Clear Sky Science · fr
Apprentissage profond multimodal non supervisé pour la taxonomie morphologique des galaxies : intégration des ConvNeXtEmbeddings et des paramètres morphologiques pour une science des relevés à grande échelle
Apprendre aux ordinateurs à lire les formes des galaxies
Les relevés du ciel modernes photographient des milliards de galaxies, bien plus que ne pourrait en classer à l'œil une équipe d'astronomes — ou des citoyens scientifiques. Pourtant, les formes des galaxies, des ellipses lisses aux spirales majestueuses en passant par les fusions chaotiques, contiennent des indices cruciaux sur la façon dont l'univers construit ses structures. Cet article présente une nouvelle méthode permettant aux ordinateurs de trier automatiquement les galaxies, sans qu'on leur dise à l'avance quoi chercher, ouvrant la voie à l'exploration de la structure cosmique à une échelle véritablement massive.
Pourquoi la forme des galaxies compte
Les galaxies ne sont pas que de jolies images ; leur apparence encode leur histoire de vie. Les systèmes lisses et ronds tendent à être plus âgés et plus calmes, tandis que les galaxies avec des bras spiraux prononcés ou des formes déformées signalent souvent une formation d'étoiles active ou des collisions récentes. Depuis un siècle, les astronomes organisent ces formes en familles — telles que elliptiques, spirales et irrégulières — pour relier la structure visible à la physique sous-jacente. Mais à mesure que des projets comme le Sloan Digital Sky Survey et des observatoires à venir comme le Legacy Survey of Space and Time du Rubin Observatory imagent le ciel avec une profondeur sans précédent, l'étiquetage manuel traditionnel devient impossible à maintenir.
Des étiquettes humaines à la découverte non supervisée
La plupart des avancées récentes en classification automatique de galaxies reposent sur l'apprentissage profond supervisé : les ordinateurs apprennent à partir de milliers d'exemples déjà étiquetés par des humains. Cela fonctionne bien, mais dépend de jeux d'entraînement créés laborieusement et se limite aux catégories définies à l'avance par des personnes. Les auteurs choisissent plutôt une voie non supervisée, demandant à l'algorithme de découvrir lui-même les groupements naturels dans les données. Pour ce faire, ils utilisent de puissants réseaux d'analyse d'images initialement entraînés sur des photographies du quotidien, puis les adaptent aux images de galaxies pour extraire des empreintes visuelles riches, le tout sans qu'aucune galaxie n'ait besoin d'une étiquette préassignée.
Mélanger images et mesures physiques
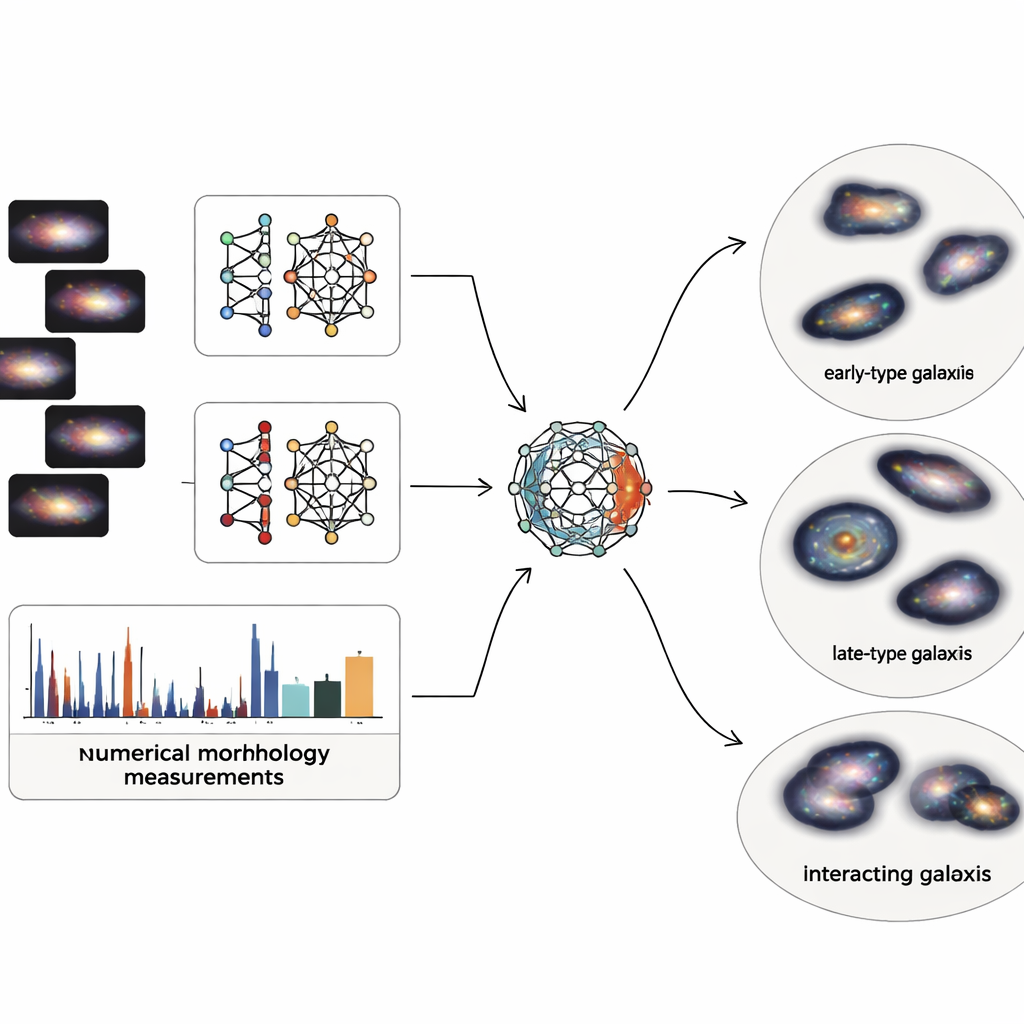
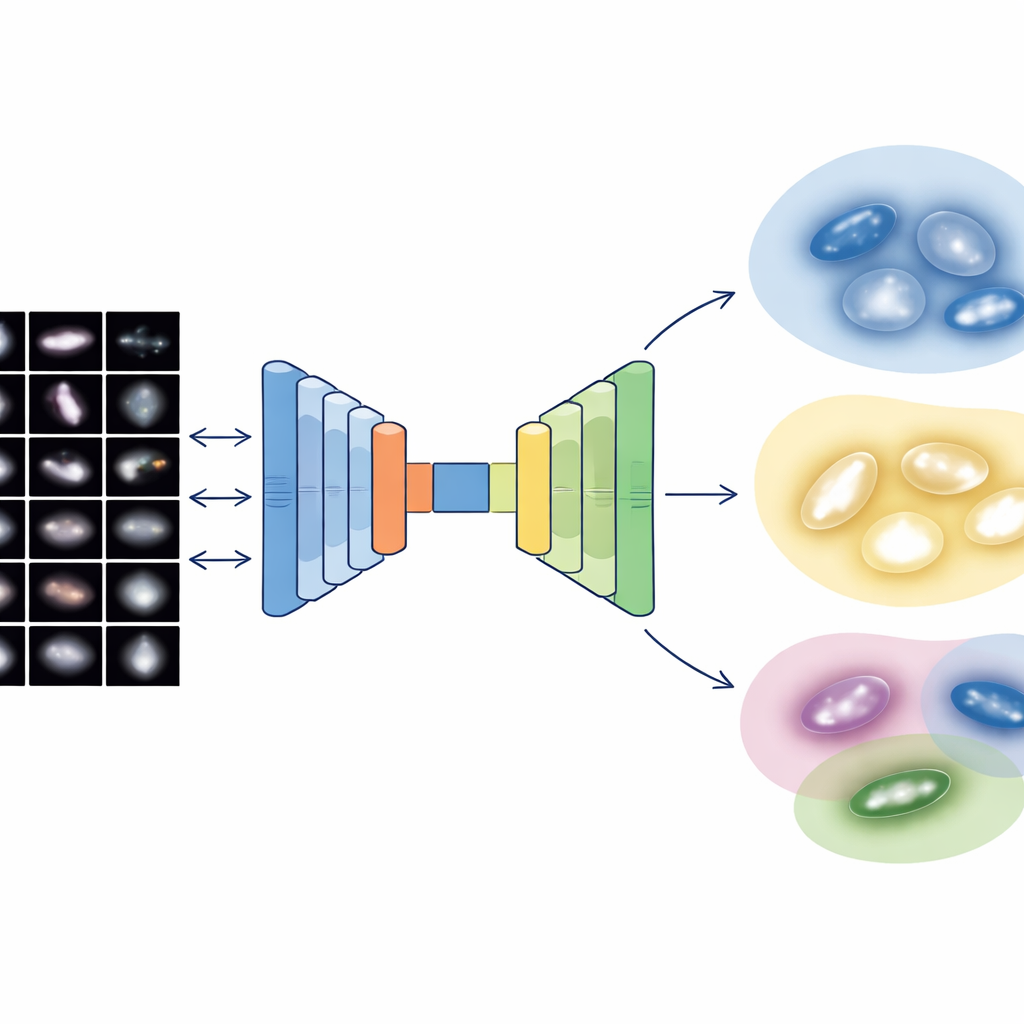
Les images de galaxies contiennent une quantité énorme de détails, mais les astronomes utilisent aussi des descripteurs numériques simples de la structure, comme la concentration centrale de la lumière, l'asymétrie de la galaxie, l'aspect grumeleux des régions de formation d'étoiles et la répartition inégale de la lumière sur les pixels. L'équipe combine ces deux mondes : des caractéristiques visuelles profondes issues de deux réseaux neuronaux modernes et cinq mesures structurelles classiques. Comme la description basée sur l'image produit des milliers de nombres tandis que les mesures physiques ne sont qu'une poignée, ils construisent un « autoencodeur multimodal » spécial — un type de réseau neuronal qui compresse toutes les informations en un code interne compact. Ce code de 64 nombres contraint le système à équilibrer ce qu'il apprend des images et ce que révèlent les connaissances basiques en physique des galaxies.
Laisser les données se regrouper naturellement
Une fois que chacune des 4 950 galaxies soigneusement nettoyées du relevé Sloan est réduite à ce code équilibré de 64 dimensions, les auteurs appliquent une technique de regroupement probabiliste qui traite la population de galaxies comme un mélange continu de groupes qui se chevauchent. Plutôt que d'imposer des frontières nettes, elle attribue à chaque galaxie un degré d'appartenance à plusieurs clusters et ne signale comme véritables anomalies ou artefacts que les 2 % les plus extrêmes. Les clusters principaux obtenus correspondent bien aux familles familières : systèmes lisses et compacts ressemblant aux galaxies de type précoce ; disques diffus et grumeleux proches des spirales de type tardif ; systèmes en interaction et perturbés ; et disques intermédiaires et transitionnels. Des tests internes montrent que cette représentation combinée image-plus-physique produit des groupes plus propres et plus cohérents que l'utilisation seule des images ou des mesures structurelles.
Vérification par rapport aux règles classiques et montée en échelle
Pour savoir si les regroupements non supervisés de l'ordinateur ont un sens physique, les auteurs les comparent aux frontières empiriques de longue date basées sur de simples diagrammes structurels. Même si l'algorithme n'a jamais vu d'étiquettes humaines, environ la moitié de ses classifications s'alignent sur ces catégories traditionnelles, et le reste révèle des variations plus subtiles que les anciennes règles à deux paramètres amalgamaient. Tout aussi important, l'ensemble du pipeline s'exécute rapidement : chaque galaxie peut être traitée en quelques dizaines de millisecondes sur du matériel moderne, un rythme adapté aux relevés à l'échelle du pétaoctet qui catalogueront bientôt des milliards de galaxies.
Une nouvelle carte du Galaxy Zoo
En termes concrets, ce travail montre comment apprendre à un ordinateur à « voir » et à grouper les galaxies d'une manière qui respecte à la fois ce que les astronomes savent déjà et ce que les données peuvent encore cacher. En mêlant motifs visuels et mesures physiques simples et en autorisant des transitions progressives plutôt que des boîtes rigides, la méthode construit une taxonomie galactique flexible et évolutive. Cette approche devrait aider les scientifiques à trier le flot prochain d'images du ciel, repérer des systèmes rares ou inhabituels et affiner notre compréhension de la formation, de l'interaction et de la transformation des galaxies au fil du temps cosmique.
Citation: Selim, I.M., Farahat, A.S., Basmsm, L.H. et al. Unsupervised multimodal deep learning for galaxy morphology taxonomy: integrating ConvNeXtEmbeddings and morphological parameters for scalable survey science. Sci Rep 16, 12183 (2026). https://doi.org/10.1038/s41598-026-45369-5
Mots-clés: morphologie des galaxies, apprentissage non supervisé, apprentissage profond, relevés astronomiques, regroupement