Clear Sky Science · zh
用于星系形态分类的无监督多模态深度学习:结合 ConvNeXt 嵌入与形态学参数以实现可扩展的巡天科学
教计算机“读懂”星系的形状
现代巡天正在拍摄数十亿颗星系的图像,远超任何天文学家团队或业余公民科学家用肉眼逐一分类的能力。然而,星系的形状——从光滑的椭球到壮丽的螺旋以及混乱的合并体——包含着关于宇宙如何构建结构的重要线索。本文提出了一种新的方法,使计算机能够自动对星系进行排序而无需事先告知要寻找的特征,从而为在真正巨大的尺度上探索宇宙结构打开了大门。
为什么星系形状很重要
星系不仅仅是漂亮的图像;它们的外观记录着自身的演化历程。光滑、圆润的系统往往更古老、更平静,而具有明显螺旋臂或扭曲形态的星系常常表明正在进行恒星形成或近期发生过碰撞。一个世纪以来,天文学家将这些形态组织成若干家族——例如椭圆星系、螺旋星系和不规则星系——以将可见结构与背后的物理联系起来。但随着诸如斯隆数字巡天(SDSS)以及即将到来的鲁宾天文台的遗产巡天(LSST)等项目以前所未有的深度成像天空,传统的人工标注已无法维持。
从人工标签到无监督发现
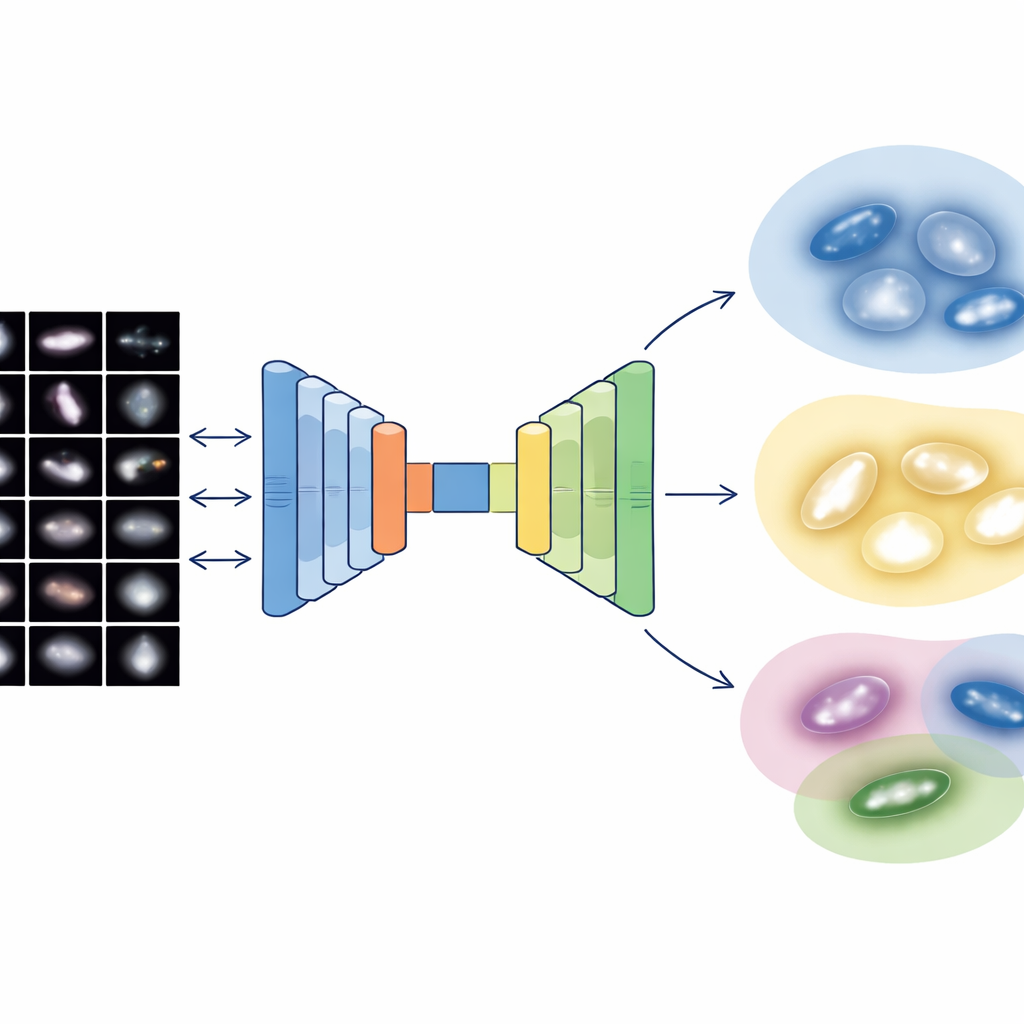
最近的大多数自动星系分类进展依赖于监督深度学习:计算机从人类已经标注的数千个样本中学习。这种方法有效,但依赖耗时制作的训练集,并且仅限于人们事先定义的类别。作者们转而采用无监督路径,要求算法自行在数据中发现自然群组。为此,他们使用了最初在日常照片上训练的强大图像分析网络,然后将其调整用于星系图像,以提取丰富的视觉指纹,且不需要任何星系携带预先分配的标签。
将图像与物理测量结合
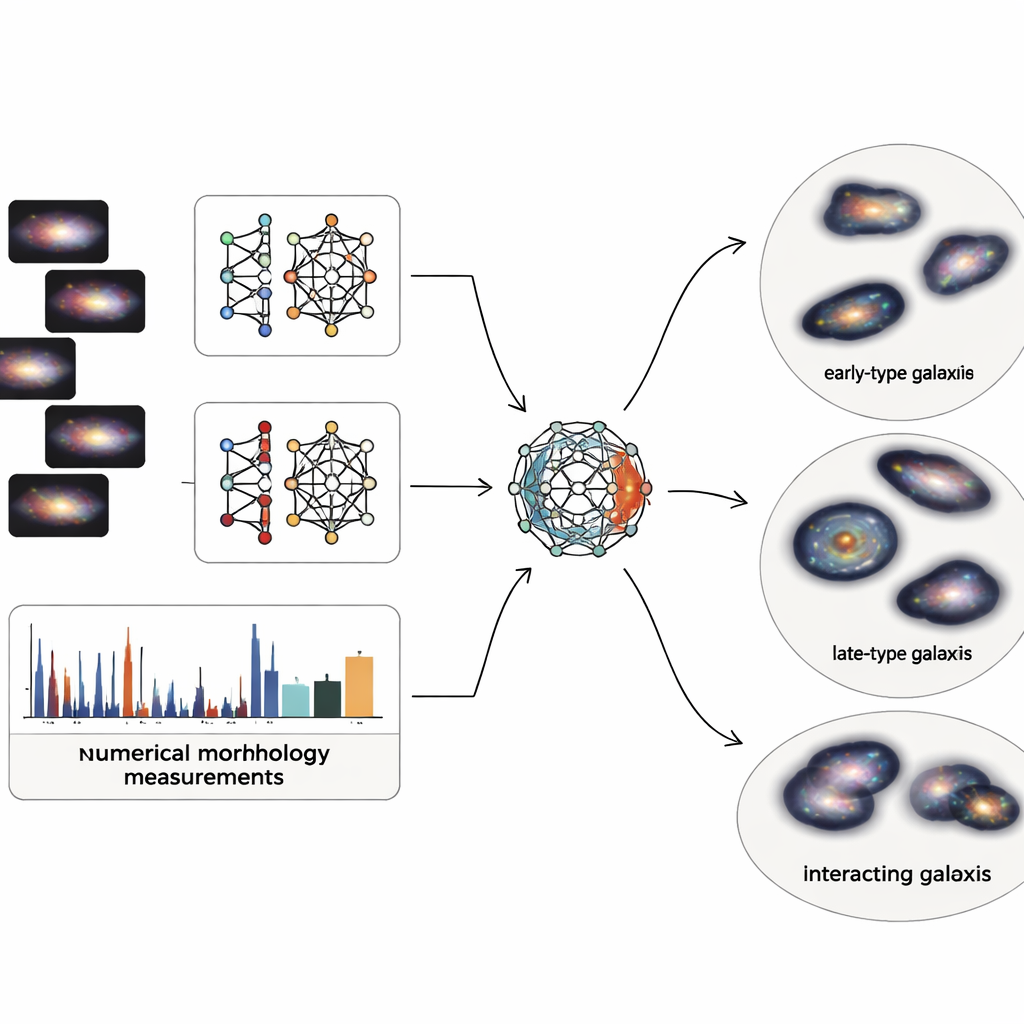
星系图像包含大量细节,但天文学家也使用一些简单的结构数值描述,例如光度的集中程度、星系的偏心程度、恒星形成区域的团簇性,以及光在像素间的分布不均等。研究团队将两者结合:来自两个现代神经网络的深度视觉特征与五个经典的结构测量。由于基于图像的描述可能包含数千个数值而物理测量只有少数几个,他们构建了一种特殊的“多模态自编码器”——一种将所有信息压缩成紧凑内部编码的神经网络。这个由64个数字组成的编码迫使系统在从图像学到的信息与来自基本星系物理学的已知量之间取得平衡。
让数据自然形成簇群
一旦将每个经过精心清理的4,950个斯隆巡天星系都压缩为这个平衡的64维编码,作者就应用了一种概率聚类技术,将星系总体视为若干重叠群组的平滑混合。它不强制划定尖锐边界,而是为每个星系分配在若干簇中的隶属程度,并仅将最极端的约2%标记为真正的异常或伪像。所得主要簇群与熟悉的家族吻合良好:类似早型星系的光滑致密系统;类似晚型螺旋的弥散、多团簇盘面;相互作用和扰动系统;以及中间的过渡盘面。内部测试表明,这种图像与物理量结合的表征比仅使用图像或结构数值单独产生更干净、更一致的群组。
与经典规则比较并实现扩展
为了检验计算机的无监督分组是否具有物理意义,作者将其与基于简单结构图的长期经验性边界进行比较。尽管算法从未见过任何人工标签,大约一半的分类结果与这些传统类别一致,其余则揭示了旧有两参数规则所模糊掉的更细微差异。同样重要的是,整个流程运行迅速:在现代硬件上每个星系仅需几十毫秒即可处理完毕,这一速度适用于即将对数十亿星系建档的拍摄到数拍字节级别的巡天数据。
一张新的星系动物园地图
用通俗的话说,这项工作展示了如何教会计算机“看见”并将星系分组,既尊重天文学家已有的知识,也尊重数据可能隐藏的新信息。通过将视觉模式与简单的物理测量相融合,并允许逐步过渡而非僵硬的分类框,该方法构建了一套灵活且可扩展的星系分类法。这一方法应能帮助科学家筛理即将到来的海量天空图像,发现罕见或异常系统,并细化我们关于星系如何形成、相互作用及随宇宙时间演化的认识。
引用: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
关键词: 星系形态, 无监督学习, 深度学习, 天文巡天, 聚类