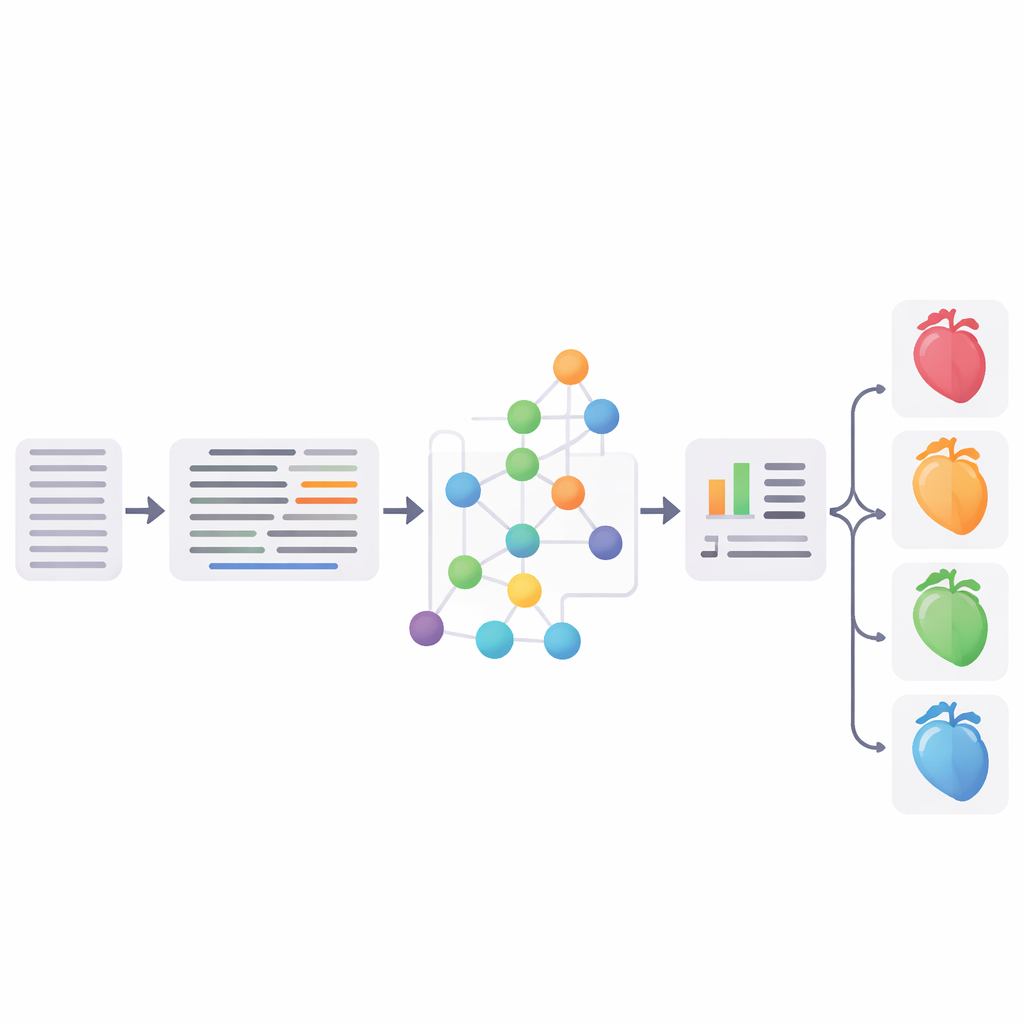
Испытание конвейера
Исследователи тщательно оценили каждый ключевой этап. На широко используемых английских тестовых наборах разворачивание аббревиатур достигало до 96,1% общей точности, соперничая или превосходя предыдущие методы. Их подход к связыванию сущностей показал конкурентоспособные результаты по сравнению с признанным инструментарием MedCAT, а обзор трёх кардиологов, проверивших связи в немецких записях, признал около трёх четвертей из них полными совпадениями. Наконец, команда объединила стандартизованные концепции SNOMED‑CT со структурированной информацией из EHR (например, возраст, лабораторные значения и диагнозы) и обучила классификатор на основе опорных векторов (SVM) разделять пациентов на четыре группы: без сердечной недостаточности и три основные подтипа сердечной недостаточности. Лучшая версия достигла F1‑метрики 65,3%, фактически сравнимой с сильной нейросетевой базой на основе донастроенной немецкой медицинской модели BERT.
Что система делает хорошо — и где испытывает сложности
Классификатор особенно хорошо распознавал пациентов без сердечной недостаточности (примерно 86% точности) и тех, у кого явно снижена насосная функция сердца. Хуже он справлялся с «пограничной» группой с умеренным снижением функции, что сложно и для врачей и часто клинически пересекается с другими формами. Подход авторов имеет несколько преимуществ: он может работать даже при дефиците обучающих данных, он более прозрачен по сравнению с «чёрными ящиками» нейронных текстовых моделей, поскольку прогнозы связаны с явными медицинскими концепциями, и он помогает сделать немецкие записи интероперабельными с международными стандартами. В то же время исследование подчёркивает оставшиеся проблемы, включая случайные неправильные привязки между похожими концепциями, трудности захвата тонкостей вроде степени выраженности симптомов и возможность того, что выписные эпикризы уже содержат поздние подсказки, делающие задачу проще, чем истинно раннее выявление.
Что это означает для пациентов и врачей
Проще говоря, эта работа показывает, что компьютеры могут научиться так читать и структурировать сложные клинические записи, чтобы помогать в диагностике сердечной недостаточности на уровне, сопоставимом с передовыми нейросетевыми моделями, оставаясь при этом более интерпретируемыми и легче адаптируемыми к новым больницам и языкам. Превращая неструктурированный текст в стандартизованные строительные блоки общей медицинской карты, конвейер прокладывает путь для инструментов поддержки принятия решений, которые могут раньше выявлять пациентов с риском, помогать избегать пропусков или задержек в диагнозе и поддерживать более персонализированную помощь — сначала при сердечной недостаточности, а в перспективе и при многих других заболеваниях.
Цитирование: Tang, FS.KB., Verket, M., Müller-Wieland, D. et al. End-to-end pipeline for automated heart failure diagnosis with clinical notes using SNOMED-CT. Sci Rep 16, 12751 (2026). https://doi.org/10.1038/s41598-026-48771-1
Ключевые слова: диагностика сердечной недостаточности, клинические записи, SNOMED CT, майнинг медицинского текста, система поддержки клинических решений