Clear Sky Science · zh
面向原型的对比均值教师用于无监督域自适应目标检测
教计算机在新环境中识别物体
现代人工智能系统能以惊人精度在图片中找到汽车、行人和路牌——直到场景发生变化。一个在阳光明媚的城市街道上训练的检测器,在雾天、夜间或风格化艺术图像上可能会表现失常。本文提出了一种“教老师”的新方法,使这些系统能够在不依赖人工重新标注方框的情况下,自行适应新条件。
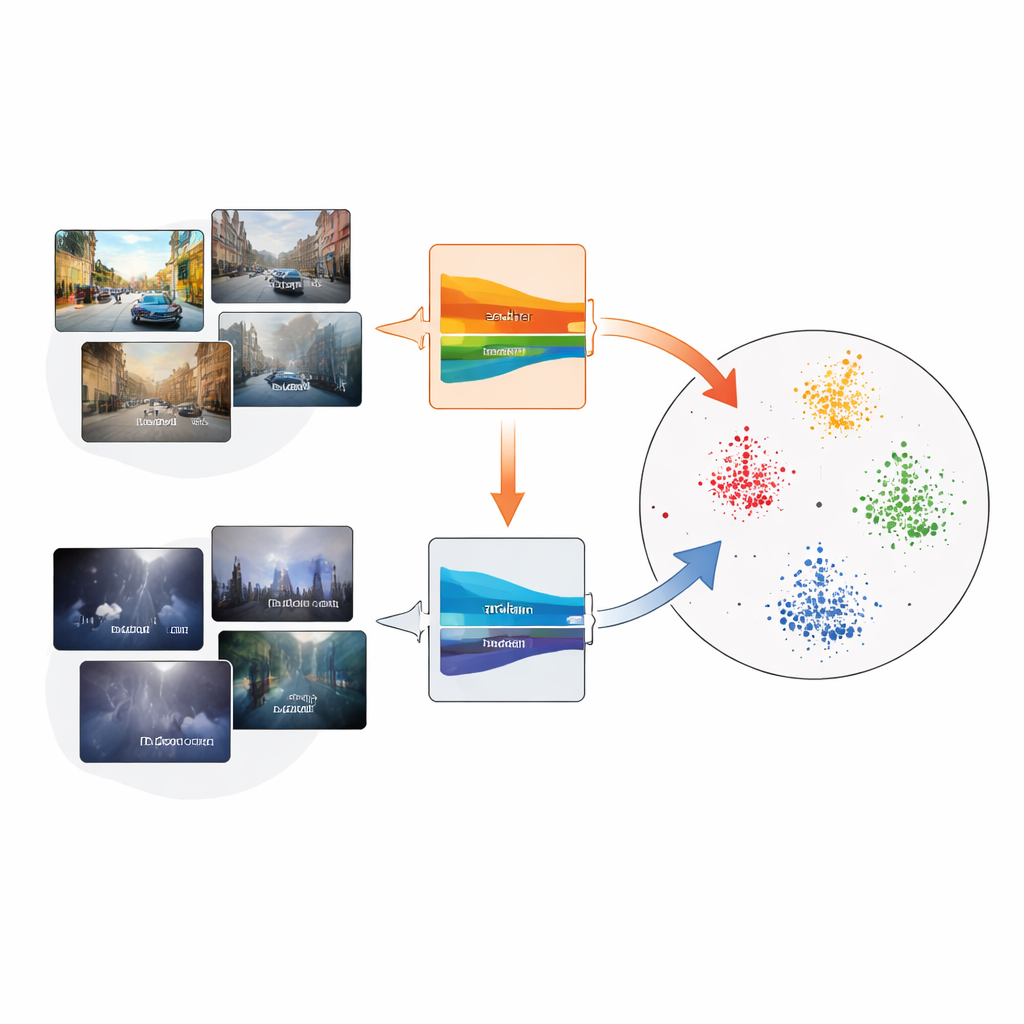
当世界改变时目标检测器为何会吃力
目标检测依赖大量标注图像,其中每辆车、每辆公交或每辆自行车都被精确地框出。但真实世界的相机条件很少与这些训练条件完全一致。不同的天气、光照或相机类型会改变物体的外观——这被称为域偏移。当发生这种情况时,在一种域(例如晴朗白天的交通场景)上训练的检测器,可能在另一种域(如雾天高速或夜间驾驶)上严重失灵。为每种新条件收集新标签代价高昂,因此研究者寻求仅使用新域的未标注数据来适配检测器的方法。
带内置指南的自我教学系统
一种流行策略是让模型自我教导。将“教师”网络设为“学生”网络的平滑版本,在未标注的目标图像上预测框;这些预测,称为伪标签,然后用来训练学生网络。随着时间推移,学生改善,教师以学生权重的滑动平均更新。然而,如果早期伪标签有误——例如在浓雾中漏检物体——错误可能会累积。作者展示了三种思想可以结合以稳定这种自我训练:均值教师框架、对比学习(将相关特征拉近、将无关特征推远)和将每个类别总结为紧凑“原型”的方法。
作为特征空间地标的原型
所提PoCoMT框架的核心是原型对齐网络,或称ProtoAN。ProtoAN不是将每个对象与所有其他对象逐一比较,而是为每个类别(如汽车或行人)学习一小组具有代表性的点——原型。图像区域提取的特征被映射到一个特殊空间,使得来自不同域但属于同一类别的样本围绕其共享的原型聚集,而不同类别则被彼此分开。对比损失鼓励这种聚类,既在单一域内发生,也在源域与目标域之间发生。关键在于,这一机制把背景也视为独立类别,帮助系统将真实物体与杂乱背景区分开来。

更好地利用未标注数据
PoCoMT通过两种方式改进了教师的伪标签。首先,“信息最大化”目标促使对目标图像的预测既在每个对象上有较高置信度,又在类别上保持多样性,从而避免将所有东西标为同一类的简单策略。其次,ProtoAN通过将特征与原型进行比较来细化伪标签,而不是盲目信任原始预测。如果某个区域的预测类别与最近的原型不匹配,则该标签可以被调整。这使系统对噪声更具容忍性:即便作者在训练期间故意破坏了许多伪标签,PoCoMT的性能也比竞争方法更平缓地下降。
在复杂真实场景中更强的检测器
在一系列广泛基准上测试——包括晴天到雾天街道、合成到真实的交通、白天到黄昏驾驶以及现实到艺术化图像——PoCoMT持续超越现有的无监督域自适应技术,常常在检测准确率上领先几个百分点。在某些情况下,它甚至优于直接在目标域带标签数据上训练的模型,这得益于它能够同时利用带标签的源图像和大量未标注的目标图像。对于非专业读者,结论很直接:通过让目标检测器为每个类别建立自己的内部“地标”,并谨慎引导教师与学生之间的信息交换,这种方法使视觉 AI 在面对与训练数据不同的世界时更加稳健。
引用: Cao, Q., Tao, J., Dan, Y. et al. Prototype-oriented contrastive mean-teacher for unsupervised domain adaptive object detection. Sci Rep 16, 10869 (2026). https://doi.org/10.1038/s41598-026-44991-7
关键词: 无监督域自适应, 目标检测, 自我训练, 对比学习, 原型学习