Clear Sky Science · pl
Nienadzorowane multimodalne uczenie głębokie dla taksonomii morfologii galaktyk: integracja osadzeń ConvNeXt i parametrów morfologicznych dla skalowalnej nauki przeglądów
Nauczanie komputerów rozpoznawania kształtów galaktyk
Współczesne przeglądy nieba fotografują miliardy galaktyk — znacznie więcej, niż jakikolwiek zespół astronomów lub ochotniczych naukowców obywatelskich mógłby sklasyfikować wzrokowo. A jednak kształty galaktyk, od gładkich elips po rozległe spirale i chaotyczne zderzenia, zawierają kluczowe wskazówki dotyczące tego, jak Wszechświat buduje swoje struktury. W artykule przedstawiono nowy sposób, w jaki komputery mogą automatycznie segregować galaktyki, bez uprzedniego wskazywania, czego mają szukać, otwierając drogę do badania kosmicznej struktury na naprawdę masową skalę.
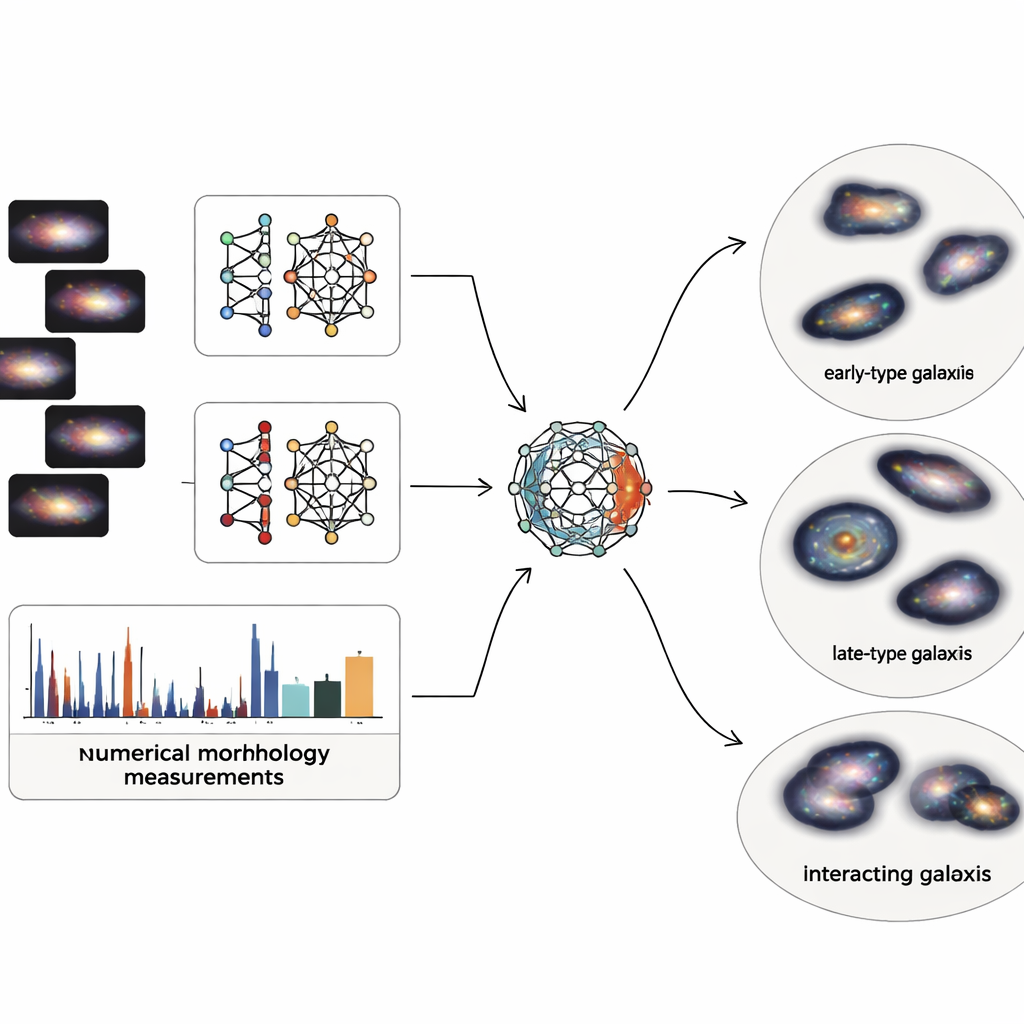
Dlaczego kształty galaktyk mają znaczenie
Galaktyki to nie tylko efektowne obrazy; ich wygląd koduje ich życiorysy. Gładkie, okrągłe układy zwykle są starsze i spokojniejsze, podczas gdy galaktyki z wyraźnymi ramionami spiralnymi lub zdeformowanymi kształtami często sygnalizują trwające narodziny gwiazd lub niedawne kolizje. Od stulecia astronomowie porządkują te formy w rodziny — takie jak eliptyczne, spiralne i nieregularne — by łączyć widoczną strukturę z leżącą u jej podstaw fizyką. Jednak w miarę jak projekty takie jak Sloan Digital Sky Survey i nadchodzące obserwatoria, np. Legacy Survey of Space and Time Rubin Observatory, obrazują niebo z niespotykaną dotąd głębią, tradycyjne ręczne etykietowanie staje się niemożliwe do utrzymania.
Od etykiet ludzkich do nienadzorowanego odkrywania
Większość niedawnych postępów w automatycznej klasyfikacji galaktyk opiera się na nadzorowanym uczeniu głębokim: komputery uczą się na podstawie tysięcy przykładów już oznaczonych przez ludzi. To działa dobrze, ale zależy od mozolnie przygotowywanych zestawów uczących i ogranicza się do kategorii zdefiniowanych wcześniej przez ludzi. Autorzy idą inną drogą — nienadzorowaną — prosząc algorytm, by samodzielnie odkrył naturalne grupowania w danych. W tym celu wykorzystują potężne sieci do analizy obrazów pierwotnie trenowane na codziennych fotografiach, a następnie adaptują je do obrazów galaktyk, by wydobyć bogate wizualne odciski palców — wszystko bez potrzeby przypisywania galaktykom wstępnych etykiet.
Łączenie obrazów z pomiarami fizycznymi
Obrazy galaktyk zawierają ogrom detali, ale astronomie używają też prostych numerycznych opisów struktury, takich jak stopień koncentracji światła, asymetria galaktyki, grudkowatość regionów formowania gwiazd czy nierównomierność rozkładu światła po pikselach. Zespół łączy oba światy: głębokie cechy wizualne z dwóch nowoczesnych sieci neuronowych oraz pięć klasycznych miar strukturalnych. Ponieważ opis oparty na obrazach liczy tysiące liczb, podczas gdy miary fizyczne to tylko kilka wartości, zbudowali specjalny „multimodalny autoenkoder” — typ sieci neuronowej, która kompresuje całą informację do zwartego wewnętrznego kodu. Ten 64‑elementowy kod wymusza na systemie zrównoważenie tego, czego się uczy z obrazów, z wiedzą płynącą z podstawowej fizyki galaktyk.
Pozwolenie danym na podział na naturalne rodziny
Gdy każda z 4 950 starannie oczyszczonych galaktyk ze Sloan zostaje zredukowana do tego zrównoważonego, 64‑wymiarowego kodu, autorzy stosują probabilistyczną technikę klastrowania traktującą populację galaktyk jako gładką mieszaninę nakładających się grup. Zamiast narzucać ostre granice, metoda przypisuje każdej galaktyce stopień przynależności do kilku klastrów i wyznacza jedynie najbardziej ekstremalne 2% jako prawdziwe osobliwości lub artefakty. Powstałe główne klastry dobrze odpowiadają znanym rodzinom: gładkie, zwarte układy przypominające galaktyki typu wczesnego; rozproszone, grudkowate dyski podobne do spiralnych typu późnego; systemy w interakcji i zaburzone; oraz pośrednie, przejściowe dyski. Testy wewnętrzne pokazują, że ta połączona reprezentacja — obraz + fizyka — daje czyściejsze, bardziej spójne grupy niż użycie samych obrazów lub samych miar strukturalnych.
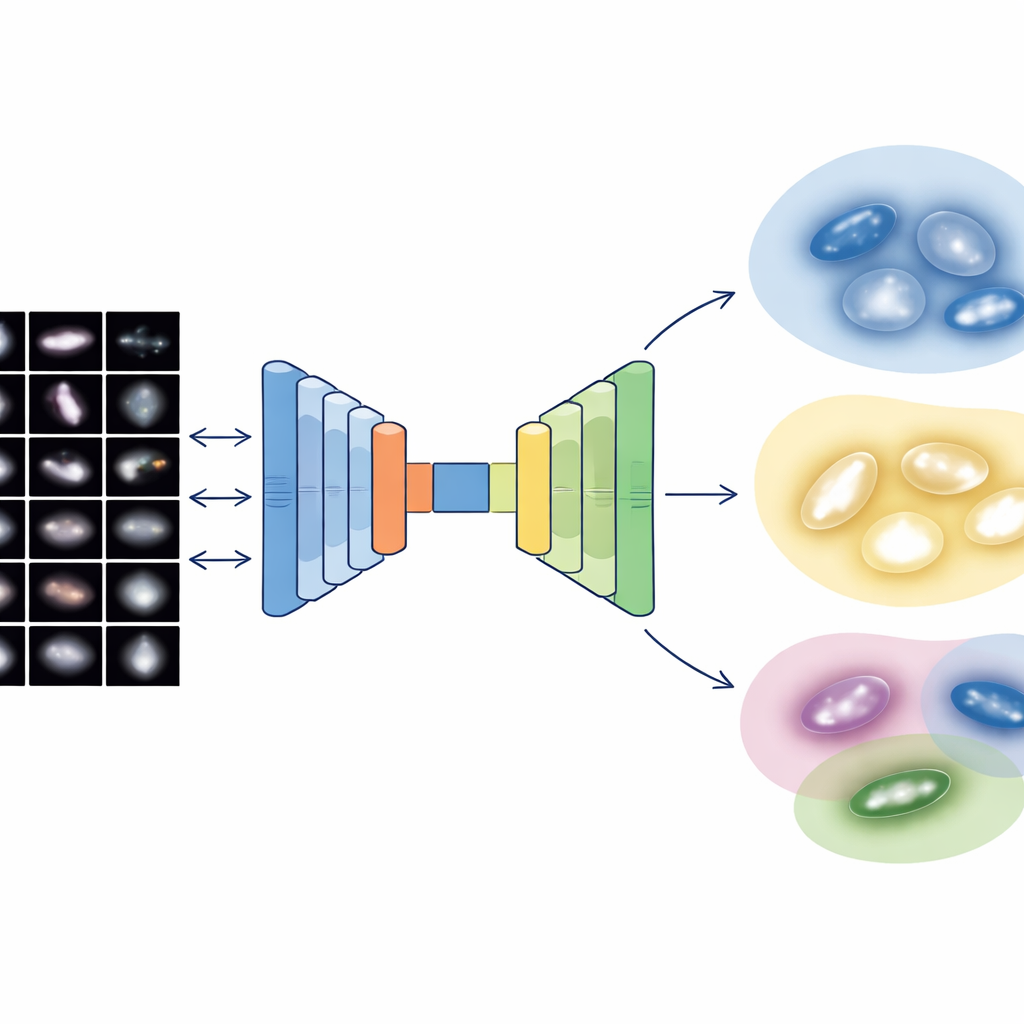
Weryfikacja względem klasycznych reguł i skalowanie
Aby sprawdzić, czy nienadzorowane grupowania komputerowe mają sens fizyczny, autorzy porównują je z długo stosowanymi granicami opartymi na prostych diagramach struktury. Chociaż algorytm nigdy nie widział etykiet stworzonych przez ludzi, około połowa jego klasyfikacji pokrywa się z tymi tradycyjnymi kategoriami, a pozostałe ujawniają subtelniejsze wariacje, które starsze reguły dwuparametrowe zacierają. Co równie istotne, cały proces działa szybko: przetworzenie jednej galaktyki zajmuje zaledwie kilkadziesiąt milisekund na nowoczesnym sprzęcie, tempo odpowiednie dla przeglądów o skali petabajtów, które wkrótce skatalogują miliardy galaktyk.
Nowa mapa Galaxy Zoo
Mówiąc wprost, praca ta pokazuje, jak nauczyć komputer „widzieć” i grupować galaktyki w sposób uwzględniający zarówno to, co astronomowie już wiedzą, jak i to, co dane nadal mogą ukrywać. Poprzez łączenie wzorców wizualnych z prostymi pomiarami fizycznymi oraz dopuszczanie stopniowych przejść zamiast sztywnych pudełek, metoda tworzy elastyczną, skalowalną taksonomię galaktyk. Podejście to powinno pomóc naukowcom przesiać nadchodzący napływ obrazów nieba, wykryć rzadkie lub nietypowe systemy i udoskonalić nasze rozumienie tego, jak galaktyki powstają, wchodzą w interakcje i przekształcają się w czasie kosmicznym.
Cytowanie: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Słowa kluczowe: morfologia galaktyk, uczenie nienadzorowane, uczenie głębokie, przeglądy astronomiczne, grupowanie