Clear Sky Science · pt
Aprendizado profundo multimodal não supervisionado para taxonomia da morfologia galáctica: integrando ConvNeXtEmbeddings e parâmetros morfológicos para ciência de levantamentos em escala
Ensinando Computadores a Ler as Formas das Galáxias
Levantes modernos do céu estão fotografando bilhões de galáxias, muito mais do que qualquer equipe de astrônomos — ou cientistas cidadãos — poderia classificar visualmente. Ainda assim, as formas das galáxias, de elipses suaves a espirais grandiosas e fusões caóticas, contêm pistas vitais sobre como o universo constrói suas estruturas. Este artigo apresenta uma nova maneira de os computadores organizarem galáxias automaticamente, sem receber instruções prévias sobre o que procurar, abrindo caminho para explorar a estrutura cósmica em escala verdadeiramente massiva.
Por que as Formas das Galáxias Importam
Galáxias não são apenas imagens bonitas; sua aparência codifica suas histórias de vida. Sistemas suaves e arredondados tendem a ser mais antigos e tranquilos, enquanto galáxias com braços espirais proeminentes ou formas distorcidas frequentemente indicam formação estelar em andamento ou colisões recentes. Por um século, astrônomos organizaram essas formas em famílias — como elípticas, espirais e irregulares — para conectar a estrutura visível com a física subjacente. Mas, à medida que projetos como o Sloan Digital Sky Survey e observatórios futuros como o Legacy Survey of Space and Time do Rubin Observatory imageiam o céu com profundidade sem precedentes, a rotulagem manual tradicional tornou-se impossível de manter.
De Rótulos Humanos à Descoberta Não Supervisionada
A maioria dos avanços recentes na classificação automática de galáxias depende de aprendizado profundo supervisionado: computadores aprendem a partir de milhares de exemplos que já foram rotulados por humanos. Isso funciona bem, mas depende de conjuntos de treino criados com muito trabalho e fica limitado às categorias que as pessoas definem antecipadamente. Os autores seguem, em vez disso, uma rota não supervisionada, pedindo ao algoritmo que descubra agrupamentos naturais nos dados por conta própria. Para isso, eles usam redes poderosas de análise de imagem originalmente treinadas em fotografias do dia a dia e as adaptam às imagens de galáxias para extrair impressões visuais ricas, tudo sem precisar que qualquer galáxia possua um rótulo pré-atribuído.
Misturando Imagens com Medidas Físicas
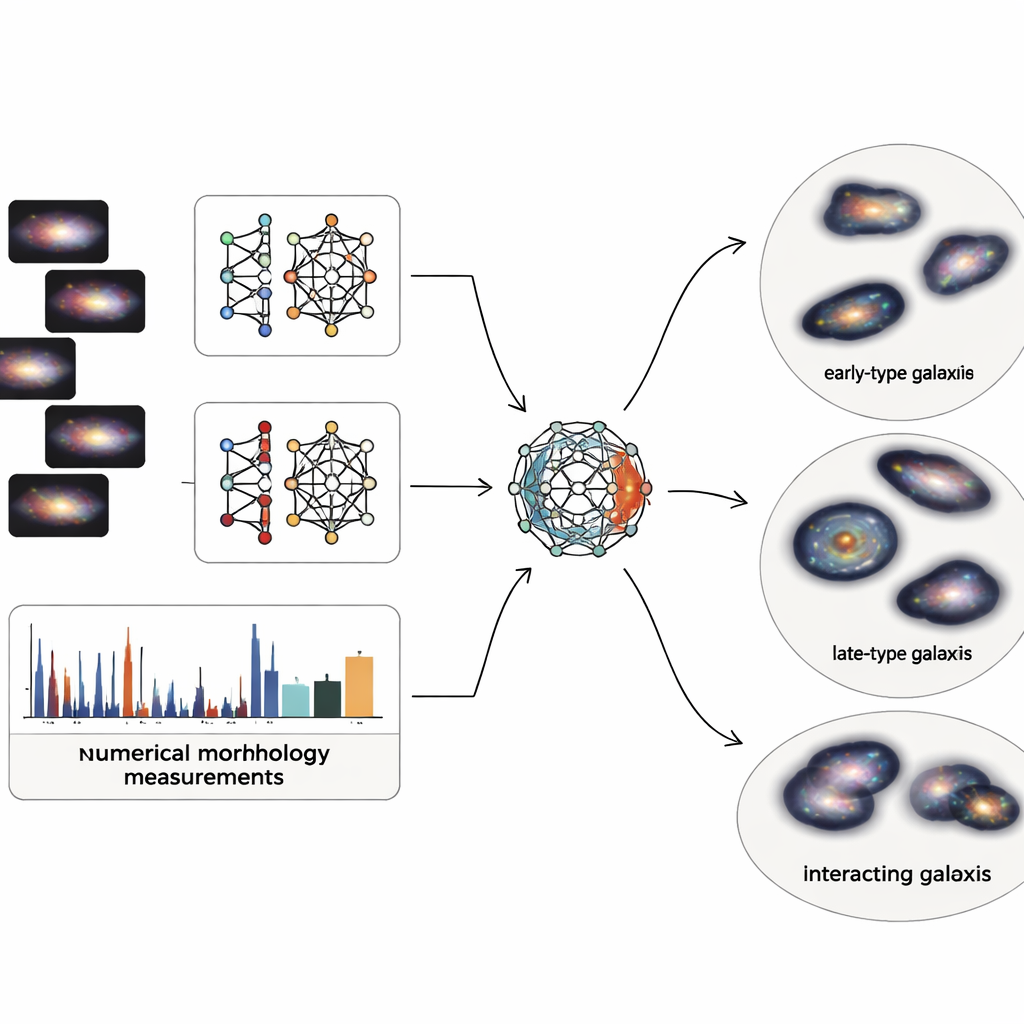
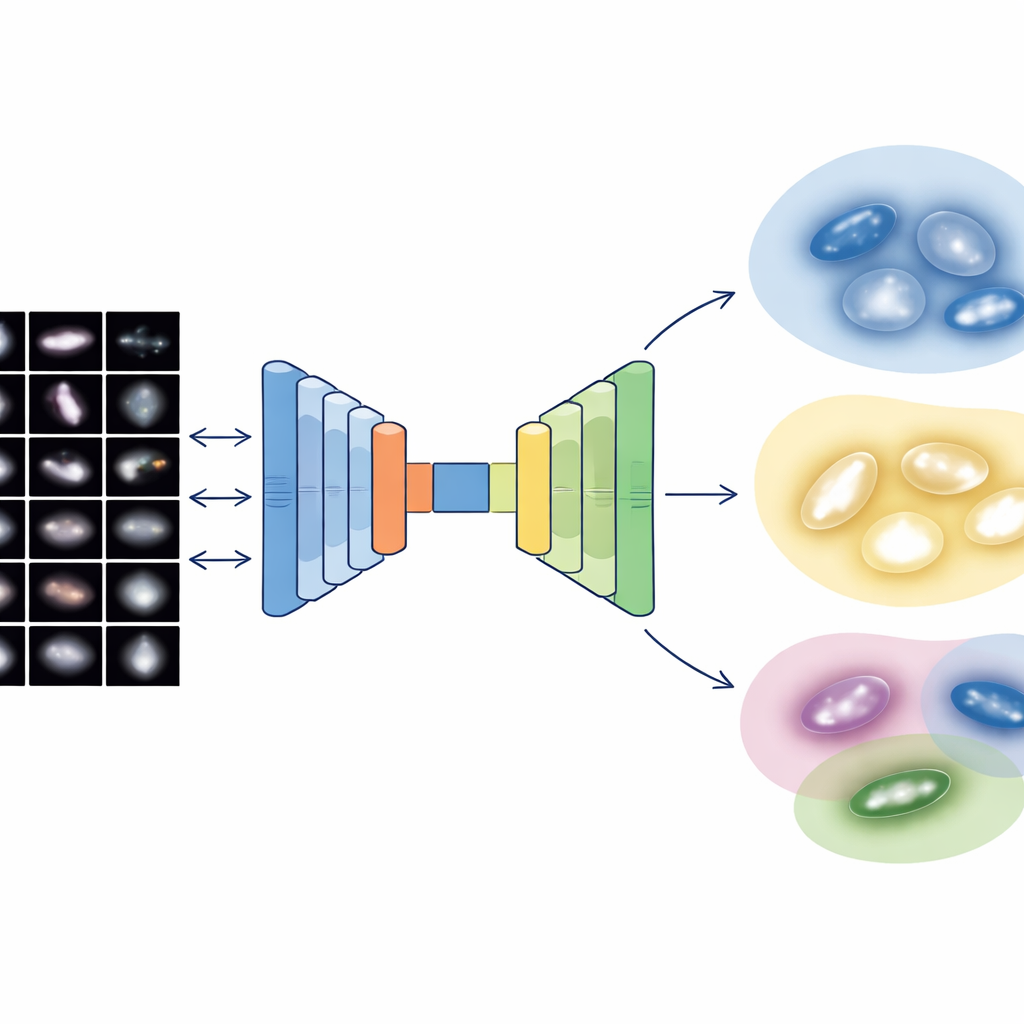
Imagens de galáxias contêm detalhes imensos, mas os astrônomos também usam descritores numéricos simples da estrutura, como quão centralizada está a luz, quão assimétrica a galáxia aparece, quão granuladas são suas regiões formadoras de estrelas e quão desigual é a distribuição de luz pelos pixels. A equipe combina ambos os mundos: características visuais profundas de duas redes neurais modernas e cinco medidas estruturais clássicas. Como a descrição baseada em imagem resulta em milhares de números enquanto as medidas físicas são apenas algumas, eles constroem um "autoencoder multimodal" especial — um tipo de rede neural que comprime toda a informação em um código interno compacto. Esse código de 64 números força o sistema a equilibrar o que aprende das imagens com o que é conhecido pela física básica das galáxias.
Deixando os Dados Caírem em Famílias Naturais
Uma vez que cada uma das 4.950 galáxias do levantamento Sloan, cuidadosamente limpas, é reduzida a esse código balanceado de 64 dimensões, os autores aplicam uma técnica probabilística de agrupamento que trata a população de galáxias como uma mistura suave de grupos sobrepostos. Em vez de forçar limites nítidos, ela atribui a cada galáxia um grau de pertencimento a vários clusters e marca apenas os 2 por cento mais extremos como verdadeiras anomalias ou artefatos. Os principais clusters resultantes se alinham bem com famílias familiares: sistemas suaves e compactos semelhantes a galáxias do tipo inicial; discos difusos e granulados parecidos com espirais tardias; sistemas em interação e perturbados; e discos intermediários, de transição. Testes internos mostram que essa representação combinada — imagem e física — produz grupos mais limpos e coerentes do que usar apenas imagens ou apenas números estruturais.
Verificando Contra Regras Clássicas e Escalando
Para ver se os agrupamentos não supervisionados do computador fazem sentido físico, os autores os comparam com limites empíricos de uso antigo baseados em diagramas simples de estrutura. Embora o algoritmo nunca tenha visto rótulos feitos por humanos, cerca de metade de suas classificações se alinha com essas categorias tradicionais, e o restante revela variações mais sutis que as regras antigas de dois parâmetros borram. Igualmente importante, todo o fluxo de trabalho é rápido: cada galáxia pode ser processada em apenas algumas dezenas de milissegundos em hardware moderno, um ritmo adequado para levantamentos em escala de petabytes que em breve catalogarão bilhões de galáxias.
Um Novo Mapa do Zoo de Galáxias
Em termos práticos, este trabalho mostra como ensinar um computador a "ver" e agrupar galáxias de uma maneira que respeita tanto o que os astrônomos já conhecem quanto o que os dados ainda podem estar escondendo. Ao mesclar padrões visuais com medidas físicas simples e ao permitir transições graduais em vez de caixas rígidas, o método constrói uma taxonomia galáctica flexível e escalável. Essa abordagem deve ajudar cientistas a filtrar a próxima enxurrada de imagens do céu, identificar sistemas raros ou incomuns e refinar nossa visão de como galáxias se formam, interagem e se transformam ao longo do tempo cósmico.
Citação: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Palavras-chave: morfologia galáctica, aprendizado não supervisionado, aprendizado profundo, levantamentos astronômicos, agrupamento