Clear Sky Science · sv
En metod för diagnos av lagerfel i komplexa system baserad på förbättrad utökad belief rule base
Varför det är viktigt att hålla roterande maskiner friska
Från vindkraftverk till fabriksband förlitar sig många industrimaskiner på rullager och kugghjul som snurrar med hög hastighet år efter år. När dessa dolda delar börjar gå sönder kan de stoppa hela produktionslinjer eller till och med orsaka farliga olyckor. Denna artikel presenterar ett nytt sätt att upptäcka sådana fel tidigt och pålitligt, även när verkliga data är röriga, brusiga och kraftigt snedfördelade mot normal drift.
Problemet med sällsynta fel och brusiga signaler
I vardagsanvändning är lager och kugghjul oftast friska, så vibrationsinspelningar innehåller många fler normala exempel än felaktiga. Standardmetoder baserade på data, såsom neurala nätverk, kan lära sig imponerande mönster men tenderar att fokusera på majoritetsklassen och förbiser ofta de sällsynta felsignaturerna som är viktigast. Samtidigt sitter vibrationssensorer i hårda miljöer fyllda med mekaniskt och elektriskt brus, vilket suddar ut de fina detaljer som behövs för att skilja mellan olika feltyper som innerspårs‑, yttersparrs‑ eller kuldefekter. Tillsammans gör dessa problem det svårt att bygga diagnossystem som både är precisa och trovärdiga utanför laboratoriet.
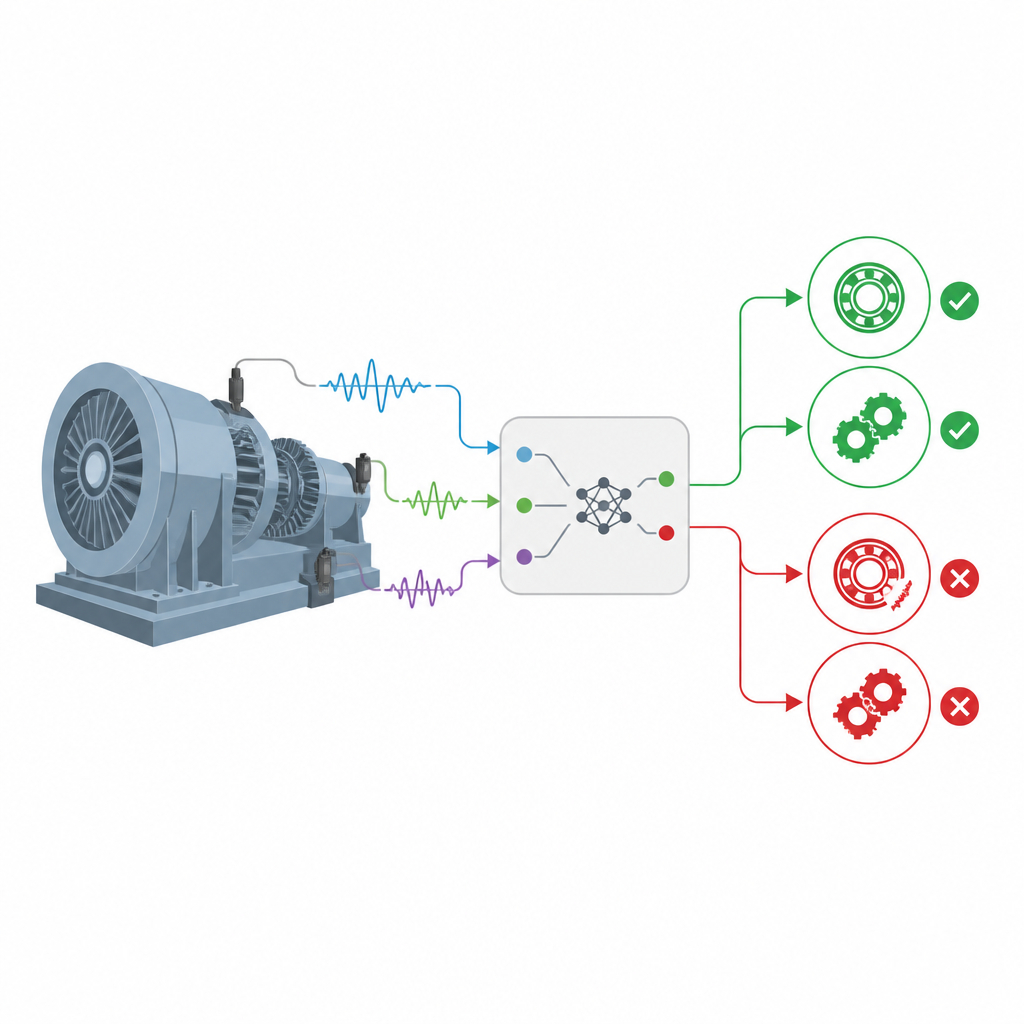
Att blanda expertregler med smartare statistik
Författarna bygger vidare på en familj modeller kända som belief rule bases, som kombinerar expertregler av formen "OM vissa egenskaper ser ut så här, SÅ är lagret i det tillståndet" med sannolikheter som uttrycker osäkerhet. En utökad version av detta ramverk, kallad EBRB, omvandlar råa sensormätningar till graderade trossnivåer (till exempel mycket låg, medel eller mycket hög) istället för hårda trösklar. Det gör det enklare att hantera vaga eller ofullständiga uppgifter. Tidigare versioner förlitade sig dock på enkel geometrisk distans för att avgöra hur väl ett nytt vibrationsmönster matchar en lagrad regel, ett val som inte fullt ut speglar skillnader i underliggande sannolikhetsfördelningar när signalerna är brusiga.
Mäta information i stället för avstånd
För att bättre fånga subtila förändringar i vibrationsmönster ersätter artikeln enkel distans med ett verktyg från informationsteorin kallat Kullback–Leibler‑divergens. I stället för att fråga hur långt två punkter är i ett rum frågar denna mått hur mycket information som går förlorad när ett sannolikhetsmönster används för att efterlikna ett annat. Genom att beräkna en symmetrisk version av denna divergens mellan trossprofilerna för inkommande data och varje regel kan modellen bedöma matchningar på ett sätt som uppmärksammar hur sannolikhetsmassan är fördelad, inte bara dess storlek. Detta leder till mer precisa regelaktiveringar, särskilt när olika fel liknar varandra i övergripande styrka men skiljer sig i fördelningen av sina egenskaper.
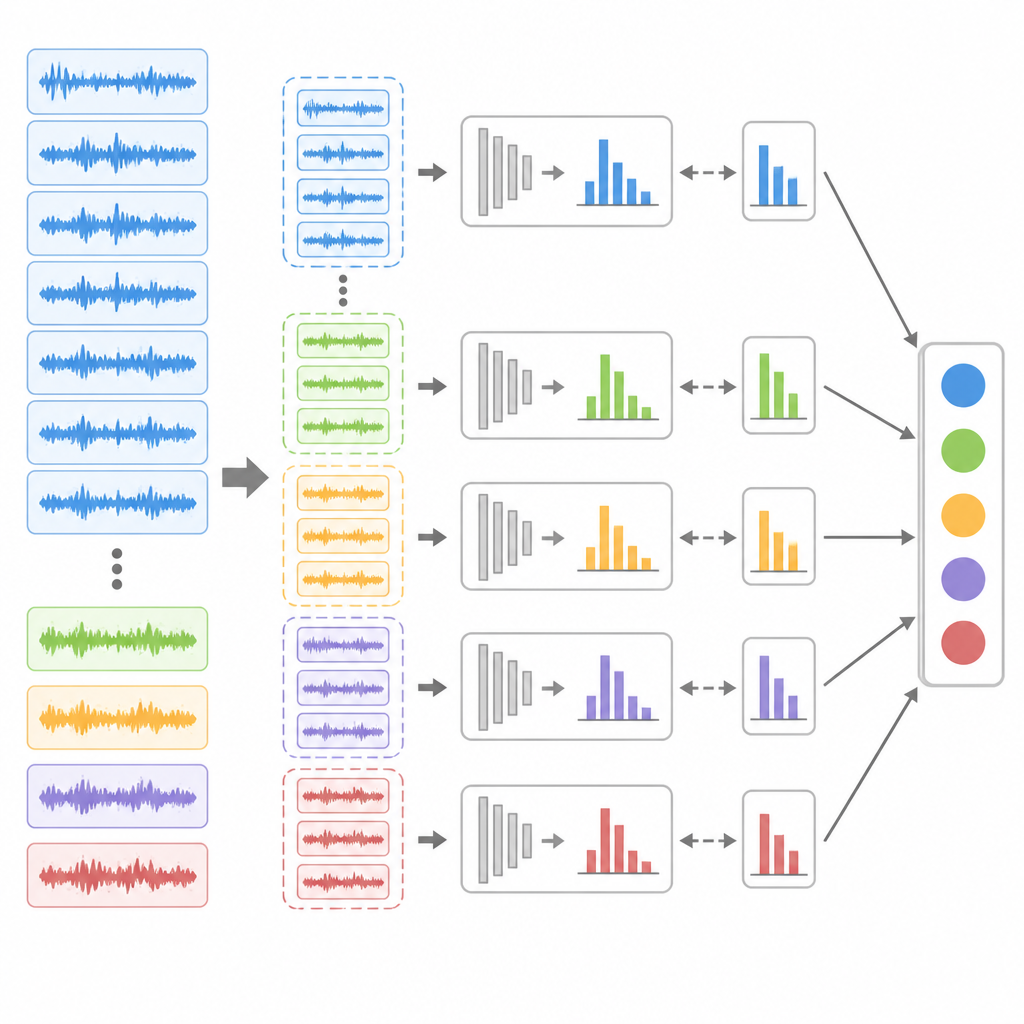
Ge sällsynta fel en rättvis röst
Även med bättre matchning kan ett obalanserat dataset fortfarande snedvrida inlärningen mot majoriteten friska tillstånd. För att motverka detta introducerar författarna en ensemble‑undersamplingsstrategi. De minskar upprepade gånger antalet överrepresenterade friska prover och kombinerar dem med alla tillgängliga felprover för att skapa flera balanserade träningsdelmängder. För varje delmängd tränar de en separat utökad belief rule‑modell och finjusterar sedan dess interna vikter med en differential evolution‑algoritm, en populationsbaserad sökmetod som lämpar sig väl för komplexa landskap. Vid prediktion analyserar alla dessa undermodeller samma inkommande data, och ett röstningsschema avgör slutlig hälsomärkning, vilket ger sällsynta felsignaler flera chanser att kännas igen.
Hur väl metoden fungerar i praktiken
Teamet testar sitt tillvägagångssätt på två vida använda referensdataset: ett för rullager och ett för kugghjul. För att efterlikna realistiska förhållanden tränar de på vibrationsdata inspelade under en provtagningsfrekvens eller driftförhållande och testar på data tagna under ett annat, samtidigt som stark klassobalans bevaras i båda uppsättningarna. Över en rad mått som noggrannhet, precision, återkallelse och F1‑poäng överträffar den nya metoden konsekvent traditionella belief rule‑system, standardmaskininlärningsmodeller och populära tekniker för hantering av obalans. Den visar särskilt starka förbättringar för minoritetsfelklasserna och bibehåller hög prestanda även när artificiellt brus läggs till centrala signalfeature.
Vad detta betyder för verkliga maskiner
För en icke‑specialist är huvudbudskapet att denna metod ger lager och kugghjul en mer pålitlig "hälsokoll" under de röriga förhållanden som finns i verkliga anläggningar. Genom att kombinera expertliknande regler med ett smartare sätt att jämföra sannolikhetsmönster och ett rättvist röstsystem för sällsynta händelser minskar angreppssättet risken att tidiga skador drunknar i floden av normala data och bakgrundsbrus. Författarna drar slutsatsen att deras ensemble belief rule base kan ge noggrann, tolkbar och brusresistent felidentifiering, och de föreslår att den kan utvidgas till andra roterande delar samtidigt som man automatiserar hur många datadelmängder som behövs för bästa prestanda.
Citering: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Nyckelord: diagnostik av lagerfel, diagnostik av drevfel, vibrationsövervakning, ensembleinlärning, belief rule base