Clear Sky Science · zh
基于改进扩展置信规则库的复杂系统轴承故障诊断方法
为何维持旋转机械健康至关重要
从风力涡轮机到工厂输送机,许多工业设备依赖长时间高速运转的滚动轴承和齿轮。当这些隐藏部件开始失效时,可能导致整条生产线停摆,甚至引发危险事故。本文提出了一种新的早期、可靠的故障识别方法,即便在现实世界中数据混乱、噪声多且偏向正常运行时,也能有效工作。
罕见故障与嘈杂信号带来的问题
在日常使用中,轴承和齿轮大多数时间是健康的,因此振动记录中正常样本远多于故障样本。标准的数据驱动方法(例如神经网络)虽能学习到复杂模式,但往往偏向多数类,容易忽视那些最关键的罕见故障特征。同时,振动传感器常置于机械与电气噪声充斥的恶劣环境中,这会模糊区分内圈损伤、外圈损伤或滚珠缺陷等不同故障类型所需的细节。这些问题共同导致在实验室外构建既准确又可信的诊断系统变得困难。
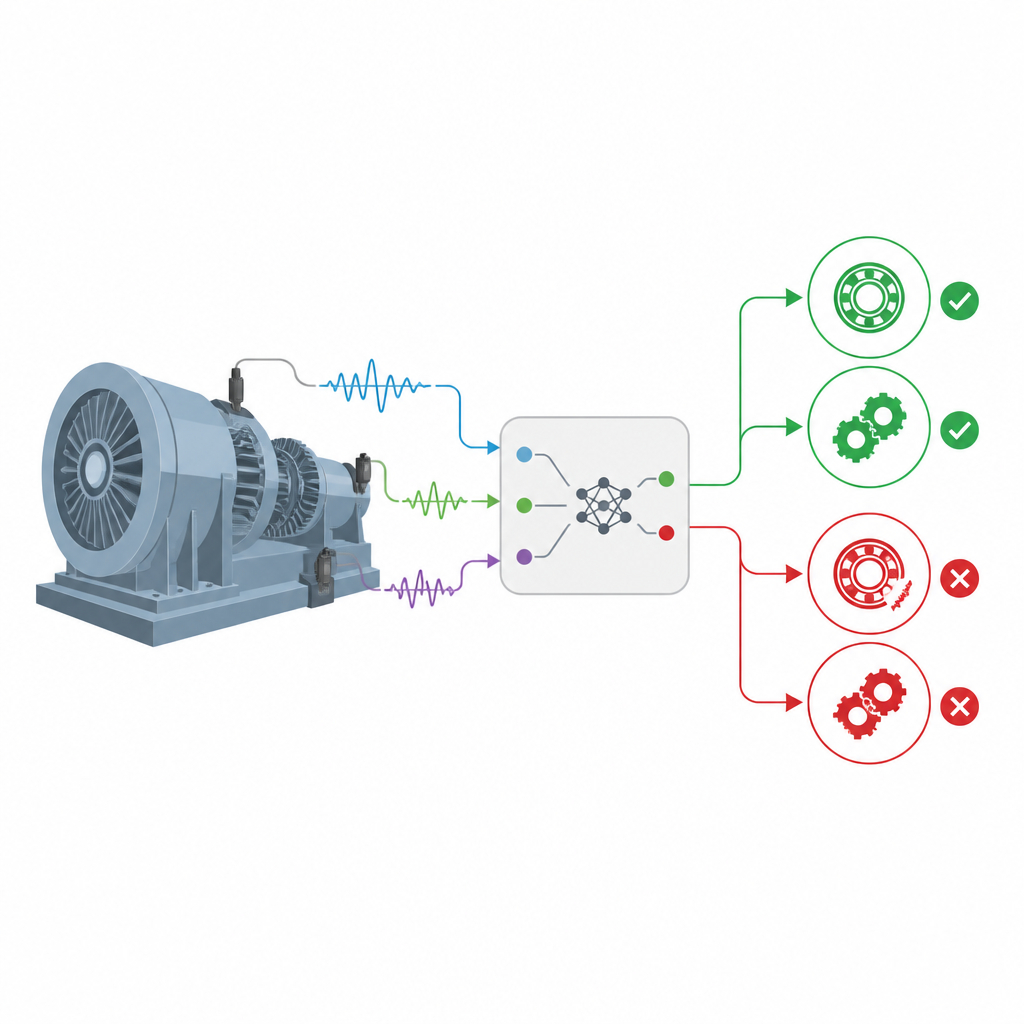
将专家规则与更精确的统计方法结合
作者基于一类称为置信规则库(belief rule base)的模型,这类模型将类似“若某些特征表现为该状态,则轴承处于该状态”的专家规则与表达不确定性的置信度结合在一起。扩展版本EBRB将原始传感器测量转为分级的置信水平(例如非常低、中等或非常高),而不是使用硬阈值,这使得应对模糊或不完整信息更为容易。然而,早期版本在判断新振动模式与存储规则匹配程度时,依赖简单的几何距离,这种方式在信号嘈杂时无法充分反映底层概率分布的差异。
测量信息而不是距离
为更好地捕捉振动模式的细微变化,论文用信息论工具——Kullback–Leibler(KL)散度取代了纯距离度量。该度量不是询问两点在空间上相距多远,而是问当用一种概率模式去近似另一种时,会损失多少信息。通过计算输入数据的置信分布与每条规则之间的对称KL散度,模型能够以关注概率质量如何分布而非仅仅其大小的方式来判断匹配程度。这在不同故障在整体强度相似但特征分布不同的情况下,能实现更精确的规则激活。
为罕见故障争取公平的表决权
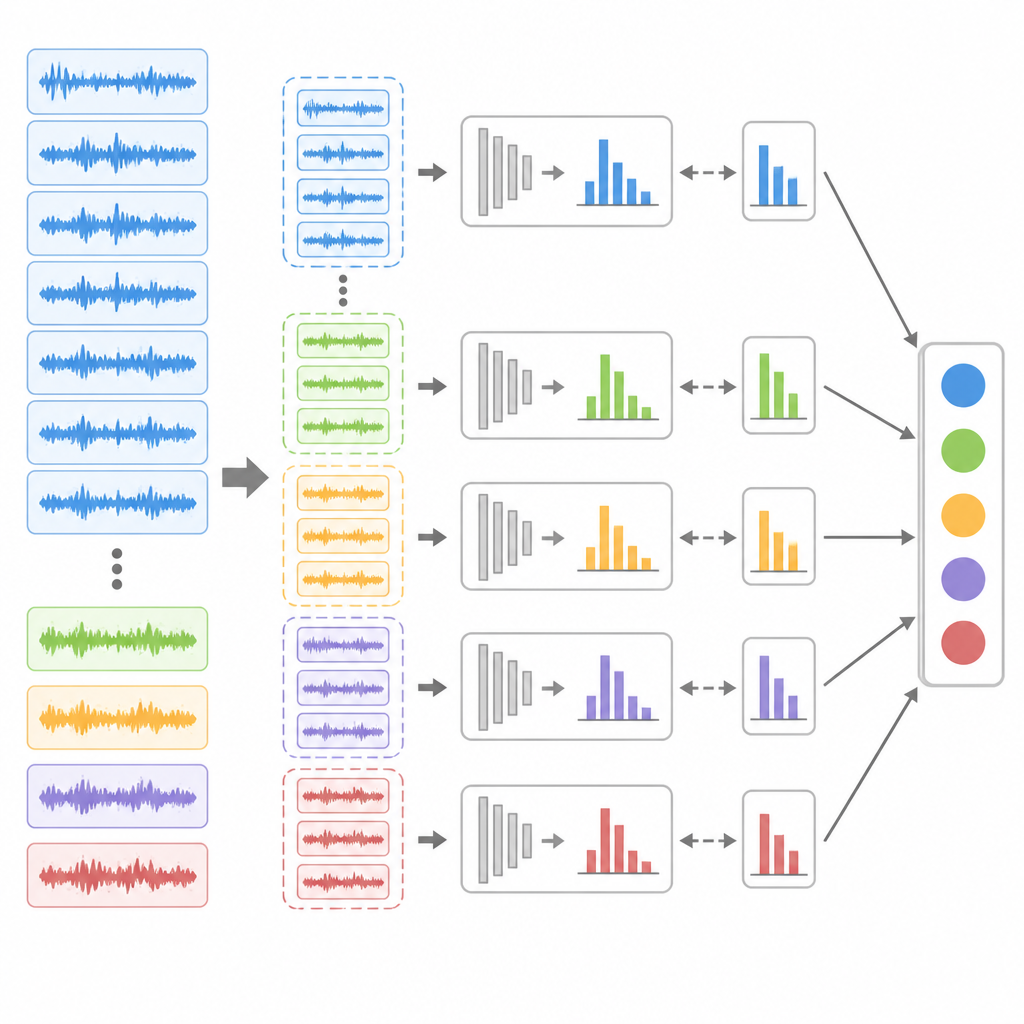
即便匹配更精确,不平衡的数据集仍可能使学习偏向多数的健康状态。为此,作者引入了一种集成欠采样策略:他们反复削减过多的健康样本,并将这些子集与全部可用的故障样本组合,生成若干平衡的训练子集。对每个子集训练一个独立的扩展置信规则模型,并使用差分进化算法(一种适合复杂优化空间的群体搜索方法)对内部权重进行微调。预测时,所有子模型都会分析同一条输入数据,最终由投票机制决定健康标签,从而为罕见故障模式提供多次被识别的机会。
该方法在实践中的性能如何
团队在两个广泛使用的基准数据集上测试了他们的方法:一个用于滚动轴承,一个用于齿轮。为模拟真实情况,他们在一种采样频率或工况下训练,在另一种下测试,同时在训练集与测试集中都保持强烈的类别不平衡。在准确率、精确率、召回率和F1分数等多项指标上,该方法持续优于传统的置信规则系统、常见的机器学习模型和流行的不平衡处理技术。尤其是在少数故障类上提升显著,即使在向关键信号特征加入人工噪声时也能保持高性能。
对真实机器的意义
对非专业读者而言,关键信息是:在现实工厂中该方法能为轴承和齿轮提供更可靠的“健康检查”。通过把专家式规则与更智能的概率模式比较方法以及对罕见事件公平的投票系统结合起来,该方法降低了早期损伤迹象被大量正常数据和背景噪声淹没的风险。作者总结认为,他们的集成置信规则库可以提供准确、可解释且抗噪的故障诊断,并建议将其扩展到其他旋转部件,同时自动化确定最佳数据子集数量以获得最佳性能。
引用: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
关键词: 轴承故障诊断, 齿轮故障诊断, 振动监测, 集成学习, 置信规则库