Clear Sky Science · ru
Надзорное мультимодальное глубокое обучение для таксономии морфологии галактик: интеграция ConvNeXtEmbeddings и морфологических параметров для масштабируемой науки опросов
Обучая компьютеры «читать» формы галактик
Современные обзоры неба фотографируют миллиарды галактик — значительно больше, чем любая команда астрономов или даже сообщество гражданских учёных смогут классифицировать вручную. Тем не менее форма галактик, от гладких эллипсов до величественных спиралей и хаотичных слияний, содержит важные подсказки о том, как во Вселенной формируются структуры. В этой статье предложен новый способ автоматической сортировки галактик компьютером без предварительных указаний о том, что искать, что открывает возможность изучать космическую структуру в поистине огромных масштабах.
Почему важны формы галактик
Галактики — это не просто красивые снимки; их внешний вид кодирует их жизненные истории. Гладкие округлые системы, как правило, старше и спокойнее, тогда как галактики с ярко выраженными спиральными рукавами или искажённой формой часто свидетельствуют о продолжающемся рождении звёзд или недавних столкновениях. На протяжении столетия астрономы группировали эти формы в семейства — такие как эллиптические, спиральные и неправильные — чтобы связать видимую структуру с базовой физикой. Но по мере того как проекты вроде Sloan Digital Sky Survey и будущие обсерватории, например Legacy Survey of Space and Time Рубина, снимают небо с беспрецедентной глубиной, традиционная ручная разметка становится невозможной для поддержания.
От человеческих меток к обнаружению без учителя
Большинство недавних достижений в автоматической классификации галактик основаны на контролируемом (supervised) глубоком обучении: компьютеры обучаются на тысячах примеров, уже размеченных людьми. Это даёт хорошие результаты, но зависит от кропотливо созданных обучающих выборок и ограничено категориями, заданными заранее. Авторы идут другим путём — они используют обучение без учителя, позволяя алгоритму самостоятельно обнаруживать естественные группы в данных. Для этого применяют мощные сети для анализа изображений, изначально натренированные на обычных фотографиях, затем адаптируют их к изображениям галактик, чтобы извлечь богатые визуальные отпечатки, при этом ни одной галактике не присваивается заранее заданная метка.
Смешение изображений и физических измерений
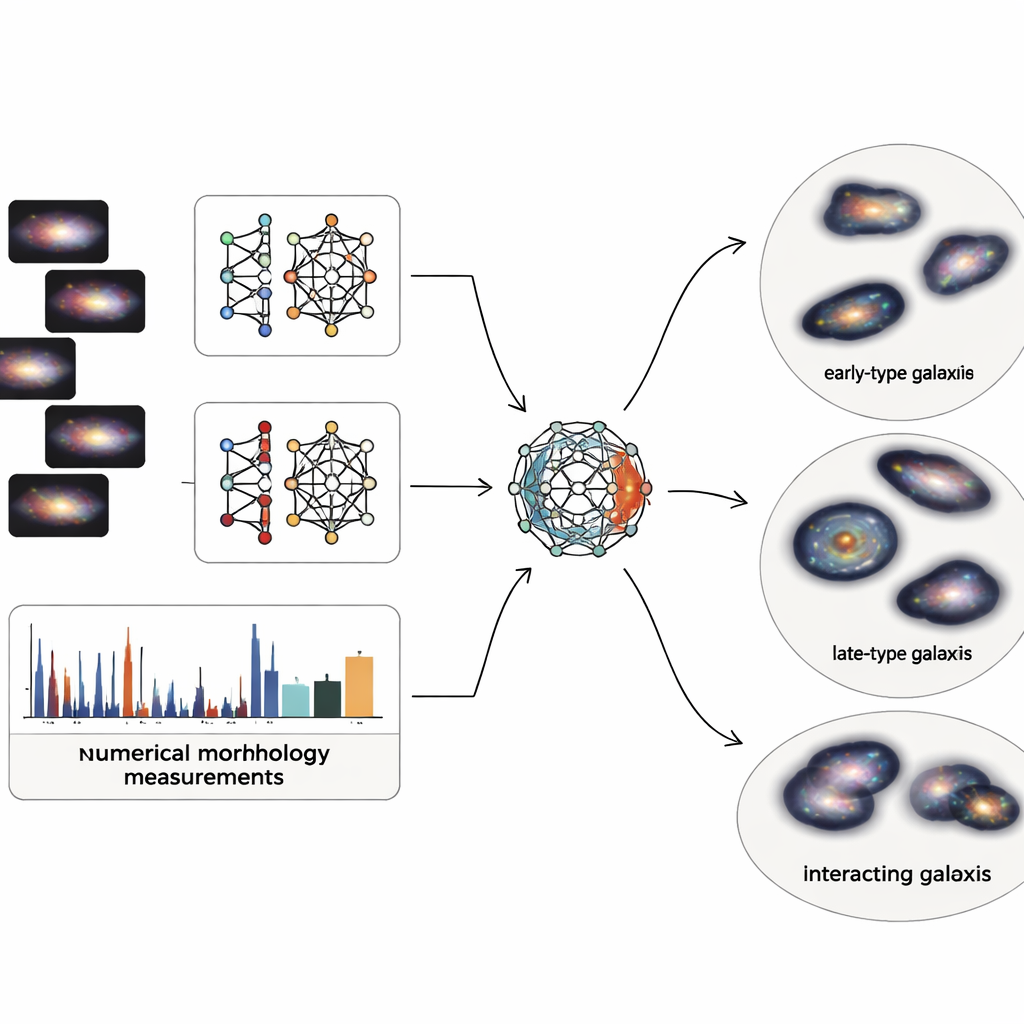
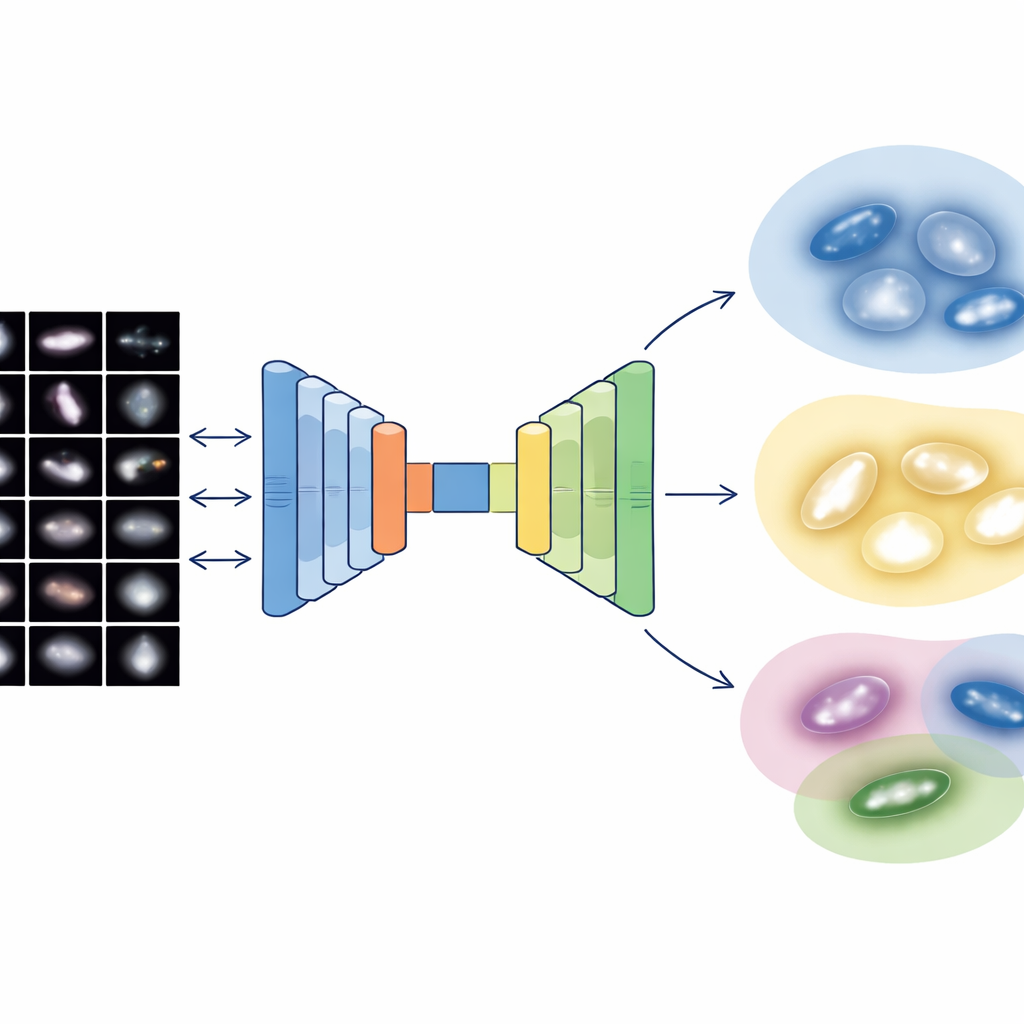
Изображения галактик содержат огромное количество деталей, но астрономы также используют простые численные описания структуры: насколько сосредоточен свет в центре, насколько асимметрична галактика, насколько комковаты регионы звездообразования и как неравномерно распределён свет по пикселям. Команда объединяет оба подхода: глубинные визуальные признаки из двух современных нейросетей и пять классических мер структуры. Поскольку описание на основе изображений даёт тысячи чисел, а физические меры — всего несколько, они строят специализированный «мультимодальный автокодировщик» — тип нейросети, сжимающий всю информацию в компактный внутренний код. Этот 64-значный код вынуждает систему уравновешивать то, что она узнаёт из изображений, и то, что известно из базовой физики галактик.
Позволяя данным образовывать естественные семьи
Когда каждая из 4 950 тщательно очищенных галактик обзора Sloan сведена к такому сбалансированному 64-мерному коду, авторы применяют вероятностную методику кластеризации, рассматривающую популяцию галактик как плавную смесь перекрывающихся групп. Вместо принудительного проведения чётких границ алгоритм присваивает каждой галактике степень принадлежности к нескольким кластерам и помечает лишь наиболее экстремальные 2 процента как истинные аномалии или артефакты. Получившиеся основные кластеры хорошо соответствуют знакомым семействам: гладкие компактные системы, напоминающие галактики ранних типов; диффузные комковатые диски, близкие к поздним спиралям; взаимодействующие и искажённые системы; а также промежуточные переходные диски. Внутренние тесты показывают, что это комбинированное представление — изображение плюс физика — даёт более чистые и когерентные группы, чем использование только изображений или только структурных чисел.
Проверка по классическим правилам и масштабирование
Чтобы понять, имеют ли бессупервизорные группировки физический смысл, авторы сравнивают их с давно используемыми эвристическими границами, основанными на простых диаграммах структуры. Хотя алгоритм никогда не видел размеченных человеком меток, около половины его классификаций совпадают с традиционными категориями, а остальное выявляет более тонкие вариации, которые старые двухпараметрические правила сглаживали. Не менее важно, что весь конвейер работает быстро: обработка одной галактики занимает всего несколько десятков миллисекунд на современном оборудовании, темп, подходящий для петабайтных обзоров, которые вскоре каталогизируют миллиарды галактик.
Новая карта «Зоопарка галактик»
Проще говоря, эта работа показывает, как научить компьютер «видеть» и группировать галактики так, чтобы уважать как уже имеющиеся астрономические знания, так и то, что данные ещё могут скрывать. Смешивая визуальные паттерны с простыми физическими измерениями и допуская плавные переходы вместо жёстких ящиков, метод строит гибкую масштабируемую таксономию галактик. Такой подход поможет учёным переработать грядущий поток изображений неба, обнаружить редкие или необычные системы и уточнить наше представление о том, как галактики формируются, взаимодействуют и трансформируются в космическом времени.
Цитирование: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Ключевые слова: морфология галактик, обучение без учителя, глубокое обучение, астрономические обзоры, кластеризация