Clear Sky Science · sv
Oövervakad multimodal djupinlärning för galaxmorfologisk taxonomi: integrering av ConvNeXt-embeddings och morfologiska parametrar för skalbar undersökningsvetenskap
Att lära datorer att läsa galaxernas former
Moderna himmelsundersökningar fotograferar miljarder galaxer, långt fler än något team av astronomer — eller medborgarforskare — någonsin skulle kunna klassificera för hand. Ändå bär galaxers former, från släta ellipser till storslagna spiraler och kaotiska sammanslagningar, viktiga ledtrådar om hur universum bygger sina strukturer. Denna artikel presenterar ett nytt sätt för datorer att automatiskt sortera galaxer, utan att få i förväg instruktioner om vad de ska leta efter, vilket öppnar möjligheter att utforska kosmisk struktur i verkligt massiv skala.
Varför galaxers former spelar roll
Galaxer är inte bara vackra bilder; deras utseende kodar deras livshistorier. Släta, runda system tenderar att vara äldre och lugnare, medan galaxer med framträdande spiralarmar eller förvrängda former ofta signalerar pågående stjärnbildning eller nyliga kollisioner. I ett århundrade har astronomer organiserat dessa former i familjer — såsom elliptiska, spiralformade och oregelbundna — för att koppla synlig struktur till den underliggande fysiken. Men i takt med att projekt som Sloan Digital Sky Survey och kommande observatorier som Rubin Observatorys Legacy Survey of Space and Time avbildar himlen på ett tidigare osett djup har traditionell handmärkning blivit omöjlig att upprätthålla.
Från mänskliga etiketter till oövervakad upptäckt
De flesta senaste framsteg inom automatisk galaxklassificering bygger på övervakad djupinlärning: datorer lär sig från tusentals exempel som människor redan märkt upp. Det fungerar bra, men är beroende av mödosamt skapade träningsset och begränsat till de kategorier människor definierat i förväg. Författarna väljer istället en oövervakad väg och låter algoritmen upptäcka naturliga grupperingar i datan på egen hand. För att göra detta använder de kraftfulla bildanalysnätverk som ursprungligen tränats på vardagliga fotografier, och anpassar dem till galaxbilder för att extrahera rika visuella fingeravtryck — allt utan att någon galax behöver en förutbestämd etikett.
Att blanda bilder med fysiska mätningar
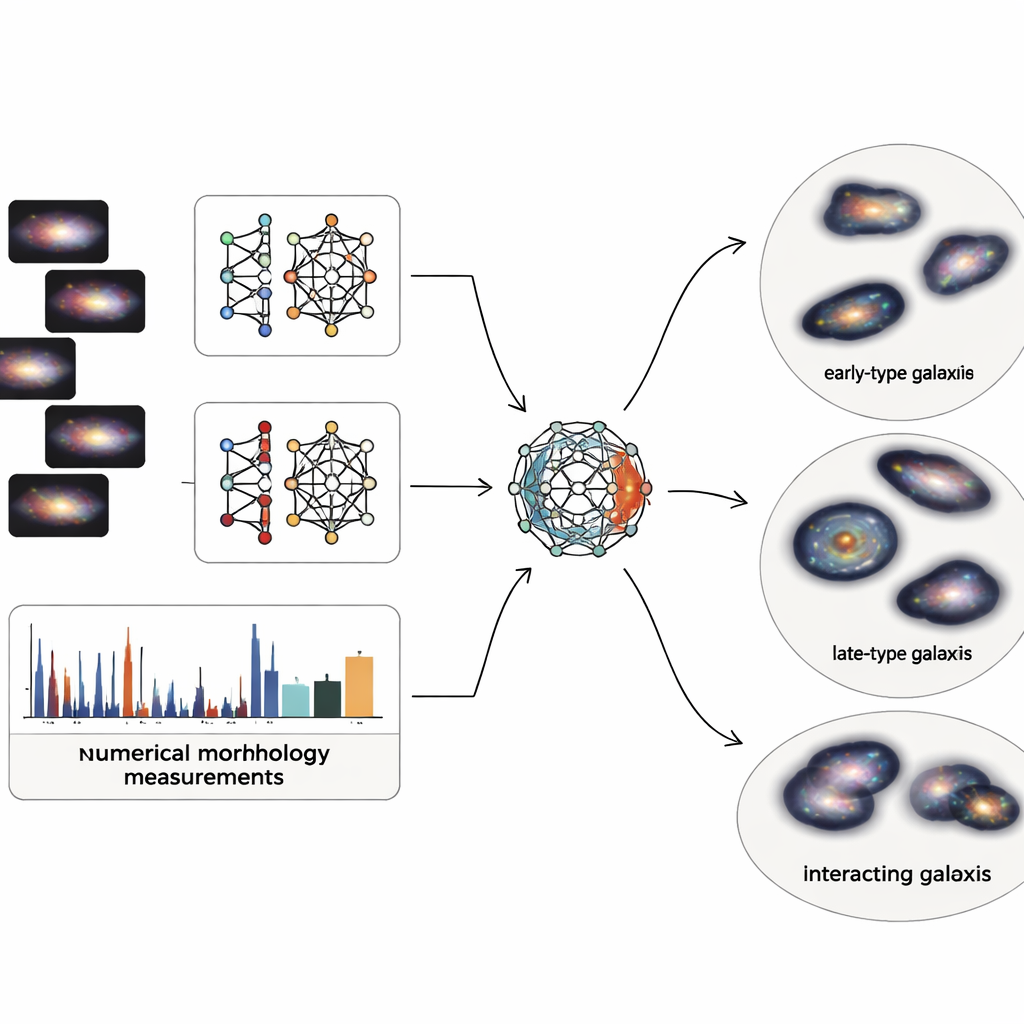
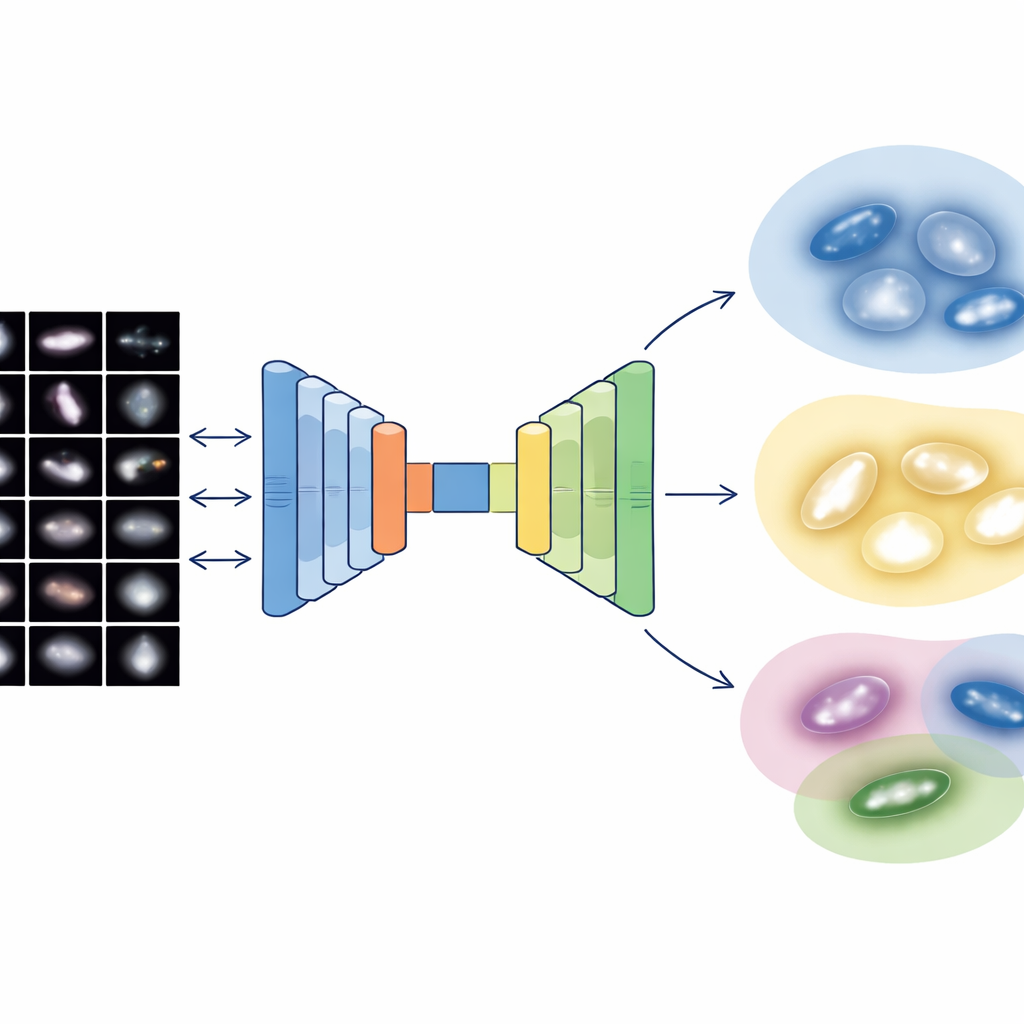
Galaxbilder innehåller enorm detaljrikedom, men astronomer använder också enkla numeriska beskrivningar av struktur, såsom hur centralt koncentrerat ljuset är, hur snett galaxen ter sig, hur klumpiga stjärnbildningsregionerna är och hur ojämnt ljuset fördelas över pixlarna. Teamet kombinerar båda världarna: djupa visuella egenskaper från två moderna neurala nätverk och fem klassiska strukturella mått. Eftersom bildbaserade beskrivningar kan ge tusentals siffror medan de fysiska måtten bara är ett fåtal, bygger de en särskild "multimodal autoencoder" — en typ av neuralt nätverk som komprimerar all information till en kompakt intern kod. Denna 64-siffriga kod tvingar systemet att väga vad det lär sig från bilderna mot vad som är känt från grundläggande galaxfysik.
Att låta data falla i naturliga familjer
När var och en av de 4 950 noggrant rengjorda Sloan-undersökningens galaxer reducerats till denna balanserade, 64-dimensionella kod, tillämpar författarna en probabilistisk klustringsteknik som behandlar galaxpopulationen som en jämn blandning av överlappande grupper. Istället för att tvinga fram skarpa gränser tilldelar den varje galax en grad av medlemskap i flera kluster och flaggar endast de mest extrema 2 procenten som verkliga avvikare eller artefakter. De resulterande huvudklustren stämmer väl överens med välkända familjer: släta, kompakta system som liknar tidiga typer; diffusa, klumpiga skivor liknande sena spiraler; interagerande och störda system; samt intermediära, övergångsformade skivor. Interna tester visar att denna kombinerade bild-och-fysik-representation skapar renare, mer sammanhängande grupper än att använda enbart bilder eller enbart strukturella mått.
Kontroll mot klassiska regler och uppskalning
För att se om datorns oövervakade grupperingarna har fysisk mening jämför författarna dem med länge använda tumregler baserade på enkla strukturdigram. Fast algoritmen aldrig såg några mänskliga etiketter stämmer ungefär hälften av dess klassificeringar överens med dessa traditionella kategorier, och resten avslöjar mer subtila variationer som de äldre två-parameter-reglerna suddar ihop. Lika viktigt är att hela pipeline:en går snabbt — varje galax kan bearbetas på bara några tiotals millisekunder på modern hårdvara, en hastighet som är lämplig för petabyte-stora undersökningar som snart kommer att katalogisera miljarder galaxer.
En ny karta över Galaxy Zoo
I vardagliga termer visar detta arbete hur man lär en dator att "se" och gruppera galaxer på ett sätt som respekterar både vad astronomer redan vet och vad datan ännu kan dölja. Genom att blanda visuella mönster med enkla fysiska mätningar och genom att tillåta gradvisa övergångar snarare än rigida fack bygger metoden en flexibel, skalbar galaxtaxonomi. Detta tillvägagångssätt bör hjälpa forskare att sila igenom den kommande strömmen av himmelbilder, upptäcka sällsynta eller ovanliga system och förfina vår bild av hur galaxer bildas, interagerar och omvandlas över kosmisk tid.
Citering: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Nyckelord: galaxmorfologi, oövervakad inlärning, djupinlärning, astronomiska undersökningar, klustring