Clear Sky Science · pt
Professor médio contrastivo orientado por protótipos para detecção de objetos com adaptação de domínio não supervisionada
Ensinando computadores a detectar objetos em novos cenários
Sistemas de IA modernos conseguem localizar carros, pessoas e placas de rua em fotos com precisão impressionante — até que o cenário mude. Um detector treinado em ruas ensolaradas da cidade pode falhar na névoa, à noite ou em obras de arte estilizadas. Este artigo apresenta uma nova maneira de “ensinar o professor” dentro desses sistemas para que eles possam se adaptar a novas condições sem exigir novas caixas desenhadas à mão por humanos.
Por que detectores de objetos têm dificuldades quando o mundo muda
A detecção de objetos depende de grandes coleções de imagens rotuladas nas quais cada carro, ônibus ou bicicleta é cuidadosamente delimitado por caixas. Mas as câmeras do mundo real raramente correspondem a essas condições de treinamento. Diferentes condições climáticas, iluminação ou tipos de câmera alteram a aparência dos objetos — um fenômeno conhecido como deslocamento de domínio. Quando isso acontece, detectores treinados em um domínio, como cenas de trânsito claras e diurnas, podem falhar seriamente em outro, como rodovias com névoa ou trajetos noturnos. Coletar novos rótulos para cada condição é caro, por isso os pesquisadores procuram métodos que adaptem detectores usando apenas dados não rotulados do novo domínio.
Um sistema de auto‑ensino com um guia integrado
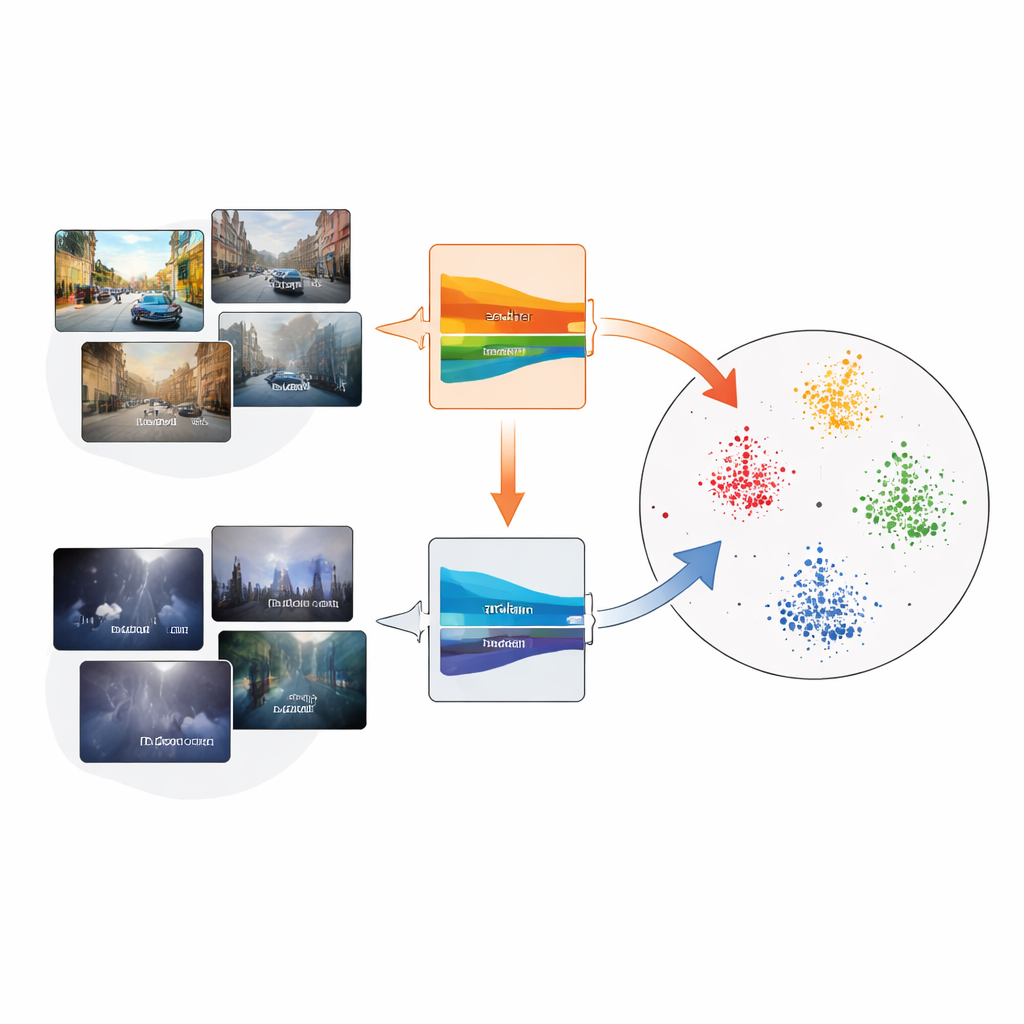
Uma estratégia popular permite que o modelo se ensine. Uma rede “professora”, construída como uma versão suavizada de uma rede “aluna”, prevê caixas em imagens alvo não rotuladas; essas previsões, chamadas pseudo‑rótulos, então treinam a aluna. Com o tempo, a aluna melhora e a professora é atualizada como uma média móvel dos pesos da aluna. No entanto, se os primeiros pseudo‑rótulos estiverem errados — por exemplo, perdendo objetos em névoa densa — os erros podem se acumular. Os autores mostram que três ideias podem ser combinadas para estabilizar esse auto‑treinamento: uma configuração mean‑teacher, aprendizado contrastivo (que aproxima características relacionadas e afasta as demais) e protótipos compactos que resumem cada categoria de objeto.
Protótipos como marcos no espaço de características
O núcleo do framework PoCoMT proposto é a Rede de Alinhamento por Protótipos, ou ProtoAN. Em vez de comparar cada objeto com todos os demais, o ProtoAN aprende um pequeno conjunto de pontos representativos — protótipos — para cada categoria, como carro ou pedestre. Características extraídas de regiões da imagem são mapeadas para um espaço especial onde exemplos da mesma categoria, vindos de domínios diferentes, se reúnem ao redor de seu protótipo compartilhado, enquanto categorias diferentes são afastadas. Uma perda contrastiva incentiva esse agrupamento, tanto dentro de um único domínio quanto entre domínios fonte e alvo. Crucialmente, esse mecanismo trata até mesmo o fundo como sua própria categoria, ajudando o sistema a distinguir objetos reais de ruído de cena.

Fazendo melhor uso de dados não rotulados
PoCoMT melhora os pseudo‑rótulos da professora de duas maneiras. Primeiro, um objetivo de “maximização de informação” empurra as previsões nas imagens alvo a serem ao mesmo tempo confiantes para cada objeto e diversas entre categorias, evitando o comportamento trivial de rotular tudo como a mesma classe. Segundo, o ProtoAN refina os pseudo‑rótulos comparando características com protótipos em vez de confiar apenas nas previsões brutas. Se a classe prevista para uma região não corresponder ao protótipo mais próximo, o rótulo pode ser ajustado. Isso torna o sistema mais tolerante ao ruído: mesmo quando os autores deliberadamente corromperam muitos pseudo‑rótulos durante o treinamento, o PoCoMT degradou de forma mais suave que métodos concorrentes.
Detectores mais robustos para cenários difíceis do mundo real
Avaliados em um amplo conjunto de benchmarks — incluindo ruas claras para com névoa, tráfego sintético para real, condução de dia para crepúsculo e imagens realistas para artísticas — o PoCoMT superou consistentemente técnicas existentes de adaptação de domínio não supervisionada, frequentemente por vários pontos percentuais na precisão de detecção. Em alguns casos, chegou até a superar modelos treinados diretamente com dados rotulados do domínio alvo, graças à sua capacidade de aproveitar tanto imagens fonte rotuladas quanto abundantes imagens alvo não rotuladas. Para não especialistas, a mensagem é direta: ao permitir que um detector de objetos organize seus próprios “marcos” internos para cada categoria e ao guiar com cuidado como professora e aluna trocam informações, essa abordagem torna sistemas de visão por IA mais robustos quando o mundo parece diferente dos dados de treinamento.
Citação: Cao, Q., Tao, J., Dan, Y. et al. Prototype-oriented contrastive mean-teacher for unsupervised domain adaptive object detection. Sci Rep 16, 10869 (2026). https://doi.org/10.1038/s41598-026-44991-7
Palavras-chave: adaptação de domínio não supervisionada, detecção de objetos, auto‑treinamento, aprendizado contrastivo, aprendizado por protótipos