Clear Sky Science · it
Apprendimento profondo multimodale non supervisionato per la tassonomia della morfologia delle galassie: integrazione di ConvNeXtEmbeddings e parametri morfologici per la scienza dei rilevamenti su larga scala
Insegnare ai computer a leggere le forme delle galassie
I moderni rilevamenti del cielo fotografano miliardi di galassie, molto più di quanto qualsiasi team di astronomi — o di scienziati cittadini — possa classificare a occhio. Eppure le forme delle galassie, dalle ellissi lisce ai grandi bracci a spirale fino a fusioni caotiche, contengono indizi fondamentali su come l’universo costruisce le sue strutture. Questo articolo presenta un nuovo modo per far sì che i computer ordinino le galassie automaticamente, senza essere istruiti in anticipo su cosa cercare, aprendo la porta all’esplorazione della struttura cosmica su scala davvero massiccia.
Perché le forme delle galassie contano
Le galassie non sono solo belle immagini; il loro aspetto codifica le loro storie di vita. I sistemi lisci e arrotondati tendono a essere più vecchi e tranquilli, mentre galassie con bracci a spirale pronunciati o forme distorte spesso segnalano formazione stellare in corso o collisioni recenti. Per un secolo, gli astronomi hanno organizzato queste forme in famiglie — come ellittiche, spirali e irregolari — per collegare la struttura visibile alla fisica sottostante. Ma con progetti come lo Sloan Digital Sky Survey e futuri osservatori come il Legacy Survey of Space and Time dell’Osservatorio Rubin che immaginiamo il cielo con una profondità senza precedenti, l’etichettatura manuale tradizionale è diventata impossibile da sostenere.
Dalle etichette umane alla scoperta non supervisionata
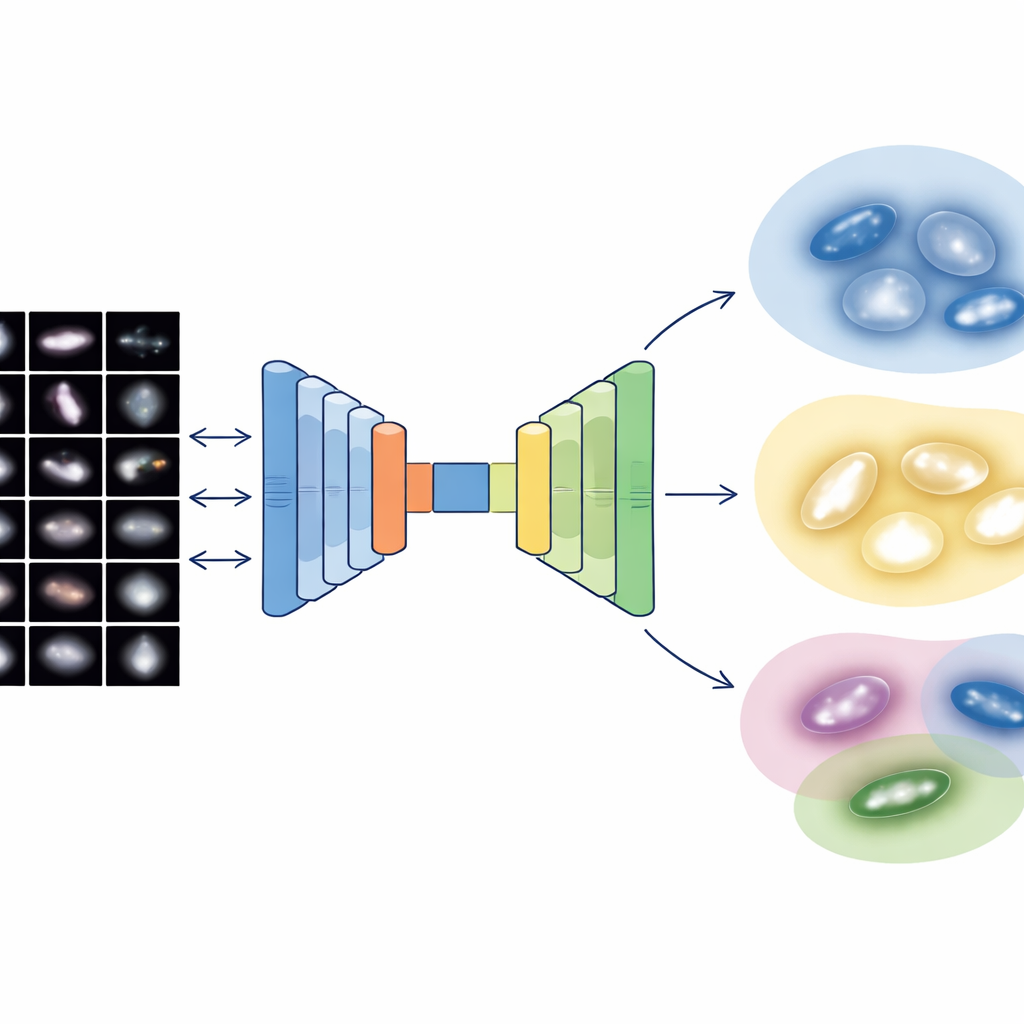
La maggior parte dei progressi recenti nella classificazione automatica delle galassie si basa sull’apprendimento profondo supervisionato: i computer imparano da migliaia di esempi già etichettati dagli esseri umani. Questo funziona bene, ma dipende da set di addestramento creati con cura e si limita alle categorie definite in anticipo dalle persone. Gli autori seguono invece una strada non supervisionata, chiedendo all’algoritmo di scoprire autonomamente raggruppamenti naturali nei dati. Per farlo, utilizzano potenti reti di analisi delle immagini originariamente addestrate su fotografie di uso quotidiano, poi le adattano alle immagini di galassie per estrarne ricche impronte visive, il tutto senza che alcuna galassia debba avere un’etichetta preassegnata.
Combinare immagini e misure fisiche
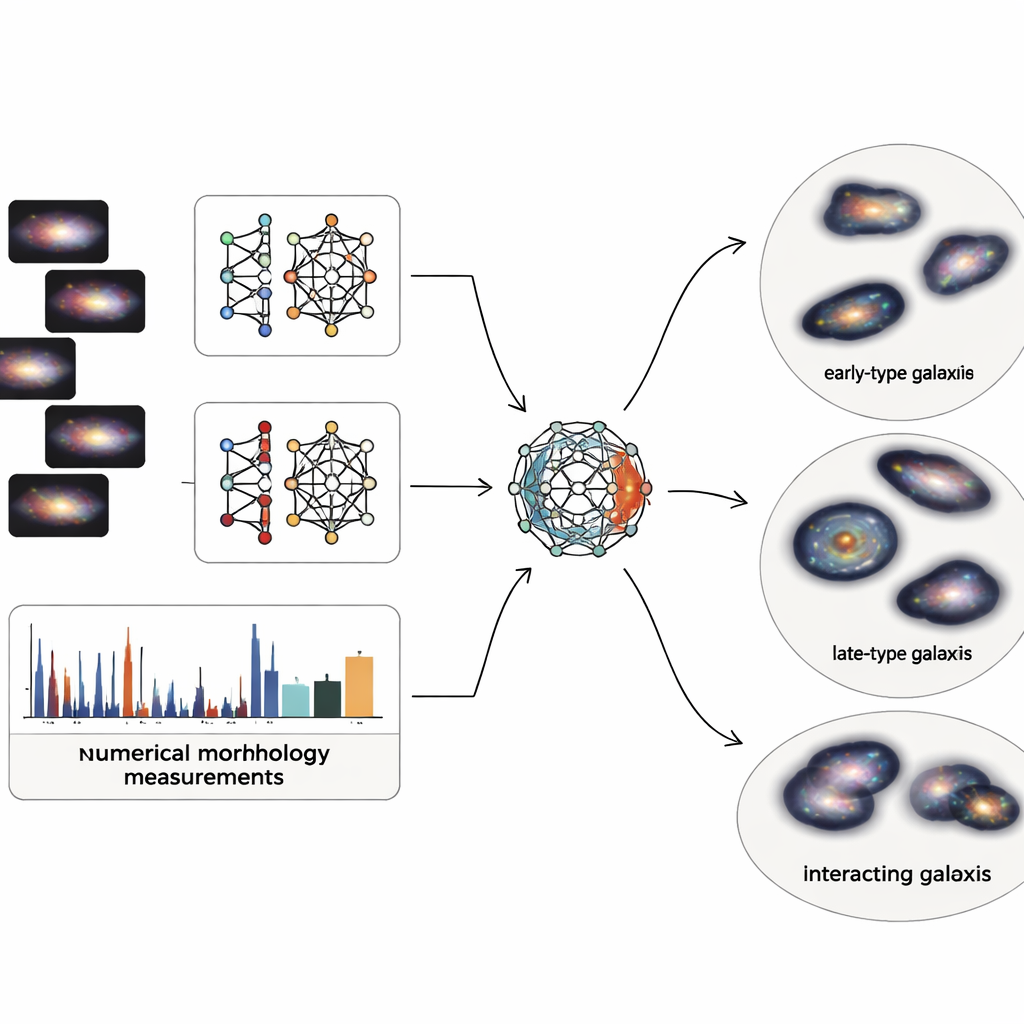
Le immagini delle galassie contengono dettagli immensi, ma gli astronomi usano anche descrittori numerici semplici della struttura, come quanto è concentrata la luce al centro, quanto la galassia appare sbilanciata, quanto sono grumose le regioni di formazione stellare e quanto la luminosità è distribuita in modo disomogeneo tra i pixel. Il gruppo combina entrambi i mondi: caratteristiche visive profonde da due moderne reti neurali e cinque misure strutturali classiche. Poiché la descrizione basata sulle immagini si traduce in migliaia di numeri mentre le misure fisiche sono soltanto poche, costruiscono un particolare «autoencoder multimodale» — un tipo di rete neurale che comprime tutte le informazioni in un codice interno compatto. Questo codice a 64 numeri costringe il sistema a bilanciare ciò che apprende dalle immagini con ciò che è noto dalla fisica basilare delle galassie.
Lascare che i dati si dispongano in famiglie naturali
Una volta che ciascuna delle 4.950 galassie del sondaggio Sloan, accuratamente ripulite, è ridotta a questo codice bilanciato a 64 dimensioni, gli autori applicano una tecnica di clustering probabilistico che tratta la popolazione di galassie come una miscela continua di gruppi sovrapposti. Invece di imporre confini netti, assegna a ogni galassia un grado di appartenenza a più cluster e segnala solo il 2 percento più estremo come vere anomalie o artefatti. I principali cluster risultanti si allineano bene con le famiglie familiari: sistemi lisci e compatti che ricordano galassie di tipo precoce; dischi diffusi e grumosi simili a spirali di tipo tardivo; sistemi interagenti e disturbati; e dischi intermedi e di transizione. I test interni mostrano che questa rappresentazione che combina immagini e fisica produce gruppi più puliti e coerenti rispetto all’uso delle sole immagini o delle sole misure strutturali.
Confronto con regole classiche e scalabilità
Per verificare se i raggruppamenti non supervisionati del computer hanno senso fisico, gli autori li confrontano con i confini empirici usati da tempo basati su diagrammi di struttura semplici. Anche se l’algoritmo non ha mai visto etichette create dall’uomo, circa la metà delle sue classificazioni si allinea a queste categorie tradizionali, mentre il resto rivela variazioni più sottili che le vecchie regole a due parametri appiattiscono. Altrettanto importante, l’intera pipeline è veloce: ogni galassia può essere processata in poche decine di millisecondi su hardware moderno, un ritmo adatto a rilevamenti su scala di petabyte che presto catalogheranno miliardi di galassie.
Una nuova mappa dello Zoo delle Galassie
In termini pratici, questo lavoro mostra come insegnare a un computer a «vedere» e raggruppare le galassie in modo che rispetti sia ciò che gli astronomi già conoscono sia ciò che i dati potrebbero ancora nascondere. Combinando pattern visivi con semplici misure fisiche e consentendo transizioni graduali invece di box rigidi, il metodo costruisce una tassonomia delle galassie flessibile e scalabile. Questo approccio dovrebbe aiutare gli scienziati a setacciare l’imminente ondata di immagini del cielo, individuare sistemi rari o insoliti e affinare la nostra visione su come le galassie si formano, interagiscono e si trasformano nel tempo cosmico.
Citazione: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Parole chiave: morfologia delle galassie, apprendimento non supervisionato, apprendimento profondo, rilevamenti astronomici, clustering