Clear Sky Science · de
Eine Methode zur Lagerfehlersuche in komplexen Systemen basierend auf einer verbesserten erweiterten Belief-Rule-Base
Warum es wichtig ist, rotierende Maschinen gesund zu halten
Von Windturbinen bis zu Förderbändern in Fabriken verlassen sich viele Industriemaschinen über Jahre hinweg auf Wälzlager und Zahnräder, die mit hoher Geschwindigkeit drehen. Wenn diese verborgenen Teile zu versagen beginnen, können ganze Produktionslinien stillstehen oder sogar gefährliche Unfälle ausgelöst werden. Dieser Beitrag stellt eine neue Methode vor, um solche Fehler früh und zuverlässig zu erkennen – selbst wenn reale Daten unordentlich, verrauscht und stark zugunsten eines Normalbetriebs verzerrt sind.
Das Problem seltener Fehler und verrauschter Signale
Im Alltag sind Lager und Zahnräder meist intakt, sodass Vibrationsaufzeichnungen deutlich mehr normale Beispiele als fehlerhafte enthalten. Standard datengetriebene Methoden wie neuronale Netze können beeindruckende Muster lernen, fokussieren sich aber oft auf die Mehrheitsklasse und übersehen häufig die seltenen Fehlersignaturen, die am wichtigsten sind. Gleichzeitig sitzen Vibrationssensoren in rauer Umgebung mit mechanischem und elektrischem Rauschen, das die feinen Details verwischt, die nötig sind, um verschiedene Fehlertypen wie Innenring-, Außenring- oder Kugelschäden zu unterscheiden. Zusammen erschweren diese Probleme den Aufbau von Diagnosesystemen, die sowohl außerhalb des Labors genau als auch vertrauenswürdig sind.
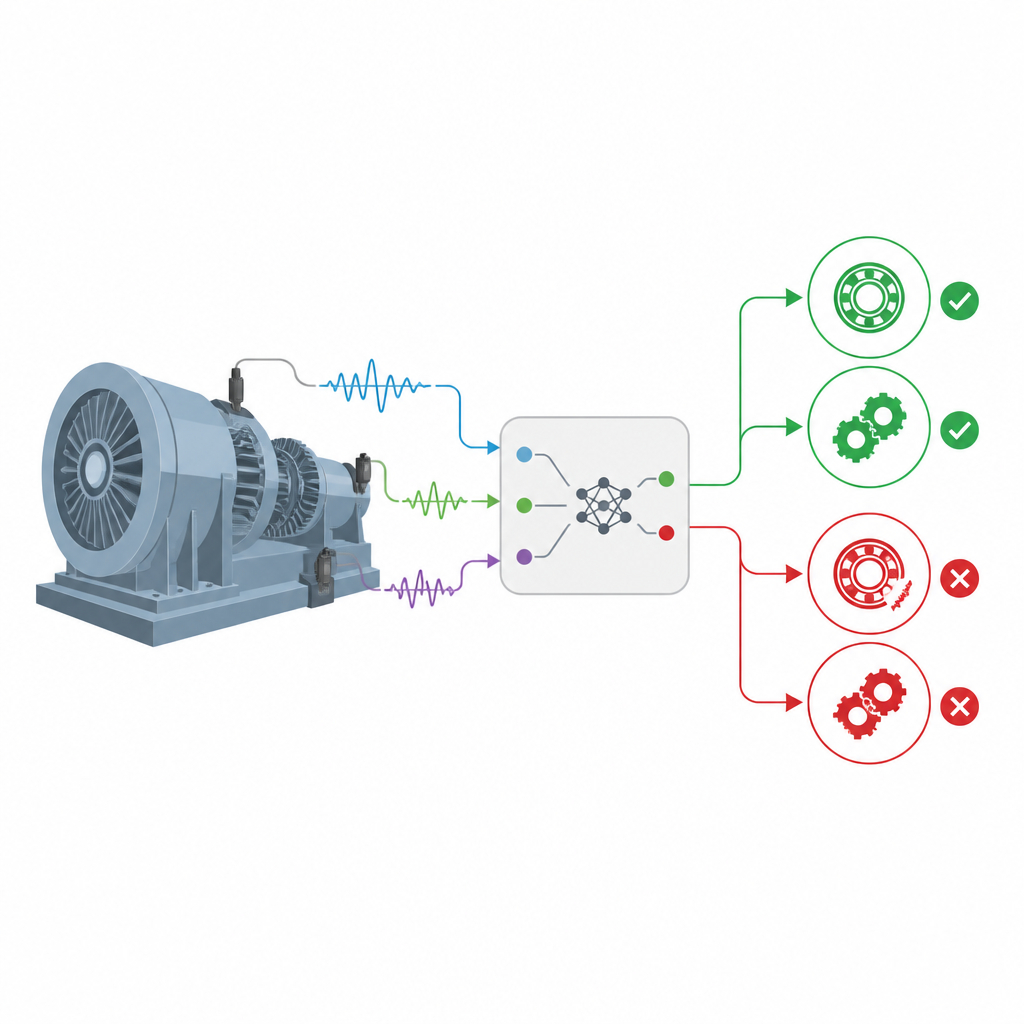
Expertenregeln mit klügerer Statistik verbinden
Die Autorinnen und Autoren bauen auf einer Modellfamilie auf, die als Belief-Rule-Base bekannt ist und Expertenregeln der Form „WENN bestimmte Merkmale so aussehen, DANN befindet sich das Lager in diesem Zustand“ mit Wahrscheinlichkeitsaussagen zur Unsicherheit kombiniert. Eine erweiterte Version dieses Rahmens, EBRB genannt, wandelt rohe Sensormessungen in abgestufte Glaubenslevel (zum Beispiel sehr niedrig, mittel oder sehr hoch) statt in harte Schwellen um. Das erleichtert den Umgang mit vagen oder unvollständigen Informationen. Frühere Versionen beruhten jedoch auf einfacher geometrischer Distanz, um zu entscheiden, wie gut ein neues Vibrationsmuster mit einer gespeicherten Regel übereinstimmt – eine Wahl, die bei verrauschten Signalen Unterschiede in den zugrundeliegenden Wahrscheinlichkeitsverteilungen nicht vollständig widerspiegelt.
Information messen statt Abstand
Um subtile Veränderungen in Vibrationsmustern besser zu erfassen, ersetzt das Papier die einfache Distanz durch ein Werkzeug der Informationstheorie: die Kullback–Leibler-Divergenz. Anstatt zu fragen, wie weit zwei Punkte im Raum auseinanderliegen, fragt dieses Maß, wie viel Information verloren geht, wenn ein Wahrscheinlichkeitsmuster zur Nachahmung eines anderen verwendet wird. Durch die Berechnung einer symmetrischen Version dieser Divergenz zwischen den Glaubensprofilen eintreffender Daten und jeder Regel kann das Modell Übereinstimmungen so bewerten, dass die Anordnung der Wahrscheinlichkeitsmasse berücksichtigt wird, nicht nur deren Größe. Das führt zu präziseren Regelaktivierungen, insbesondere wenn unterschiedliche Fehler in ihrer Gesamtausprägung ähnlich erscheinen, sich aber in der Verteilung ihrer Merkmale unterscheiden.
Seltenen Fehlern eine faire Stimme geben
Selbst mit besserer Zuordnung kann ein unausgewogenes Datenset das Lernen zugunsten des überwiegenden gesunden Zustands verzerren. Zur Gegensteuerung führen die Autorinnen und Autoren eine Ensemble-Undersampling-Strategie ein. Sie reduzieren wiederholt die zahlreich vorhandenen gesunden Stichproben und kombinieren diese mit allen verfügbaren Fehlermustern, um mehrere ausgeglichene Trainingsuntergruppen zu erstellen. Für jede Untergruppe trainieren sie ein separates erweitertes Belief-Rule-Modell und stimmen dessen interne Gewichte anschließend mit einem Differential-Evolution-Algorithmus fein ab – einer populationsbasierten Suchmethode, die für komplexe Landschaften geeignet ist. Zur Vorhersage analysieren alle diese Submodelle dieselben eingehenden Daten, und ein Abstimmungsschema entscheidet das finale Gesundheitslabel, wodurch seltenen Fehlermustern mehrfach die Chance zur Erkennung gegeben wird.
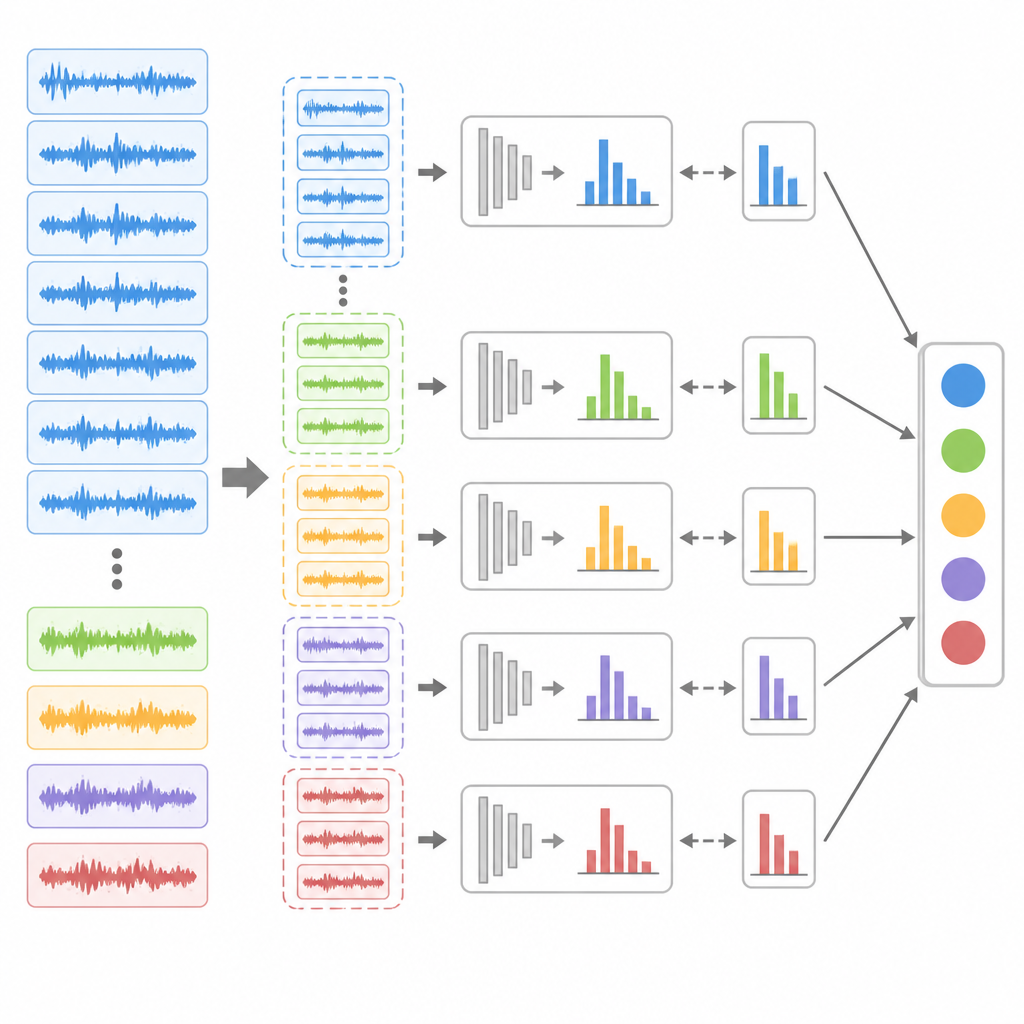
Wie gut die Methode in der Praxis funktioniert
Das Team testet seinen Ansatz an zwei weit verbreiteten Benchmark-Datensätzen: einem für Wälzlager und einem für Zahnräder. Um realistische Bedingungen zu simulieren, trainieren sie mit Vibrationsdaten, die unter einer Abtastrate oder Betriebsbedingung aufgezeichnet wurden, und testen mit Daten, die unter einer anderen Bedingung aufgenommen wurden, wobei in beiden Sätzen eine starke Klassenungleichheit beibehalten wird. Über eine Reihe von Metriken wie Genauigkeit, Präzision, Recall und F1-Score hinweg übertrifft die neue Methode konsistent traditionelle Belief-Rule-Systeme, Standard-Modelle des maschinellen Lernens und verbreitete Techniken zum Umgang mit Ungleichgewicht. Besonders große Verbesserungen zeigt sie bei den Minderheitsfehlerklassen und erzielt hohe Leistungen selbst dann, wenn künstliches Rauschen zu wichtigen Signalmerkmalen hinzugefügt wird.
Was das für reale Maschinen bedeutet
Für Nicht-Spezialistinnen und -Spezialisten lautet die Kernaussage, dass diese Methode Lager und Zahnräder unter den unordentlichen Bedingungen in realen Betrieben eine zuverlässigere „Gesundheitsprüfung“ bietet. Durch die Kombination von expertenähnlichen Regeln mit einer klügeren Art, Wahrscheinlichkeitsmuster zu vergleichen, und einem fairen Abstimmungssystem für seltene Ereignisse verringert der Ansatz das Risiko, dass frühe Schadensanzeichen im Strom normaler Daten und Hintergrundrauschen untergehen. Die Autorinnen und Autoren schließen, dass ihr Ensemble-Belief-Rule-Base genaue, interpretierbare und rauschresistente Fehlerdiagnosen liefern kann, und schlagen vor, den Ansatz auf andere rotierende Teile zu erweitern und die Anzahl der benötigten Datenuntergruppen automatisch zu bestimmen, um die beste Leistung zu erzielen.
Zitation: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Schlüsselwörter: Lagerfehlersuche, Zahnradfehlersuche, Vibrationsüberwachung, Ensemble-Lernen, Belief-Rule-Base