Clear Sky Science · nl
Een methode voor lagerfoutdiagnose in complexe systemen gebaseerd op verbeterde uitgebreide belief rule base
Waarom het belangrijk is dat roterende machines gezond blijven
Van windturbines tot fabriekstransportbanden: veel industriële machines vertrouwen op rollagers en tandwielen die jarenlang met hoge snelheid draaien. Wanneer deze verborgen onderdelen beginnen te falen, kunnen ze hele productielijnen stilleggen of zelfs gevaarlijke ongevallen veroorzaken. Dit artikel presenteert een nieuwe manier om dergelijke fouten vroeg en betrouwbaar te detecteren, zelfs wanneer praktijkdata rommelig, luidruchtig en sterk vertekend naar normale bedrijfsomstandigheden zijn.
Het probleem van zeldzame fouten en rumoerige signalen
In dagelijks gebruik zijn lagers en tandwielen meestal in goede staat, waardoor vibratieregistraties veel meer normale voorbeelden dan foutieve bevatten. Standaard data‑gedreven methoden, zoals neurale netwerken, kunnen indrukwekkende patronen leren maar richten zich vaak op de meerderheidsklasse en missen daardoor de zeldzame foutsignaturen die het belangrijkst zijn. Tegelijkertijd staan vibratiesensoren in ruwe omgevingen vol mechanische en elektrische ruis, wat de fijne details vervaagt die nodig zijn om verschillende fouttypes te onderscheiden, zoals binnenringbeschadiging, buitenringbeschadiging of kogeldefecten. Samen maken deze problemen het moeilijk om diagnostische systemen te bouwen die zowel nauwkeurig als betrouwbaar zijn buiten het laboratorium.
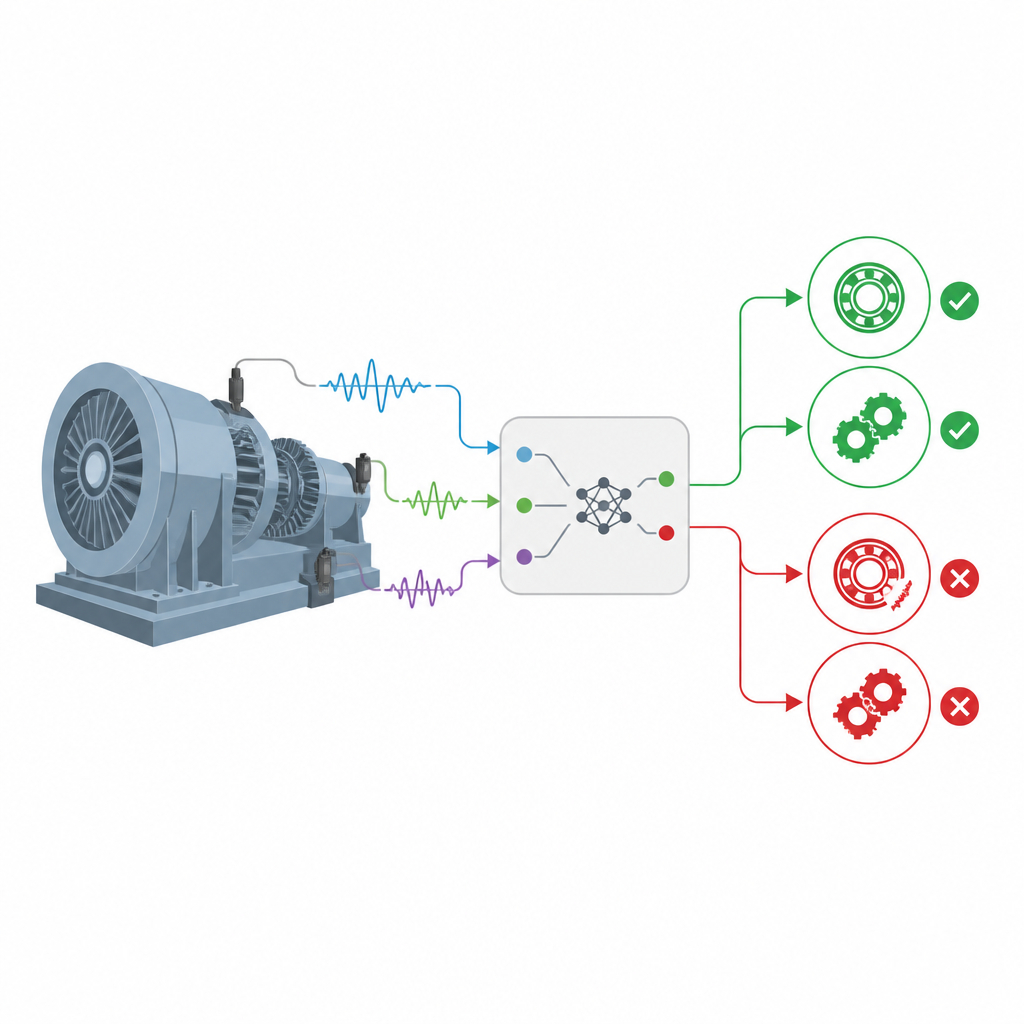
Expertregels mengen met slimere statistiek
De auteurs bouwen voort op een modelfamilie die bekendstaat als belief rule bases, die deskundige regels van de vorm "ALS bepaalde kenmerken er zo uitzien, DAN bevindt het lager zich in die toestand" combineren met waarschijnlijkheden die onzekerheid uitdrukken. Een uitgebreide versie van dit kader, EBRB genoemd, zet ruwe sensormetingen om in gegroepeerde belief-niveaus (bijvoorbeeld zeer laag, gemiddeld of zeer hoog) in plaats van harde drempels. Dat maakt het makkelijker om met vage of onvolledige informatie om te gaan. Eerdere versies vertrouwden echter op eenvoudige geometrische afstand om te bepalen hoe goed een nieuw vibratiepatroon overeenkomt met een opgeslagen regel, een keuze die de verschillen in onderliggende waarschijnlijkheidsverdelingen bij rumoerige signalen niet volledig weerspiegelt.
Informatie meten in plaats van afstand
Om subtiele veranderingen in vibratiepatronen beter vast te leggen, vervangt het artikel gewone afstand door een instrument uit de informatietheorie: Kullback–Leibler-divergentie. In plaats van te vragen hoe ver twee punten in de ruimte van elkaar liggen, vraagt deze maat hoeveel informatie verloren gaat wanneer het ene waarschijnlijkheidspatroon wordt gebruikt om het andere te benaderen. Door een symmetrische versie van deze divergentie te berekenen tussen de belief‑profielen van binnenkomende data en elke regel, kan het model overeenkomsten beoordelen op een manier die kijkt naar hoe de waarschijnlijkheidsmassa is verdeeld, niet alleen naar de grootte ervan. Dit leidt tot preciezere activering van regels, vooral wanneer verschillende fouten qua algemene sterkte op elkaar lijken maar verschillen in de verdeling van hun kenmerken.
Zeldzame fouten een eerlijke kans geven
Zelfs met betere matching kan een ongebalanceerde dataset het leren nog steeds naar de meerderheidsklasse — gezonde toestanden — trekken. Om dit tegen te gaan introduceren de auteurs een ensemble‑undersamplingstrategie. Ze snoeien herhaaldelijk het overvloedige gezonde materiaal terug en combineren dat met alle beschikbare foutvoorbeelden om meerdere gebalanceerde trainingssubsets te maken. Voor elke subset trainen ze een apart uitgebreid belief‑rulemodel en tunen vervolgens de interne gewichten met een differentiële evolutie‑algoritme, een populatiegebaseerde zoekmethode die goed past bij complexe optimaliseringslandschappen. Bij voorspellingen analyseren al deze submodellen dezelfde binnenkomende data en een stemschema bepaalt het eindlabel voor de gezondheid, waardoor zeldzame foutpatronen meerdere kansen krijgen om herkend te worden.
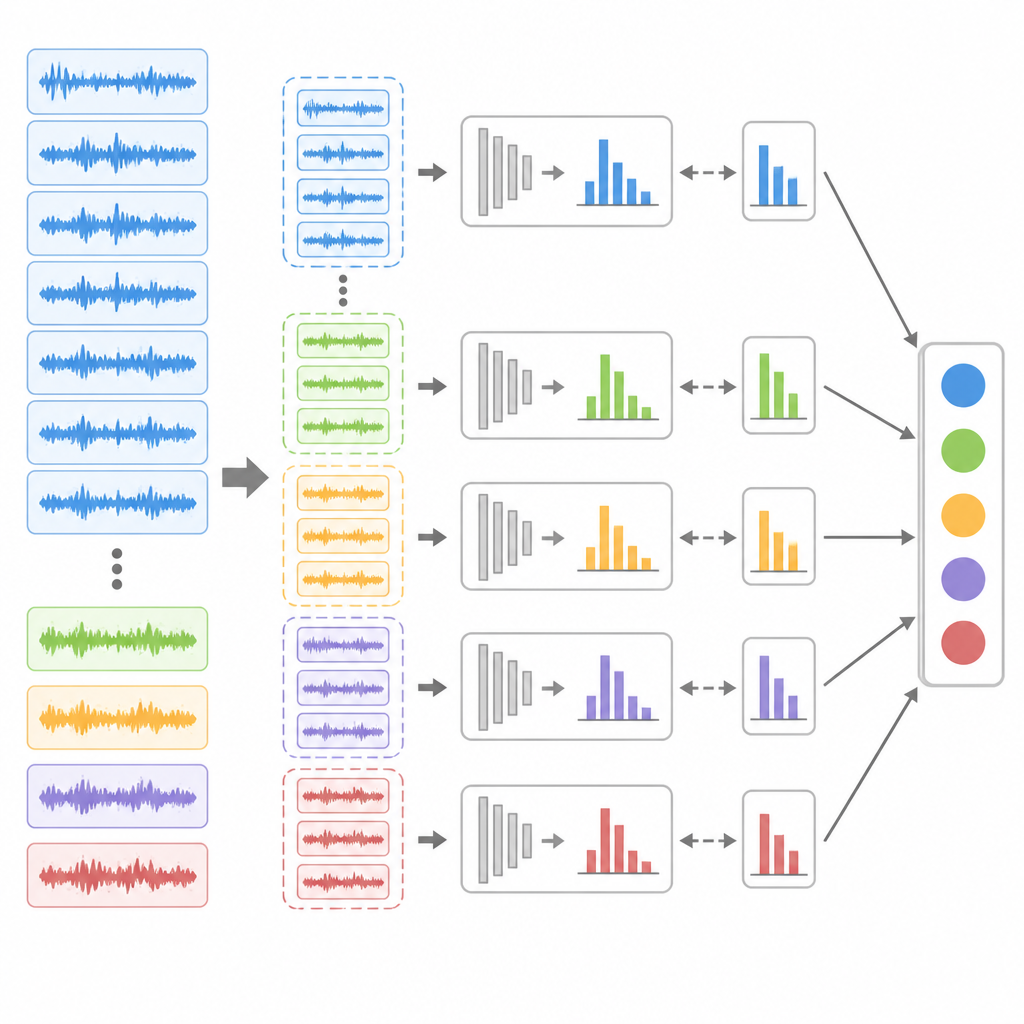
Hoe goed de methode in de praktijk werkt
Het team test hun aanpak op twee veelgebruikte benchmarkdatasets: één voor rollagers en één voor tandwielen. Om realistische omstandigheden na te bootsen trainen ze op vibratiegegevens opgenomen onder één bemonsteringsfrequentie of bedrijfsconditie en testen ze op data die onder een andere conditie zijn genomen, waarbij in beide sets sterke klasse‑imbalans behouden blijft. Over een reeks maatstaven zoals nauwkeurigheid, precision, recall en F1‑score overtreft de nieuwe methode consistent traditionele belief‑rule‑systemen, standaard machine‑learningmodellen en gangbare technieken voor het omgaan met ongebalanceerde data. De grootste winst wordt gezien bij de minderheidsfoutklassen, en de methode behoudt hoge prestaties zelfs wanneer kunstmatige ruis aan sleutelkenmerken wordt toegevoegd.
Wat dit betekent voor echte machines
Voor niet‑specialisten is de kernboodschap dat deze methode lagers en tandwielen een betrouwbaardere "gezondheidscontrole" biedt onder de rommelige omstandigheden die in echte fabrieken voorkomen. Door deskundige regels te combineren met een slimere manier om waarschijnlijkheidspatronen te vergelijken en een eerlijk stemsysteem voor zeldzame gebeurtenissen, vermindert de aanpak het risico dat vroege schadeverschijnselen worden overstemd door de stroom van normale data en achtergrondruis. De auteurs concluderen dat hun ensemble belief rule base accurate, interpreteerbare en ruisbestendige foutdiagnose kan bieden en stellen voor om het uit te breiden naar andere roterende onderdelen en het aantal benodigde datasets voor optimale prestaties te automatiseren.
Bronvermelding: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Trefwoorden: lagerfoutdiagnose, tandwielfoutdiagnose, vibratiemonitoring, ensemble learning, belief rule base